 如何在Prompt Learning下引入外部知识达到好文本分类效果
如何在Prompt Learning下引入外部知识达到好文本分类效果

背景
利用Prompt Learning(提示学习)进行文本分类任务是一种新兴的利用预训练语言模型的方式。在提示学习中,我们需要一个标签词映射(verbalizer),将[MASK]位置上对于词表中词汇的预测转化成分类标签。例如{POLITICS: "politics", SPORTS: "sports"} 这个映射下,预训练模型在[MASK]位置对于politics/sports这个标签词的预测分数会被当成是对POLITICS/SPORTS这个标签的预测分数。
手工定义或自动搜索得到的verbalizer有主观性强覆盖面小等缺点,我们使用了知识库来进行标签词的扩展和改善,取得了更好的文本分类效果。同时也为如何在Prompt Learning下引入外部知识提供了参考。
方法
我们提出使用知识库扩展标签词,通过例如相关词词表,情感词典等工具,基于手工定义的初始标签词进行扩展。例如,可以将{POLITICS: "politics", SPORTS: "sports"} 扩展为以下的一些词:
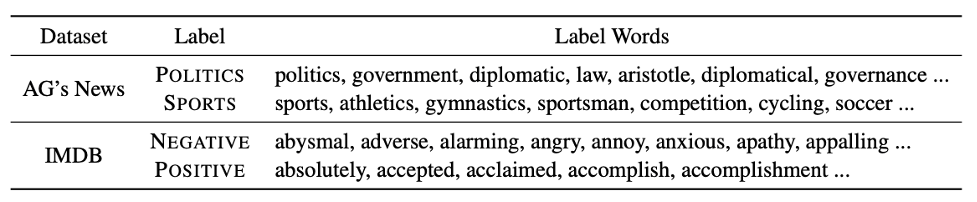
表1: 基于知识库扩展出的标签词。
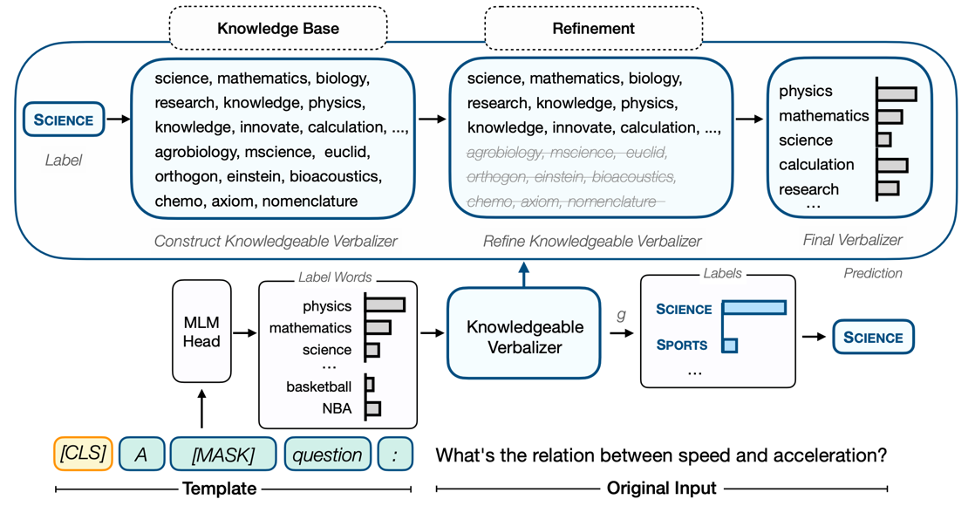
图1: 以问题分类任务为例的KPT流程图。
之后我们可以通过一个多对一映射将多个词上的预测概率映射到某个标签上。
但是由于知识库不是为预训练模型量身定做的,使用知识库扩展出的标签词具有很大噪音。例如SPORTS扩展出的movement可能和POLITICS相关性很大,从而引起混淆;又或者POLITICS扩展出的machiavellian(为夺取权力而不择手段的)则可能由于词频很低不容易被预测到,甚至被拆解成多个token而不具有词语本身的意思。
因此我们提出了三种精调以及一种校准的方法。
01
频率精调
我们利用预训练模型M本身对于标签词v的输出概率当成标签词的先验概率,用来估计标签词的先验出现频率。我们把频率较小的标签词去掉。
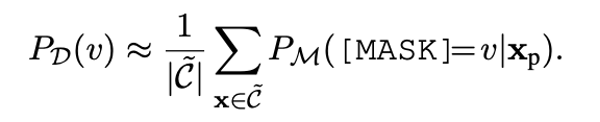
公式1: 频率精调。C代表语料库。
02
相关性精调
有的标签词和标签相关性不大,有些标签词会同时和不同标签发生混淆。我们利用TF-IDF的思想来赋予每个标签词一个对于特定类别的重要性。
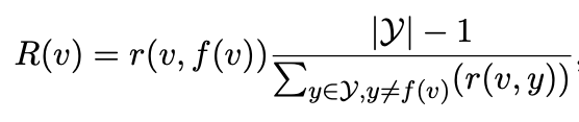
公式2: 相关性精调,r(v,y)是一个标签词v和标签y的相关性,类似于TF项。右边一项则类似IDF项,我们要求这一项大也就是要求v和其非对应类相关性小。
03
可学习精调
在少样本实验中,我们可以为每个标签词赋予一个可学习的权重,因此每个标签词的重要性就变成:
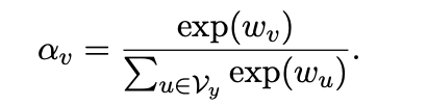
公式3:可学习的标签词权重。
04
基于上下文的校准
在零样本实验中不同标签词的先验概率可能差得很多,例如预测 basketball可能天然比fencing大,会使得很多小众标签词影响甚微。我们使用校准的方式来平衡这种影响。
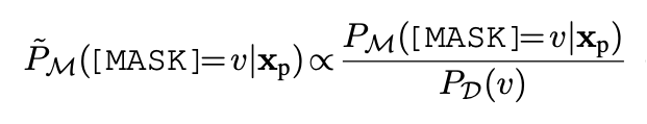
公式4: 基于上下文的校准,分母是公式1中的先验概率。
使用上以上这些精调方法,我们知识库扩展的标签词就能有效使用了。
实验
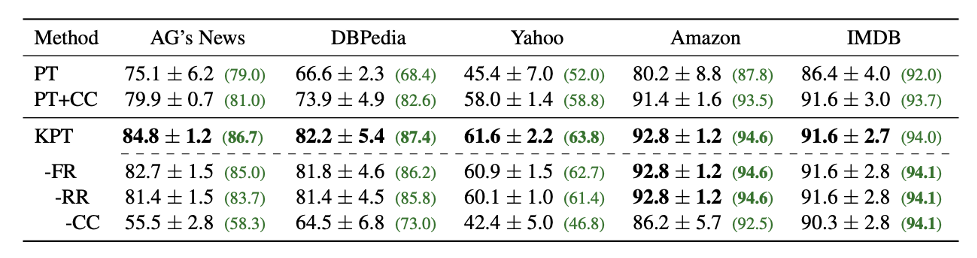
表2:零样本文本分类任务。
如表2所示,零样本上相比于普通的Prompt模板,性能有15个点的大幅长进。相比于加上了标签词精调的也最多能有8个点的提高。我们提出的频率精调,相关性精调等也各有用处。
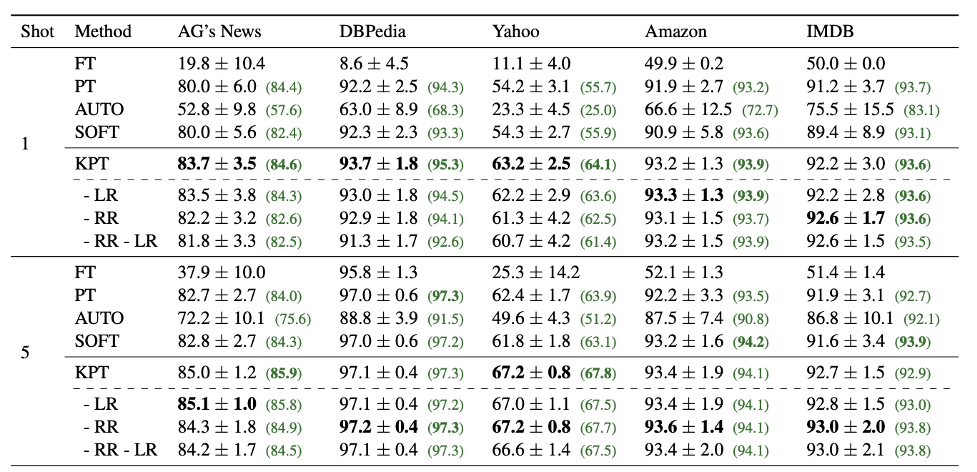
表3:少样本文本分类任务。
如表3所示,在少样本上我们提出的可学习精调搭配上相关性精调也有较大提升。AUTO和SOFT都是自动的标签词优化方法,其中SOFT以人工定义的标签词做初始化,可以看到这两种方法的效果都不如KPT。
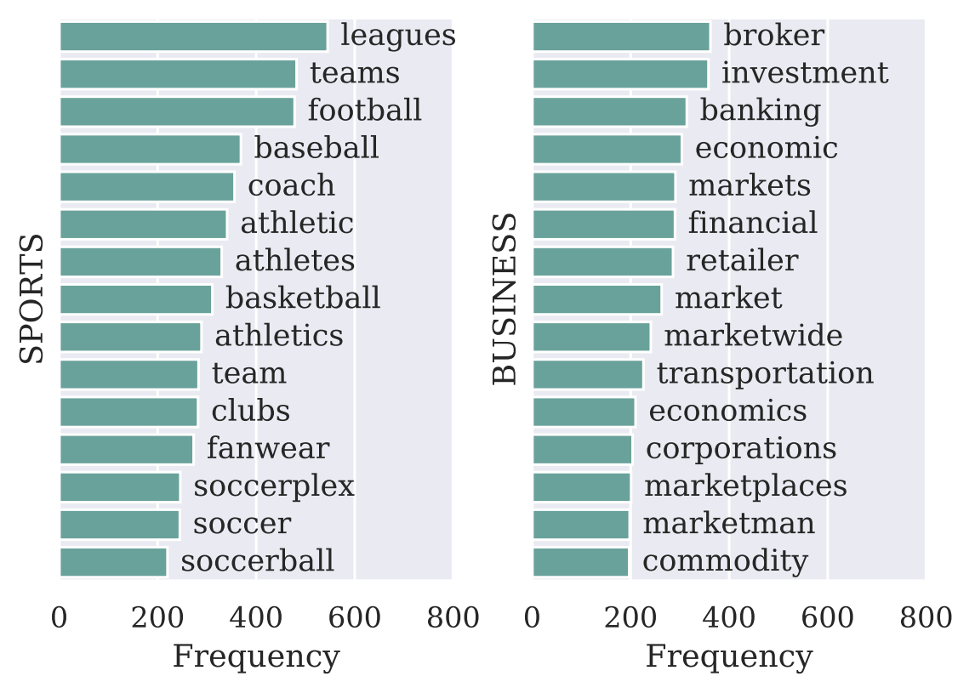
图2: SPORTS和BUSINESS类的知识库扩展的标签词对于预测的贡献。
标签词的可视化表明,每一条句子可能会依赖不同的标签词进行预测,完成了我们增加覆盖面的预期。
总结
最近比较受关注的Prompt Learning方向,除了template的设计,verbalizer的设计也是弥补MLM和下游分类任务的重要环节。我们提出的基于知识库的扩展,直观有效。同时也为如何在预训练模型的的利用中引入外部知识提供了一些参考。
审核编辑:郭婷
-
频率
+关注
关注
4文章
1588浏览量
62350 -
知识库
+关注
关注
0文章
15浏览量
6837
原文标题:ACL2022 | KPT: 文本分类中融入知识的Prompt Verbalizer
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
07. 如何在Allegro中设置可以走线但不能铺的铜区域?| 芯巧Allegro PCB 设计小诀窍
RAG(检索增强生成)原理与实践
机器学习特征工程:分类变量的数值化处理方法

电线电缆产品标准UL444阻燃等级CMP、CMR、CM、CMX分类知识

详解DBC的Signal与JSON文本结合

科技品牌的2026必修课:如何在CES Asia2026北京消费电子展上实现预算与效果的最优解?
万里红文本生成算法通过国家网信办备案
基于级联分类器的人脸检测基本原理
在标准库下配置的stm32f103x的spi在引入rtthread后收发的消息就错了,为什么?
我如何用Prompt工程将大模型调教成风控专家
如何在多显卡环境下配置OLLAMA实现GPU负载均衡
iXMC1404如何在XMC1400 SL上启用外部20 MHz晶振?
飞书开源“RTV”富文本组件 重塑鸿蒙应用富文本渲染体验



评论