 如何设计更智能的Edge AI
如何设计更智能的Edge AI

作为一名拥有 40 多年半导体业务研发总监和 CMO 经验的工程师,我认为我自己和我的同行是合乎逻辑的。然而,我们当中有多少人可以诚实地说我们没有被诸如“我的小部件比你的快?”这样的说法所诱惑。恐怕这只是人性,尤其是当我们对你的专业知识没有信心来调查这些说法时。
问题始终是一个定义:我如何定义“更快”或“更低功率”或“更便宜”?这是基准试图解决的问题——它是关于具有一致的上下文和外部标准,以确保您将同类与同类进行比较。任何使用基准测试的人都非常清楚这一点(aiMotive 诞生于一家领先的 GPU 基准测试公司)。
在尝试比较汽车 AI 应用的硬件平台时,解决这种轰炸式索赔的需求从未像现在这样紧迫。
10 TOPS 什么时候不是 10 TOPS?
无论是否有专用的 NPU,大多数 SoC 都将其执行 NN 工作负载的能力称为 TOPS:每秒 Tera 操作。这只是 NPU(或整个 SoC)原则上每秒可以执行的算术运算总数,无论全部集中在专用 NPU 中还是分布在多个计算引擎中,例如 GPU、CPU 矢量协处理器、或其他加速器。
但是,没有任何硬件执行引擎能以 100% 的效率执行任何工作负载的各个方面。对于神经网络推理,某些层(例如池化或激活)在数学上与卷积非常不同。在卷积本身(或其他层,如池化)可以开始之前,数据必须重新排列或从一个地方移动到另一个地方。其他时候,NPU 可能需要等待来自控制它的主机 CPU 的新指令或数据,每个层甚至每个数据块。这些都导致完成的计算更少,从而限制了理论上的最大容量。
硬件利用率——不是它看起来的样子
许多 NPU 供应商会引用硬件利用率来表明他们的 NPU 执行给定 NN 工作负载的情况。这基本上是说,“这就是我的 NPU 的理论容量有多少被用于执行 NN 工作负载。” 当然,这告诉我我需要知道什么。
不幸的是没有。硬件利用率的问题是定义之一:数量完全取决于 NPU 供应商选择如何定义它。事实上,硬件利用率和 TOPS 的问题在于它们只告诉你硬件引擎理论上能够实现什么,而不是它实现的程度。
这可能会导致一些误导性信息。下面的图 1 显示了我们在额定 4 TOPS 的 aiWare3P NPU 与另一个额定为 8 TOPS 的知名 NPU 之间进行的比较。
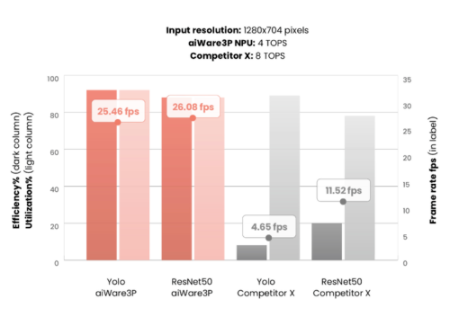
图 1:两个汽车推理 NPU 的利用率与效率比较
对于两个不同的知名基准,竞争对手 X NPU 声称 8 TOPS 容量,而 aiWare3P 的 4 TOPS。这应该意味着它将提供大约 2 倍于 aiWare3P 的 fps 性能。然而,实际上,情况正好相反:aiWare3P 的性能提高了 2 到 5 倍,尽管它只是声称的 TOPS 的一半!
结论:TOPS 是衡量 AI 硬件能力的一种非常糟糕的方法;硬件利用率几乎与 TOPS 一样具有误导性。
NPU 效率和自主性:优化 PPA 的关键
这就是为什么我认为您必须根据执行一组代表性工作负载时的效率而不是原始理论硬件容量来评估 NPU 能力。效率定义为为一帧执行特定 CNN 需要多少操作,占声称的 TOPS 总数的百分比。该数字仅基于定义任何 CNN 的基础数学算法计算得出,无论 NPU 实际如何评估它。它比较了实际与声称的性能,这才是真正重要的。
展示出高效率的 NPU 意味着它将充分利用用于实现它的每平方毫米硅片,这意味着更低的芯片成本和更低的功耗。效率可为汽车 SoC 或 ASIC 提供最佳 PPA(性能、功率和面积)。
NPU 的自治性是另一个重要因素。NPU 在主机 CPU 上放置多少 CPU 负载才能达到最高性能?这与内存子系统有什么关系?NPU 必须被视为任何 SoC 或 ASIC 中的大块——它对芯片和子系统其余部分的影响不容忽视。
结论
在设计任何 SoC 或 ASIC 汽车时,AI 工程师必须专注于构建能够可靠执行其算法的生产平台,同时实现卓越的 PPA:最低功耗、最低成本、更高性能。他们还必须在设计周期的早期就选择硬件平台,通常是在开发最终算法之前。
效率是实现这一目标的最佳方式;TOPS 和硬件利用率都不是好的衡量标准。如果要满足苛刻的生产目标,评估 NPU 的自主性也至关重要。
审核编辑:郭婷
-
cpu
+关注
关注
68文章
11327浏览量
225878 -
soc
+关注
关注
40文章
4624浏览量
230170 -
AI
+关注
关注
91文章
41101浏览量
302579
发布评论请先 登录
MathWorks携手EDGE AI Foundation:重塑嵌入式AI工程化落地新范式
MathWorks 加入 EDGE AI FOUNDATION,推进面向工程化系统的嵌入式 AI 发展
使用NORDIC AI的好处
IBM Rhapsody AI 助手:让系统工程更智能

联想集团想帮帮服务智能体荣膺2025 EDGE AWARDS最佳AI创新应用
探索PSOC Edge E84 AI Kit:开启下一代机器学习边缘设备设计之旅
天数智算AI+HOME解决方案:重构家庭智能生态,让家更懂你

英飞凌推出专为PSOC Edge微控制器优化的DEEPCRAFT AI套件
AI赋能6G与卫星通信:开启智能天网新时代
【今晚7点半】正点原子 x STM32:智能加速边缘AI应用开发!今晚正点原子B站直播间等你
最新人工智能硬件培训AI基础入门学习课程参考2025版(离线AI语音视觉识别篇)
2.0.0版本的ST Edge AI Core在linux平台上可以把量化后的onnx模型转换为.nb,但是运行报错,缺少文件,为什么?
AMD第二代Versal AI Edge和Versal Prime系列加速量产 为嵌入式系统实现单芯片智能
2025研华嵌入式设计论坛上海站:聚焦Edge Computing &amp; Edge AI,共探技术创新与生态融合




评论