 如何显著提升Vision Transformer的训练效率
如何显著提升Vision Transformer的训练效率

近期MetaAI发布了一篇博客,关于如何显著提升Vision Transformer的训练效率。
原文:[Significantly faster Vision Transformer training]
链接:https://ai.facebook.com/blog/significantly-faster-vision-transformer-training
What the research is
Vision Transformer模型几乎火遍计算机视觉各个领域,其性能随着参数增加和更久的训练过程而得到提升。随着模型越来越大,超过了万亿次浮点运算的规模,该领域达到了瓶颈:训练一个模型往往要一个月,需要几百上千个GPU,导致大部分人无法接触到大规模ViT模型,并进而增加了对加速器的需求。
为了降低门槛,让更多人能够应用ViT,我们开发一系列方法来加速整个训练。我们基于MetaAI的图像分类模型库PyCls实现了一系列优化,这些优化极大的提升了模型训练过程的吞吐量:
How it works ?
我们首先对代码库进行分析,以定位训练效率低下的原因,最后关注点落在计算类型上:大部分模型都是用FP32进行训练,如果使用FP16训练的话,可以降低显存占用,并提高模型训练速度,但这一做法经常会导致准确率下降
所以我们选了一个折中的方法:自动混合精度。在该方法下,我们用half类型进行计算,以加快训练,减少显存使用。并以fp32类型存储参数,以保证模型准确率。其中我们没有手动将网络各部分转换成half类型,而是应用AMP各种模式(如O1, O2, O3),以寻找一个既能提升速度又不影响精度的平衡点。
FSDP
为了让训练更加高效,我们应用了FSDP训练策略,他能够将参数,梯度,优化器状态分片到各GPU上。在FSDP的帮助下,我们可以用更少的GPU资源构建更大的模型。
FSDP策略可以参考 [数据并行Deep-dive: 从DP 到 Fully Sharded Data Parallel (FSDP)完全分片数据并行] 链接:https://zhuanlan.zhihu.com/p/485208899
MTA Optimizer
前向计算完毕后,优化器需要对各个参数进行修改。而当参数比较多的情况下,对应启动的Optimizer Kernel就会变得很多,通常这些Kernel都比较小,计算负担不大,启动Kernel的开销反而占了大头。
在ContiguousParams中,它将模型参数放置到一块连续的显存中进行计算,这样就能减少优化器这部分的时间。下图是Resnet50+SGD是否应用ContiguousParams的比较,可以看到OptimizerStep这部分时间显著减少了。
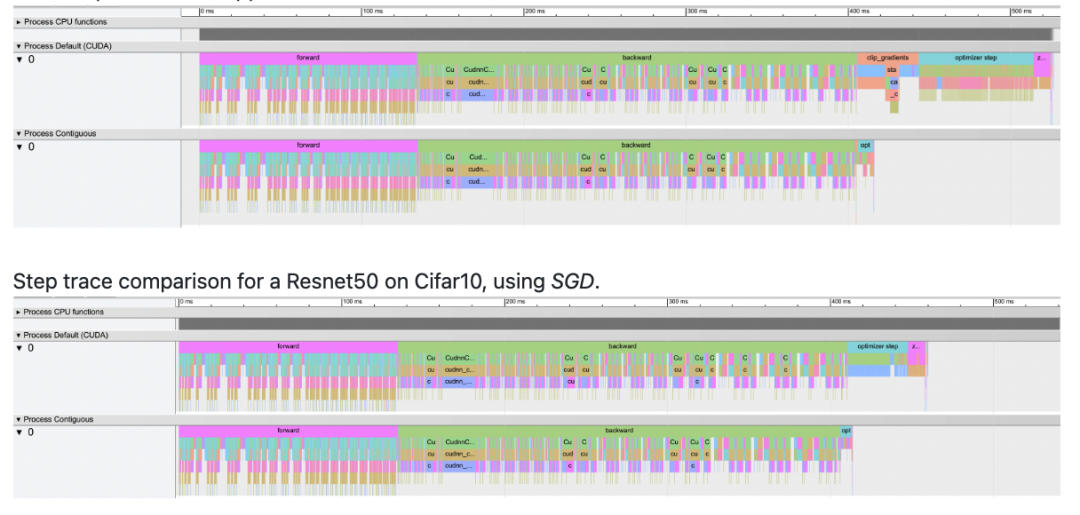
而NVIDIA的Apex库的做法则是在底层重新实现了一系列MultiTensorOptimizer,如Adam, Adagrad等等。
Apex这种方法比较硬核,普通用户如果想要自己自定义优化器并应用Multi Tensor的优化,就必须改动底层CUDA代码。而最近PyTorch也在计划提供了一系列foreach接口[Replace optimizers in torch.optim with the ones from torch.optim._multi_tensor] 链接:https://github.com/pytorch/pytorch/pull/49039,让用户只需要在Python层即可享受到优化,对应的MultiTensor版Momentum优化器代码如下所示:
torch._foreach_mul_(bufs,momentum)
torch._foreach_add_(bufs,grads,alpha=1-dampening)
Pooled Classifier
原版的ViT是额外加了一个分类token,来输出最后的分类结果。而这里采用平均池化 如:https://github.com/facebookresearch/pycls/blob/main/pycls/core/config.py#L205 处理最后的分类
Batch Second Input Tensor Layout
这里的数据格式与以往不同,将batch维度放在第二维,并在调用nn.MultiheadAttention的时候,设置batch_first=False,以减少不必要的转置
ifself.batch_firstandis_batched:
returnattn_output.transpose(1,0),attn_output_weights
else:
returnattn_output,attn_output_weights
总感觉这个实现怪怪的
其他优化
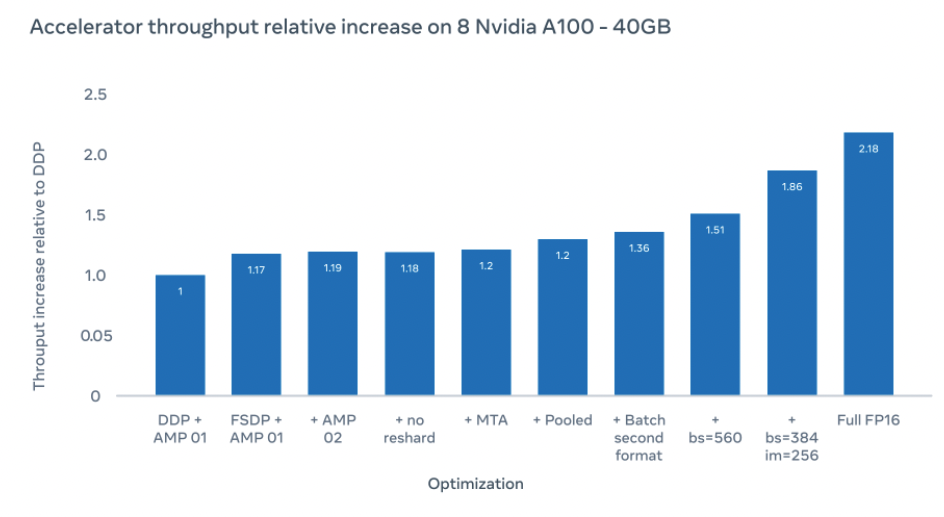
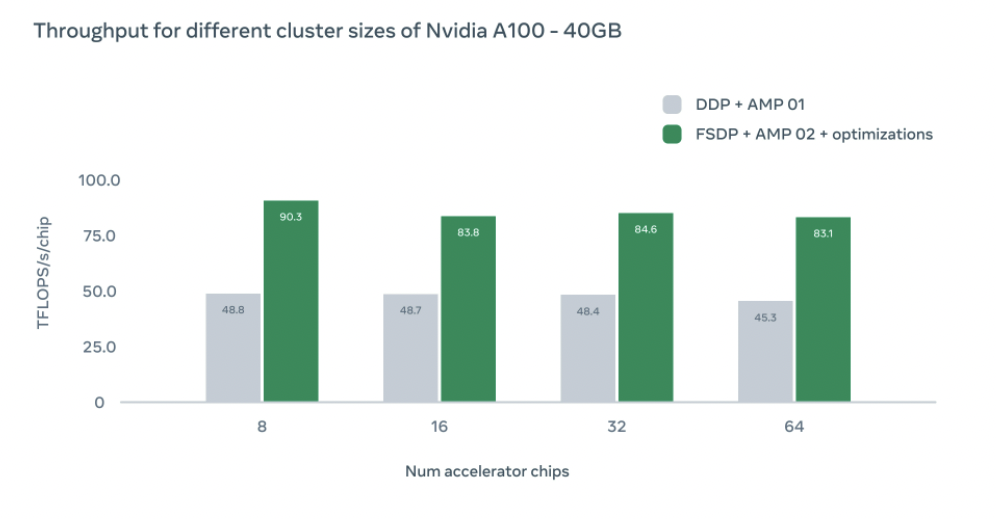
我们在采取560大小的batchsize下,达到了1.51倍的加速比,进一步的我们将batchsize设置为384,并将图片大小增大到256,达到了1.86倍加速比。在全FP16运算下,能够达到2.18倍加速比,尽管这偶尔会降低准确率(在实验中,准确率降低不到10%)。
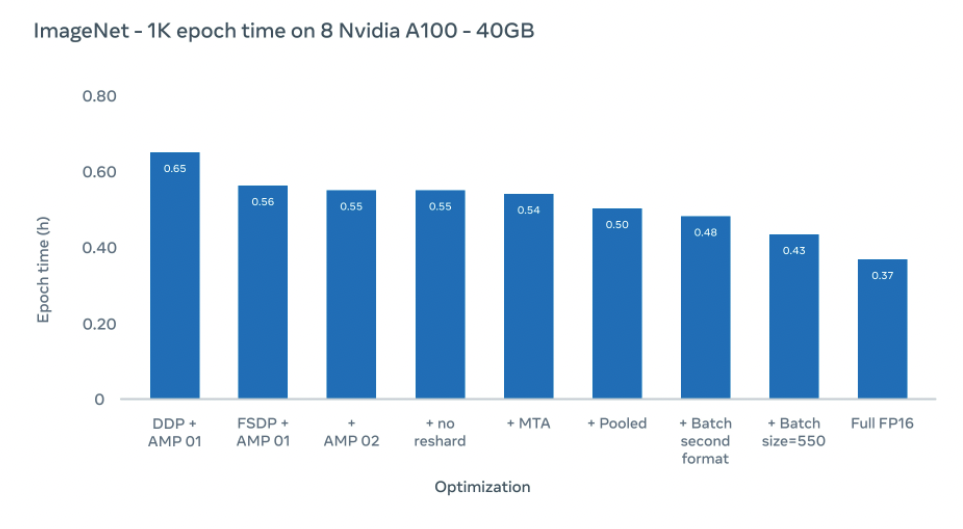
使用上述优化,我们将Imagenet1K数据集每epoch训练时间从0.65小时降低到0.43小时
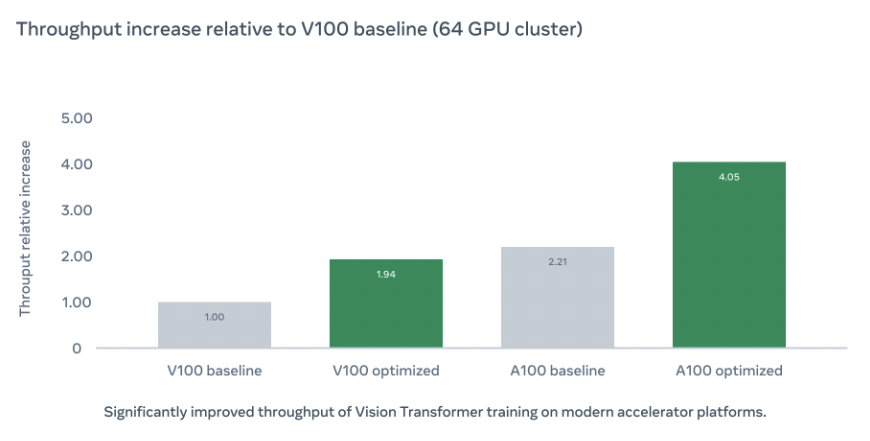
我们还研究了不同GPU配置对训练速度的影响,在不同配置下我们都实现了比DDP baseline更高的吞吐量。随着GPU增加,吞吐量会因为设备之间的通信开销略微下降。然而即使在64块GPU下,我们仍然比DDP基线快1.83倍
文中链接
PyCls :https://github.com/facebookresearch/pycls
ContiguousParams:https://github.com/PhilJd/contiguous_pytorch_params
Adam:https://github.com/NVIDIA/apex/blob/master/csrc/multi_tensor_adam.cu
审核编辑 :李倩
-
加速器
+关注
关注
2文章
836浏览量
39712 -
Vision
+关注
关注
1文章
204浏览量
19281
原文标题:如何更快地训练Vision Transformer
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
信维低损耗MLCC电容,提升电路效率优选
函数发生器和直流电源结合如何显著提升测试效率
斑马技术助力PouchNATION提升大型活动管理效率
借助NVIDIA Megatron-Core大模型训练框架提高显存使用效率

【「AI芯片:科技探索与AGI愿景」阅读体验】+第二章 实现深度学习AI芯片的创新方法与架构
同步整流MOSFET的设计要点与效率提升技巧

快手上线鸿蒙应用高性能解决方案:数据反序列化性能提升90%
提升AI训练性能:GPU资源优化的12个实战技巧

摩尔线程GPU原生FP8计算助力AI训练

优化汽车点焊生产线,提升制造效率与质量
回馈式交流电子负载:测试效率与节能效果的双重提升
地平线ViG基于视觉Mamba的通用视觉主干网络
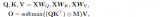
港大提出SparX:强化Vision Mamba和Transformer的稀疏跳跃连接机制

RFID技术赋能民兵装备管理,仓储效率显著提升





 工商网监
工商网监
评论