 英特尔的Intel 4工艺详述
英特尔的Intel 4工艺详述

在 2019 年初,英特尔终于公开承认他们搞砸了——他们雄心勃勃的 10 纳米工艺失败了。这主要归因于其疯狂的密度改进目标以及太多新颖的技术特征证明。伺候,该公司承诺通过更平衡的 PPA 和衡量的风险承担恢复到更规律的节点更新节奏来纠正这一问题。历经两次的CEO 更换,在 Gelsinger 的监督下,我们终于看到了芯片巨头为重回正轨所做的一些努力。
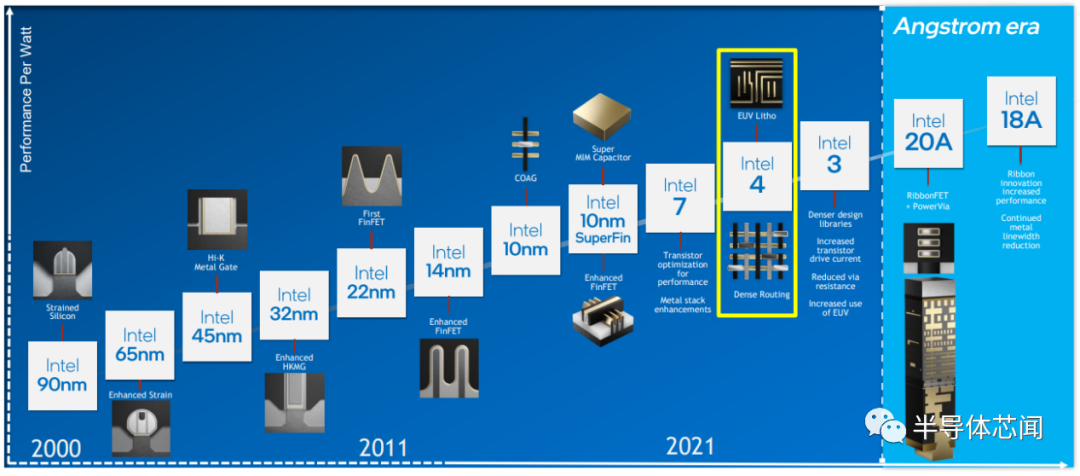
在本周早些时候在夏威夷举行的 2022 年 IEEE VLSI 技术和电路研讨会上,英特尔展示了许多涉及其英特尔 4 工艺的论文。这些论文主要由英特尔公司技术开发副总裁 Ben Sell 发表。
这个新节点称为 Intel 4。出于所有实际目的,它是适当的 10 纳米继任者。换句话说,如果它在 2020 年发布,它应该被正确地称为“7nm”。今天,它被称为“Intel 4”,是“Intel 7”(以前称为“10nm Enhanced SuperFin”,以前称为“10nm++”)的继任者。
Intel 4 很好但很奇怪,真的很奇怪。在时间方面,英特尔预计这一制程将在今年晚些时候加速——这意味着会是明年产品使用的工艺。如果一切按计划进行,Intel 4 的继任者“Intel 3”将在几乎整整一年之后(2023 年底开始升级)。这应该开始让您了解英特尔如何看待这个制程。
在深入研究细节之前,我们想强调一下Intel 4 并非设计为一个典型的成熟(full-fledged)节点。虽然它是一个高容量(high-volume )节点,但它可以在其上制作的内容非常有限(因此可能会大大限制其容量)。例如。它不会提供许多您通常会从英特尔节点看到的大型库,例如高密度和中档性能密度库,这些库对图形和其他应用程序等事物很重要,但对 CPU 核心设计来说,这并不重要。
从这个角度看,英特尔的这个节点是为为那些想把使用不同工艺的chiplet合封到一起的compute tile而准备的。
从小处着手,让它发挥作用,建立起来
Intel 4 代表了公司处理其节点设计方式的范式转变。 从历史上看,该公司专注于推出传统上所谓的全节点——大约每两年推出一个节点,带来整整一代的改进。代工厂(例如,台积电以及十年前的富士通、东芝、NEC 等)过去常常引入称为半节点的后续节点,这将进一步改进节点以及较小的间距缩放。 前提很简单:扩展和增强现有的高收益节点既便宜又容易。 而传统的“全节点”和“半节点”模型被淘汰了。随着最近 FinFET 节点的复杂性激增,代工厂转向新的“nodelet”方案。在此模型下,首先引入一个基本节点(例如,7LPP 或 N7),然后由一个或多个增强节点(nodelet)接替,几乎每年都会带来微小但增量的变化(例如,N7P、N7+、 N6,6LPP)。 快速接替Intel 4 的是Intel 3,预计将在明年年底推出。该公司表示,该制程将引入新的库,在密度、功率和性能方面都比Intel 4 有所提高。此外,Intel 4 与Intel 3 向前兼容,使设计迁移更容易。更重要的是,Intel 3 将拥有完整的代工产品。 在许多方面可以看出,英特尔都在借鉴代工手册。很明显,他们正在限制Intel 4 特性和功能的复杂性以降低风险。此外,他们今年推出 Intel 4 的能力将对他们明年按时将 Intel 3 推向市场的能力发挥重要作用,而正确执行是最重要的。他们的目标是构建更广泛、改进的功能组合、库、和其他 IP ,这在成熟的制程中要容易得多,并且这是解决此问题的正确方法。鉴于Intel 3 被定位为英特尔代工服务 (IFS) 的初始旗舰节点,这一点至关重要。 由于Intel 4 的范围有限,并且其快速跟进的成熟Intel 3 节点具有全节点密度/PPA 特性,我们认为最好将Intel 4 视为临时权宜之计节点。
产品
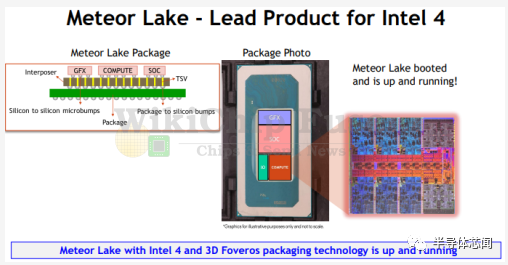
最初,英特尔透露 Meteor Lake 客户端 SoC 和 Granite Rapids 数据中心 SoC 都将在Intel 4 工艺上制造。然而,在今年早些时候的公司 2022 年投资者会议上,该公司宣布Granite Rapids的制造工艺将从Intel 4 升级到Intel 3 制程。出于我们今天对Intel 4 和Intel 3 之间关系的了解,这种切换对于Granite Rapids来说更有意义。 在诸如 IEEE VLSI Symposium 等技术会议上,英特尔通常将其演讲的范围仅限于其工艺的技术方面。在这个相当罕见和不寻常的场合,Sell 谈到了即将推出的第一款 Intel 4 产品——Meteor Lake。采用 Intel 4 的 Meteor Lake 将成为 3D foveros 封装技术的量产产品。Intel 4 支持最新的封装技术,并为 Foveros 提供了更激进的微凸点间距——从 50μm 扩展到 36μm。Meteor Lake 包含一个图形tiles、SoC tiles、计算tiles和 I/O tiles,所有这些都位于一个 Si 中介层上。Meteor Lake 封装和 die shot 如下所示。
制程概述
Intel 4(连同其增强版 Intel 3)是 Intel 最后一个基于 FinFET 的节点。在高层次上,这是继 22nm、14nm 和 10nm 之后第四个使用 FinFET 的主要节点。据说该工艺利用了第二代 COAG 和第二代单虚拟门( single dummy gate)。英特尔声称新的Intel 4 工艺为高性能库提供了大约 2 倍的面积扩展。最后,值得强调的是,这是该公司的首个 EUV 支持的工艺,有望显著简化工艺。
极紫外 (EUV) 光刻
自对准四边形图案 (SAQP)
有源栅极接触 (COAG)
单虚拟门 (SDB)
增强型铜互连

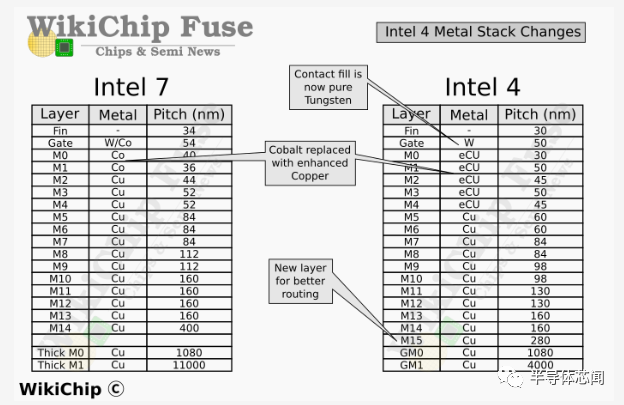
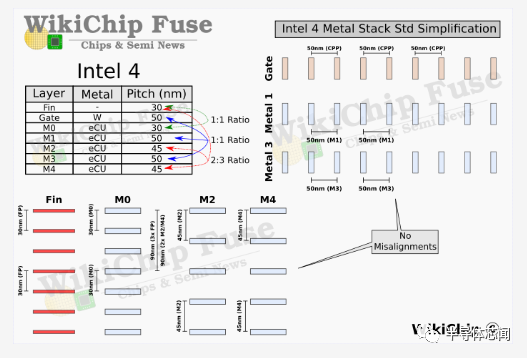
在晶体管级别,各种间距适度缩小。例如,与 Intel 7 相比,Intel 4 的鳍片间距为 30 纳米,栅极间距为 50 纳米,分别缩小了 0.83 倍和 0.88 倍。互连堆栈经历了一些更重要的变化,包括材料变化。例如,M0 金属间距经历了较大的间距从 40 nm 缩小到 30 nm 或 0.75 倍。 在进一步讨论之前,我们想重申一下,由于使用该节点的产品有限,Intel 4 将仅提供高性能单元库。通常,英特尔至少为逻辑设计了三个标准库。例如,使用英特尔 10nm,该公司拥有高密度单元、高性能/移动性能单元和超高性能单元。虽然它们使用相同的底层晶体管,但它们的特点是性能、功率和密度特性是 pMOS 和 nMOS 器件的函数。对于 FinFET 器件,这是鳍片数量的直接函数。因此,英特尔 10nm 具有每个器件可容纳 2 个鳍的 HD 单元、每个器件可容纳 3 个鳍的 HP 单元和每个器件可容纳 4 个鳍的 UHP 单元。
扩展(Scaling)是 DTCO-Heavy
正如我们在过去几个节点中看到的那样,PPA 目标现在在很大程度上都涉及 DTCO。Intel 4 也不例外。事实上,如果我们将intel 7 单元转移到intel 4 上并仅调整间距,我们将获得 1.22 倍的晶体管密度改进或大约 0.82 倍的缩放。这意味着,DTCO 不是pitch 缩放,而是intel 4 中密度改进的绝大部分。
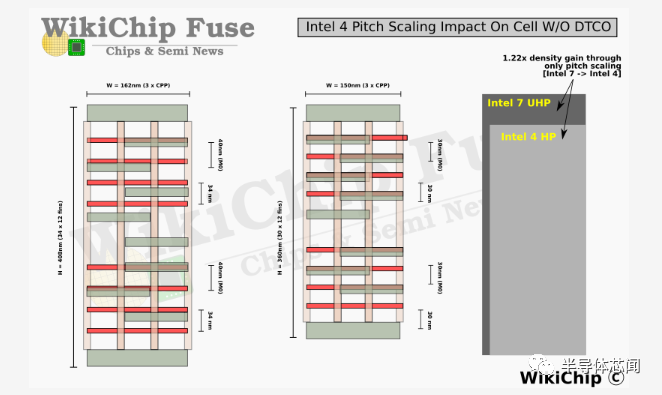
许多关键技术在这里发挥作用。 首先,intel 4 使用第二代 COAG 和第二代单虚拟门,允许它们随着新的栅极和鳍片间距进行扩展,同时保持单元高度和单元宽度的优势,从而实现我们在intel 7 中看到的密度改进。以前,英特尔在 nMOS 和 pMOS 器件之间的区域(栅极输入的前接触区域)有两条扩散线(diffusion lines)的间距。Intel 4 利用了单元的这一区域并消除了其中一条扩散线,从而缩短了单元高度并获得了宝贵的空间。我们估计仅此一项就产生了大约 11.5% 的面积缩放。 最后,由于其更高的性能,intel 4 经历了 4:3 的鳍片减少。这是对整体面积额外缩小 25% 的最大贡献。总而言之,DTCO 在传统pitch缩放的基础上增加了 1.5 倍的缩放。这证明了 DTCO 在现代前沿节点中的重要性,以及 STCO 将如何在引入未来技术(如埋入式电源轨和背面供电网络)中发挥更大的作用。
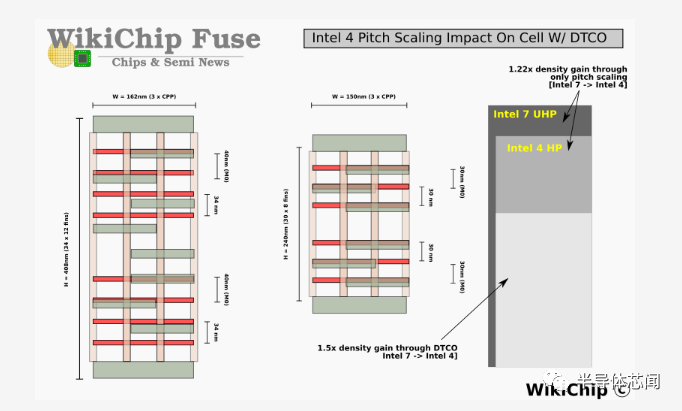
为了促进鳍的减少,必须增强设备性能。对于 Intel 4,该公司报告称,nMOS 和 pMOS 的驱动电流均超过每微米 2mA。对于 0.7 V 的 nMOS,驱动电流为每微米 2.25 mA,漏电流为每微米 20 nA。同样,对于 pMOS,在相同泄漏情况下,每微米的驱动电流为 2 mA。这些数字代表了比 10 纳米设备大约 25-30% 的改进。
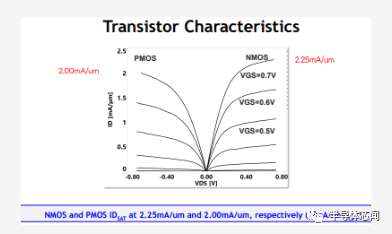
Intel 4 提供 8 个阈值(threshold )电压器件 (4 nMOS / 8 pMOS)。与 Intel 7 相比,这些新设备提供了额外 5% 的功率不受限制的性能提升。
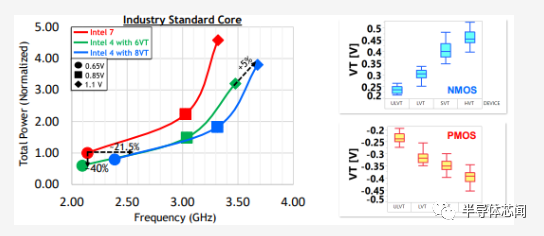
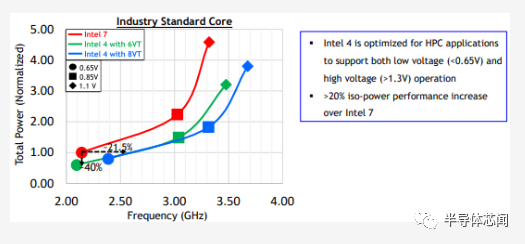
英特尔还报告了一些使用标准可授权内核(可能是 Cortex-A7x 内核)的功率性能数据。下面的电源频率图展示了在intel 7 与intel 4 上制造相同内核的对比情况。在低电压下,英特尔报告在等功率下的频率比intel 7 提高了 20% 以上。或者,在相同的低电压下,相同的内核结果在等频处能量减少约 40%。
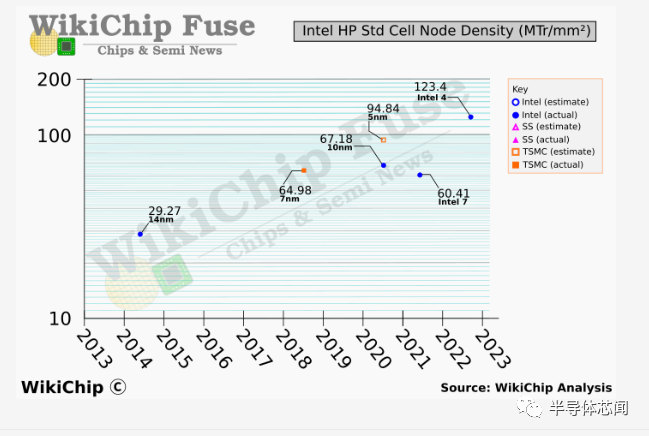
密度
综上所述,英特尔表示,根据内部估计,他们看到从intel 7 到intel 4 的完整高性能库扩展为 2 倍。

像往常一样,WikiChip 根据当前公开的代工数据生成自己的独立估计。 我们自己的估计表明,intel 4 的密度比英特尔 7/10nm 提高了 1.83 倍。但是,我们的估计还表明,intel 4 提供的密度比intel 7 提高了 2.04 倍。这是怎么算出来的?答案实际上在英特尔自己的 VLSI 演示幻灯片中。 随着 10 纳米 SuperFin 及其后继产品增强型 SuperFin(现在称为 Intel 7)的推出,英特尔推出了一种具有 60 纳米多晶间距的新型晶体管,以实现更高的驱动电流性能。在生产性能显著提高的晶体管的同时,它的不利影响是将逻辑密度降低了 0.9 倍。值得注意的是,这些cell被用于Alder Lake中的 Golden Cove 和 Gracemont 核心。 为此,我们估计intel 4 密度为 123.4 MTr/mm²,是英特尔 7 中 60.5 MTr/mm² 的 2.04 倍。我们对 TSMC N5 的数据非常不完整,但我们基于已知间距的粗略估计将其 HP 库为 94.85 MTr/平方毫米。根据最近公开的大多数代工数据,intel 4 HP 单元似乎比 TSMC N5 HP 更密集,并且可能更接近或优于 TSMC N3 HP 单元,并且比三星的 3GAE 更密集。鉴于过去三年 10nm 对公司造成的动荡,以这样的数字出现是相当令人惊讶的。它还强烈表明intel 3 可以匹配并超越即将推出的 3nm 级代工产品。
以匹配并超越即将推出的 3nm 级代工产品。
互连
Intel 4 互连堆栈经历了相当大的变化。
Intel 4 的基本设计规则的一个亮点如下所示,与具有 17 个金属层的 Intel 7 相比,Intel 4 增加了一层。M4 上方的大多数互连都看到了通常的间距缩小,其中大部分在 0.7x-0.85x 缩放左右。与之前的节点一样,两个顶层是厚金属层。与大多数其他wires相比,英特尔大幅缩小了最后一层厚金属层。最受关注的区域是前四个路由层(routing layers)。在那里,不仅某些间距没有缩小,有些实际上变宽了。这些层也经历了新的材料变化。
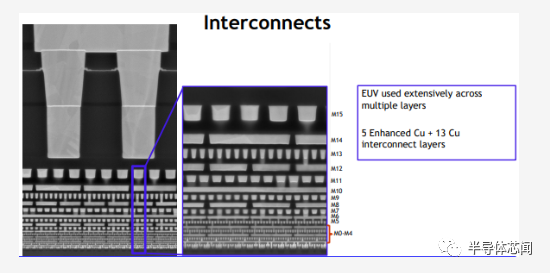
尽管英特尔没有详细说明确切的层,但 EUV 和 SAQP 都以最紧密的间距使用。此外,使用单一镶嵌(damascene )工艺来形成 M0 轨道的触点,这可能有助于在该步骤中形成 EUV 图案。
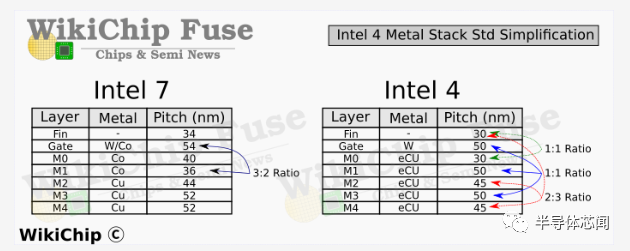
四个最低金属层在两个正交方向上横跨芯片,用于cell本地电源和路由。在 Intel 4 中,它们具有非常规则的pitches。为什么有些间距缩小而其他间距变宽似乎有一个很好的理由,这主要与单元布局优化有关。 在 Intel 7 中,M1 层非常激进的鳍片间距意味着该公司采用了 3:2 的间距比。这有一些奇怪的副作用。在Intel 4 中,英特尔实际上将间距缩小了近 1.4 倍,以通过相同的间距将其固定到门上。正如我们将在下面展示的那样,这不仅简化了设计,而且完全消除了布局的一些不合适。英特尔似乎对 M3 层做了同样的事情。我们在这里的最后观察涉及也与鳍平行的 M2 和 M4 层。这些具有2:3的比例。
正如我们之前提到的,在 Intel 7 中,该公司选择了非常激进的 M1 间距 ——36 nm。该轨道( track)平行于多边形轨道。选择该间距是为了便于金属层和栅极间距之间的比率为 3:2。换句话说,更紧密的间距允许每个单元的每个poly有更多的 M1 轨道,这意味着更多的引脚命中位置。这种设计提供了更好的单元间连接和更好的块级访问。不幸的是,在 M1 处具有此比率也会导致一些单元级别的奇怪,其中取决于cell poly count的均匀/奇数,您最终可能会得到左对齐或右对齐的单元格。解决这个问题意味着减少面积利用率。
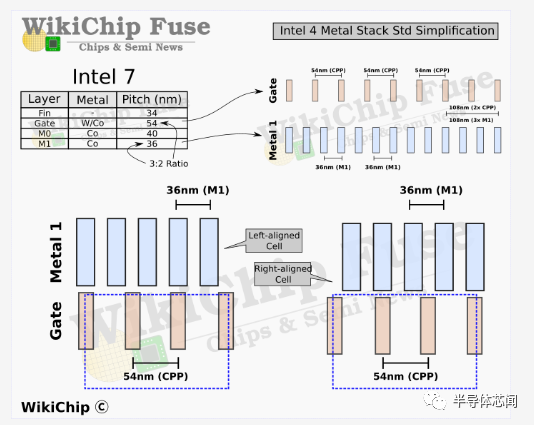
为了简单起见,Intel 4 显然完全放弃了该方案。M1 和 M3 层现在都与poly挂钩,完全消除了这种错位问题。有趣的是,该公司还将 M0 轨道固定在鳍上。那些垂直于多边形。在 Intel 7 中具有 44nm 和 52nm 间距的上 M2 和 M4 层在 Intel 4 中都具有 45nm。从布局的角度来看,选择 45nm 是非常清楚的,因为它们现在以 2 :3的比例固定在鳍片上。请记住,由于单元格高度是一个固定属性,因此在该方向上没有对齐问题。
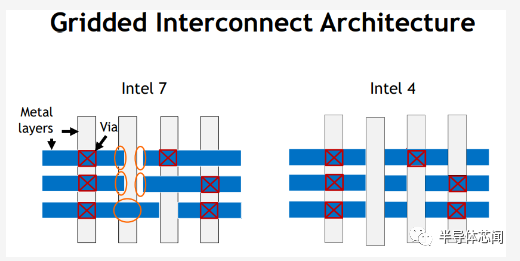
在 VLSI 上,英特尔还讨论了intel 4 引入的新网格互连架构。在之前的节点中,英特尔定义了通孔和track end caps的最小间距。但是,没有具体说明它们的确切位置。这导致了大量的patterns,由于增加的patterns可变性而引入了新的分析复杂性层。在 Intel 4 中,线端和过孔现在严格放置在网格上,从而减少了可能的放置。据说新的简单网格限制通过减少图案可变性以及通过更好地识别问题和优化自动布局布线 (APR) 设计流程来提高良率。
铜回来了
当英特尔首次推出他们的 10 纳米工艺时,他们宣布推出新的互连材料——钴。主要动机是其更好的电迁移特性。随着我们继续缩小互连,铜互连的高电阻率衬垫和阻挡层的厚度基本保持不变(the thickness of the high-resistivity liner and barrier for the copper interconnects stayed about the same)。这主要是由于工程上难以将其减薄到比现有的几纳米更小。最终结果是,随着wires规模的提升,屏障(barrier )本身开始在互连横截面积中占据越来越大的份额。随着High-resistivity barriers慢慢构成互连的大部分,它开始主导导线本身的电阻率。
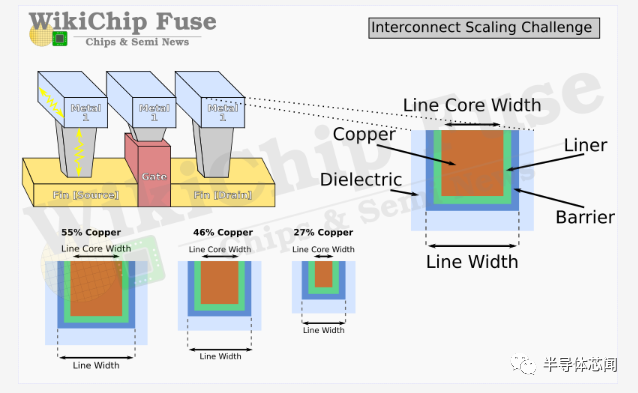
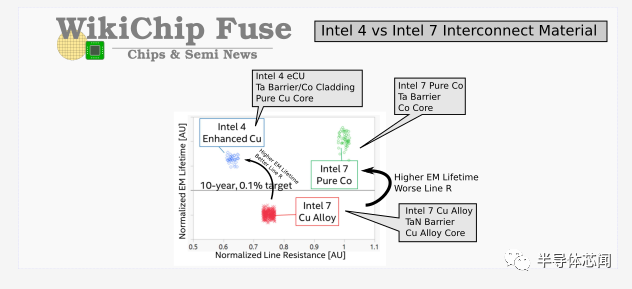
、 虽然由于钴及其更薄的衬里,在10nm工艺上,两个局部互连层(M0 和 M1)处的wire电阻确实增加了,但英特尔报告称线路电阻降低了 2 倍。此外,这两层也使电迁移提高了 5-10 倍。但最终,英特尔似乎在Intel 4 中退出了钴。钴是一种更难使用的材料,并且被推测是导致其良率难以提升的根源之一。 在下图中,英特尔展示了intel 7 与具有钽阻挡层(Tantalum barrier )的纯钴内核与具有氮化钽阻挡层(Tantalum nitride barrier)的传统铜合金内核之间的关系。这两个选项具有互补的属性。纯 Co 提供了相当好的电迁移特性,但提供了更差的线路电阻。同样,Cu 合金提供更好的线路电阻但更差的电迁移寿命。事实上,与纯钴相比,铜合金提供了 0.75 倍的线路电阻,这是相当大的电阻下降。对于 Intel 4,该公司选择在最低的四个金属层中使用增强型铜 (eCu)。这种增强的铜线包括一个钽阻挡层,而在纯铜芯周围也有钴包层。
内存
与仍然提供双倍晶体管密度的逻辑缩放不同,内存缩放正在面临严峻挑战。
Intel 4 引入了两个标准的 6T SRAM 单元——高密度和大电流单元。高密度 (PUPD = 11) cell从 0.0312 平方微米缩小到 0.0240,而高性能 (PUPD = 12) cell缩小到 0.0300 平方微米. 这些cell分别看到了 0.77 倍和 0.68 倍的缩放比例,这与我们过去看到的约 0.6 倍的历史缩放比例相去甚远。除了 6T 单元之外,英特尔还开发了一个 8T SRAM 位单元,它在 6T 写入端口的基础上增加了一个 3 鳍读取端口,总面积为 0.0360 平方微米。虽然占用 1.74 倍的面积,但它使用的读/写能量分别比 HDC 和 HCC 低 6 倍和 12 倍。
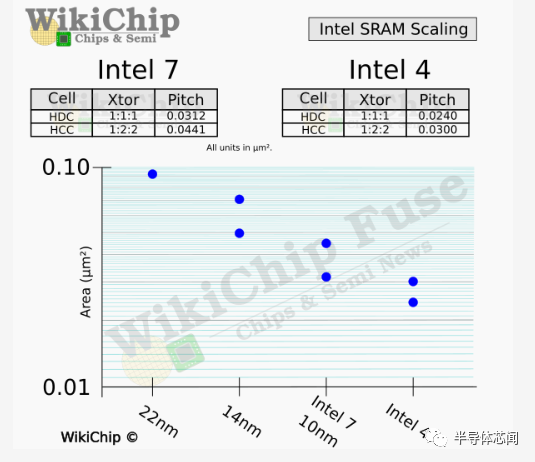
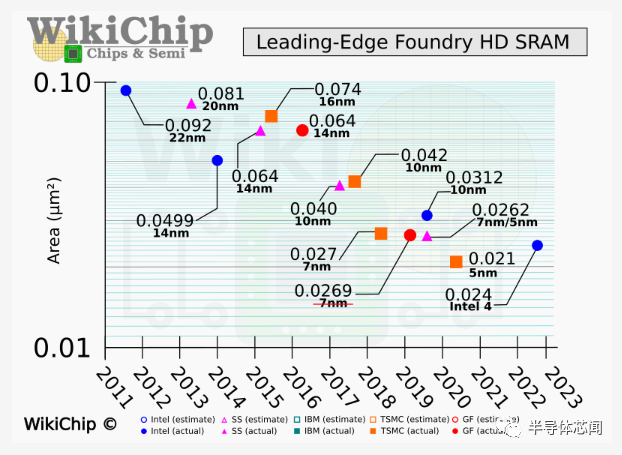
将Intel 4 的密度与台积电和三星的代工产品进行比较时,英特尔 4 SRAM 的尺寸实际上相当令人失望。对于我们在这里的密度估计,我们使用我们的标准等辅助电路开销方法,该方法可能与公司自己报告的数字不同。为此,intel 4 HDC 产生了大约 27.8 Mib/mm² 的内存密度。与密度为 31.8 Mib/mm² 的 TSMC N5 SRAM 相比,英特尔的密度大约低 14.5%。
英特尔还展示了其intel 4 SRAM shuttle 测试芯片。test vehicle具有 57 Mib 的高密度cell和 50 Mib 的高性能cell。硅测量表明,高密度cell的 90% Vim 工作电压(percentile Vim operation)为 0.6 V,高性能cell的工作电压为 0.55 V。

intel 4 还改进了intel 7 的 MIM 电容器。intel 4 上的新 MIMcap 提供了令人印象深刻的两倍于intel 7 的电容,达到 376 fF/μm²。
结论
在经历了五年的制造问题折磨之后,英特尔终于出现了复苏的迹象。 在 2022 年 IEEE VLSI 技术和电路研讨会上,英特尔终于公布了他们的下一代领先的高性能工艺节点——intel 4。该节点预计将在今年年底前量产。虽然在功能方面不如他们通常的节点那么全面,但intel 4 提供了足够的功能来支持他们的下一代客户端 SoC(代号 Meteor Lake)所需的计算块。该节点充分利用 EUV 并提供比 Intel 7 大约 20% 的性能/瓦特增益。 在 SoC 级别,该节点在等频下可降低多达 40% 的功率或在等频下提供 >20% 的频率提升-力量。此外,该节点的高性能库拥有完整的 2.04 倍密度缩放,超过intel 7 中用于 Alder Lake 的最高性能单元。在纸面上,这些 PPA 特性使公司的新intel 4 工艺的性能水平优于台积电 N3 和三星 3GAE。在密度方面,英特尔 4 与 N3 高性能库相比似乎极具竞争力。 很明显,Intel 4 是经过精心制作的。仔细的标准单元缩放以及架构简化有助于降低工艺复杂性。随着 EUV 的引入,回归到更简单的材料有助于大大减少掩模、步骤和图案的可变性和复杂性。英特尔表示,与英特尔 7 相比,新节点还大大降低了每个晶体管的成本。 尽管如此,我们认为英intel 4 是一个权宜之计节点——一个最小可行的产品,是通往intel 3 的中间节点,这预计将发生在intel 4 之后大约一年(明年年底)。Intel 3 将是 Intel 的最终 FinFET 工艺。此后的一切都将使用该公司称为 RibbonFET 的新的环栅晶体管架构。intel 3 恰好也是英特尔代工服务 (IFS) 即将推出的旗舰节点。intel 3 建立在intel 4 的基础上,这就是为什么及时正确地将intel 4 提升到良好的良率和高产量如此重要的原因。该公司已经透露,intel 3 将再提供 18% 的性能/瓦特改进,这本身就是一个全节点改进。该过程还将引入一个新的更密集的高性能库以及一组更完整的其他库和 IP。
从本文详述的 Intel 4 工艺,该公司能否重新获得其在半导体行业的领先地位,完全取决于其执行力。
审核编辑 :李倩
-
英特尔
+关注
关注
61文章
10340浏览量
181328 -
intel
+关注
关注
19文章
3514浏览量
191814 -
半导体行业
+关注
关注
10文章
406浏览量
42034
原文标题:英特尔首个使用EUV的工艺详解
文章出处:【微信号:iotmag,微信公众号:iotmag】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
英特尔炮轰,AMD回击!掌机市场芯片之争
超越台积电?英特尔首个18A工艺芯片迈向大规模量产

英特尔制程双线推进:Intel 18A良率稳步爬坡,Intel 14A目标2029年量产
苹果与英特尔正式达成代工协议,芯片供应链格局迎来重大调整
AI工作站本地养龙虾!英特尔双芯混合算力,告别云端Token焦虑

英特尔第三代酷睿处理器发布:18A 工艺普惠 AI,重塑日常计算体验
2026英特尔客户高峰论坛:杰和科技以深度协同收获技术跃迁

Intewell×Intel 强强联合 | 光亚鸿道亮相2025英特尔生态大会

吉方工控携手英特尔推动中国智能产业发展
吉方工控荣膺英特尔中国2025市场突破奖
吉方工控亮相2025英特尔技术创新与产业生态大会
吉方工控获评英特尔首批尊享级合作伙伴
18A工艺大单!英特尔将代工微软AI芯片Maia 2
英特尔连通爱尔兰Fab34与Fab10晶圆厂,加速先进制程芯片生产进程
英特尔锐炫Pro B系列,边缘AI的“智能引擎”




评论