 通过mmap实现零拷贝技术
通过mmap实现零拷贝技术

1.开场白
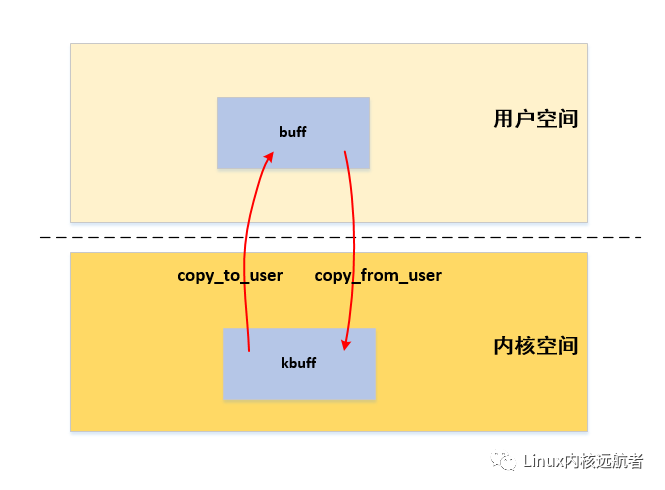
我们知道,linux系统中用户空间和内核空间是隔离的,用户空间程序不能随意的访问内核空间数据,只能通过中断或者异常的方式进入内核态,一般情况下,我们使用copy_to_user和copy_from_user等内核api来实现用户空间和内核空间的数据拷贝,但是像显存这样的设备如果也采用这样的方式就显的效率非常底下,因为用户经常需要在屏幕上进行绘制,要消除这种复制的操作就需要应用程序直接能够访问显存,但是显存被映射到内核空间,应用程序是没有访问权限的,如果显存也能同时映射到用户空间那就不需要拷贝操作了,于是字符设备中提供了mmap接口,可以将内核空间映射的那块物理内存再次映射到用户空间,这样用户空间就可以直接访问不需要任何拷贝操作,这就是我们今天要说的0拷贝技术。
下面是正常情况下用户空间和内核空间数据访问图示:
2. 体验一下
首先我们通过一个例子来感受一下:
驱动代码:
注:驱动代码中使用misc框架来实现字符设备,misc框架会处理如创建字符设备,创建设备等通用的字符设备处理,我们只需要关心我们的实际的逻辑即可(内核中大量使用misc设备框架来使用字符设备操作集如ioctl接口,像实现系统虚拟化kvm模块,实现安卓进程间通信的binder模块等)。
0copy_demo.c
#include
应用代码:test.c
#include
Makefile文件:
exportARCH=arm64
exportCROSS_COMPILE=aarch64-linux-gnu-
KERNEL_DIR?=~/kernel/linux-5.11
obj-m:=0copy_demo.o
modules:
$(MAKE)-C$(KERNEL_DIR)M=$(PWD)modules
app:
aarch64-linux-gnu-gcctest.c-otest
cptest$(KERNEL_DIR)/kmodules
clean:
$(MAKE)-C$(KERNEL_DIR)M=$(PWD)clean
install:
cp*.ko$(KERNEL_DIR)/kmodules
编译驱动代码和应用代码,然后拷贝到qemu中运行:
编译驱动模块代码:
$makemodules
编译并拷贝应用:
$makeapp
拷贝驱动模块到qemu:
$makeinstall
加载驱动代码:
#insmod0copy_demo.ko
[23328.532194]######misc_demo_init:91######
查看生成的设备节点:
#ls-l/dev/misc_dev
crw-rw----10010,5Apr719:26/dev/misc_dev
后台运行应用程序:
#./test&
#[23415.280501]######misc_dev_open:56######
[23415.281052]######misc_dev_read:20kbuff:helloworld!!!######
helloworld!!!
查看test的pid:
#pidoftest
1768
查看内存映射:
#cat/proc/1768/maps
aaaabc5a0000-aaaabc5a1000r-xp0000000000:198666193/mnt/test
aaaabc5b0000-aaaabc5b1000r--p0000000000:198666193/mnt/test
aaaabc5b1000-aaaabc5b2000rw-p0000100000:198666193/mnt/test
aaaacf033000-aaaacf054000rw-p0000000000:000[heap]
ffff8a911000-ffff8aa52000r-xp00000000fe:00152/lib/libc-2.27.so
ffff8aa52000-ffff8aa61000---p00141000fe:00152/lib/libc-2.27.so
ffff8aa61000-ffff8aa65000r--p00140000fe:00152/lib/libc-2.27.so
ffff8aa65000-ffff8aa67000rw-p00144000fe:00152/lib/libc-2.27.so
ffff8aa67000-ffff8aa6b000rw-p0000000000:000
ffff8aa6b000-ffff8aa88000r-xp00000000fe:00129/lib/ld-2.27.so
ffff8aa91000-ffff8aa92000rw-s0000000000:05152/dev/misc_dev//映射设备文件到用户空间
ffff8aa92000-ffff8aa94000rw-p0000000000:000
ffff8aa94000-ffff8aa96000r--p0000000000:000[vvar]
ffff8aa96000-ffff8aa97000r-xp0000000000:000[vdso]
ffff8aa97000-ffff8aa98000r--p0001c000fe:00129/lib/ld-2.27.so
ffff8aa98000-ffff8aa9a000rw-p0001d000fe:00129/lib/ld-2.27.so
ffffecb5a000-ffffecb7b000rw-p0000000000:000[stack]
执行了以上步骤可以发现最终内核中出现了我在应用程序中写入的“hello world!!!“ 字符串,应用程序也能成功读取到(当然本文讲解的0拷贝实现的驱动接口是mmap,而我们读取使用的是read接口,里面我们用copy_to_user来实现的,当然我们可以直接操作mmap映射的内存不需要任何拷贝操作)。
查看应用程序的内存映射发现,/dev/misc_dev设备被映射到了ffff8aa91000-ffff8aa92000这段用户空间地址范围,而且权限为rw-s(可读可写共享)。
写到这里可能大家还是有点不明白那我来解释下:
1.用户空间不能直接访问内核空间数据(不能直接读写),一旦访问发生缺页异常,产生段错误,必须通过read这样的接口来访问,而read这样的接口会通过系统调用的方式写入到内核态,然后通过copy_to_user这样的内核api来拷贝内核空间数据到用户空间之后才能正常访问。
2.通过mmap这种方式之后,用户进程可以直接访问这块内存,memcpy访问的也只不过是用户空间地址,由于访问的时候已经分配好了物理页面和建立好了物理页到虚拟页的映射,所有不会发生缺页异常,也不会发生用户态到内核态的陷入动作。
3.用户态进程正常访问内核态数据需要首先通过系统调用等方式陷入内核,进行数据拷贝,然后再次回到用户态,用户态和内核态直接的进出需要进行上下文切换,需要2次上下文切换,需要一定的开销,而mmap映射好之后以后访问都不需要进行上下文切换。
4.mmap映射这种方法由于物理页面通过页面共享更加节省内存,而用户态和内核态内存拷贝需要两份物理页面。
3.实现原理
我们发现通过mmap映射之后,我们在应用程序中可以直接读写这段内存,不需要任何用户空间和内核空间的拷贝动作,大大提高了内存访问效率,那么就是是如何实现的呢?下面我们来揭开它神秘的面纱:
实现0拷贝功不可没的是mmap接口中的remap_pfn_range内核api,它将内核空间映射的物理内存重新映射到了用户空间,下面我们来看这个函数的实现:remap_pfn_range函数参数如下:
intremap_pfn_range(structvm_area_struct*vma,unsignedlongaddr,
¦unsignedlongpfn,unsignedlongsize,pgprot_tprot)
vma为需要映射的进程的vma(进程调用mmap的时候内核会找到一个合适的vma), addr为vma中的一个起始映射地址(这是用户空间的一个虚拟地址),pfn为页帧号(在驱动的mmap接口中会将内核空间的地址转化为物理地址的页帧号),size为需要映射的大小,prot为映射的权限(一般取mmap时传递的权限如rw)
remap_pfn_range实现主要如下代码段:
remap_pfn_range
...
pgd=pgd_offset(mm,addr);
flush_cache_range(vma,addr,end);
do{
next=pgd_addr_end(addr,end);
err=remap_p4d_range(mm,pgd,addr,next,
pfn+(addr>>PAGE_SHIFT),prot);
if(err)
break;
}while(pgd++,addr=next,addr!=end);
解释下:remap_pfn_range函数会查找进程的页表,然后填写页表,会将映射的物理页帧号和访问权限填写到进程的对应页表中,这会遍历进程的各级页表找到最终的页表项然后进行填写,具体过程自行查看代码。
我们需要注意的是:
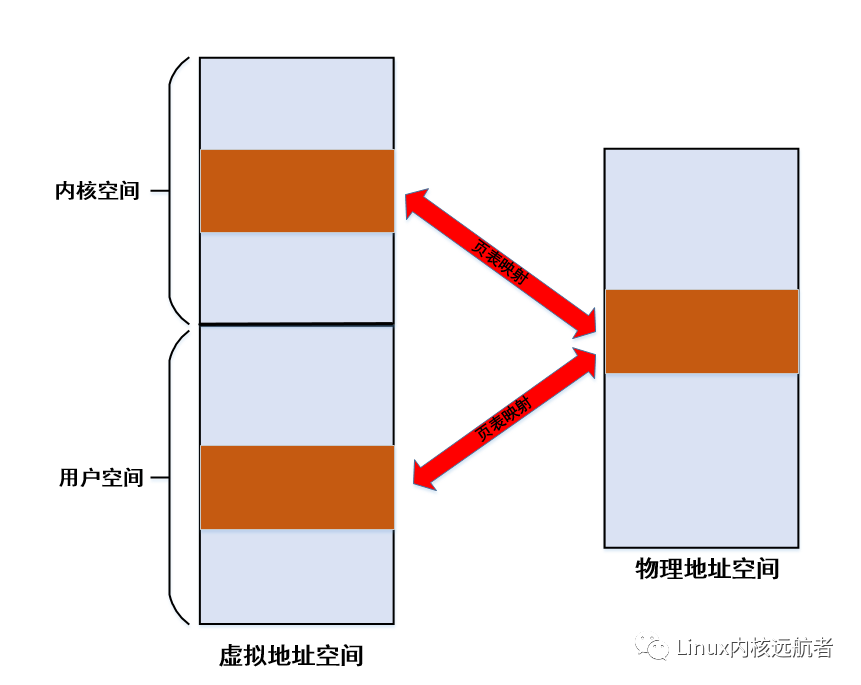
1.一般情况下,用户程序调用mmap只是申请虚拟内存(即是获得一块没有使用用户空间内存,使用vma描述),实际的物理页表都是通过进程访问的时候缺页异常的方式来申请的,但是本场景中是物理页面已经申请好了,进程访问时不会再发生缺页异常,不会申请物理页面。
2.同样,物理页面到用户空间虚拟页面的映射也在调用mmap的时候,驱动调用mmap接口的remap_pfn_range映射好了,也不需要在访问的时候发生缺页异常来建立映射。所以,只要用户进程通过mmap映射之后就可以正常访问,访问过程中不会发生缺页异常,映射虚拟页对应的物理页面已经在驱动中申请好映射好。
下面给出mmap映射原理的图示:
4.应用场景
最后,我们来看下使用framebuffer的lcd对0拷贝的使用情况:
fbmem_init//drivers/video/fbdev/core/fbmem.c
->register_chrdev(FB_MAJOR,"fb",&fb_fops)//注册framebuffer字符设备
->structfile_operationsfb_fops={
->.mmap=fb_mmap
->fb_mmap//framebuffer的实现
->vm_iomap_memory
->io_remap_pfn_range
->remap_pfn_range
->fb_class=class_create(THIS_MODULE,"graphics")//创建设备类
lcd驱动代码中会设置好最终注册framebuffer:
xxxfb_probe
->register_framebuffer
->do_register_framebuffer
->fb_info->dev=device_create(fb_class,fb_info->device,
¦MKDEV(FB_MAJOR,i),NULL,"fb%d",i);//创建设备会出现/dev/fdx设备节点
可以看到当系统支持framebuffer设备时,在fbmem_init中会创建framebuffer设备类关联字符设备操作集fb_fops,lcd的驱动代码中会调用register_framebuffer创建framebuffer设备(就会创建出了/dev/fdx 设备节点),应用程序就可以通过mmap来映射framebuffer设备到用户空间,然后进行屏幕绘制操作,不需要任何数据拷贝。
5.总结
可以看的出,通过mmap实现0拷贝非常简单,只需要在驱动的mmap接口中调用remap_pfn_range来将内核空间映射的那块物理页再次映射到用户空间即可,这就实现了用户空间和内核空间的数据共享,这和用户进程之间的共享内存机制非常相似,都需要操作进程的页表将这段物理内存映射到进程虚拟地址空间。
原文标题:5.总结
文章出处:【微信公众号:Linux阅码场】欢迎添加关注!文章转载请注明出处。
-
处理器
+关注
关注
68文章
20332浏览量
254914 -
内核
+关注
关注
4文章
1476浏览量
43089 -
Linux
+关注
关注
88文章
11817浏览量
219535 -
内存映射
+关注
关注
0文章
16浏览量
7627
原文标题:5.总结
文章出处:【微信号:LinuxDev,微信公众号:Linux阅码场】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
零碳园区能源互联的核心技术路径解析
HPM知识库 | BLDC 无传感器过零控制技术指南

锂电企业必看!如何通过知识驱动的具身智能工业机器人实现物流“零事故、零延误”停靠
零碳园区的能源结构优化需要哪些技术支持?

零碳园区如何实现能源互联
零碳园区如何实现高效能源管理与绿色电力消纳——探索现代能源系统的技术路径

内存拷贝函数 memcpy原理及实现
飞凌嵌入式ElfBoard-文件I/O的深入学习之存储映射I/O
实测2778MB/s,AMP核间通信“快如闪电”,瑞芯微RK3576

零磁通电流探头的技术原理与应用分析
通过PWM全桥转换器实现零电压开关
零碳园区如何实现智慧管理?有哪些方面?

阿里展厅同款无人超市技术解析:RFID与AI视觉如何颠覆零售?

黑芝麻智能一芯多域零拷贝共享内存技术:破解车载大数据传输效能困局

汽车零部件的MES系统解决方案:实现智能制造转型的核心利器




评论