 视频P图新SOTA:推理速度快近15倍
视频P图新SOTA:推理速度快近15倍

众所周知:视频是可以P的。
这不,在CVPR 2022收录的论文中,就出现了这么一个P图神器,它可以分分钟给你上演各种人像消失大法,不留任何痕迹。
去水印、填补缺失更是不在话下,并且各种分辨率的视频都能hold住。
正如你所见,这个模型如此丝滑的表现让它在两个基准数据集上都实现了SOTA性能。

△与SOTA方法的对比
同时它的推理时间和计算复杂表现也很抢眼:
前者比此前的方法快了近15倍,可以在Titan XP GPU上以每帧0.12秒的速度处理432 × 240的视频;后者则是在所有比较的SOTA方法中实现了最低的FLOPs分数。
如此神器,什么来头?
改善光流法
目前很多视频修复算法利用的都是光流法(Optical flow)。
也就是利用图像序列中像素在时间域上的变化以及相邻帧之间的相关性,找到上一帧跟当前帧之间存在的对应关系,从而计算出相邻帧之间物体的运动信息。
这个方法的缺点很明显:计算量大、耗时长,也就是效率低。
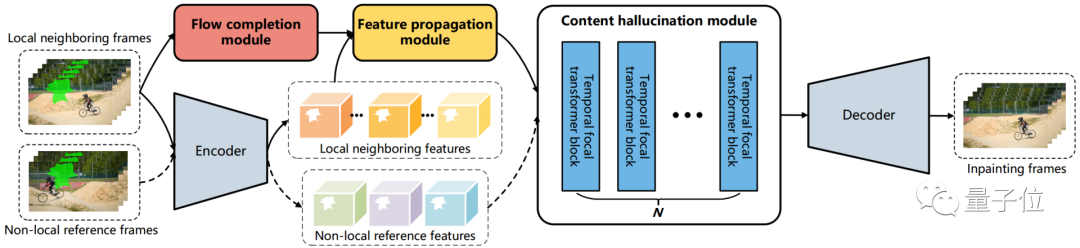
为此,研究人员设计了三个可训练模块,分别为流完成(flow completion)、特征传播(feature propagation)和内容幻想(content hallucination),提出了一个流引导(flow-guided)的端到端视频修复框架:
E2FGVI。
这三个模块与之前基于光流的方法的三个阶段相对应,不过可以进行联合优化,从而实现更高效的修复过程。
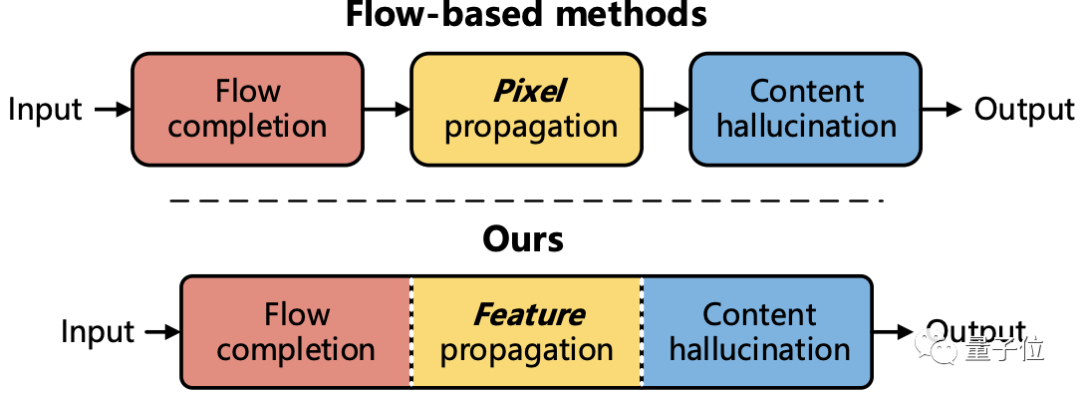
具体来说,对于流完成模块,该方法直接在mask viedo中一步完成操作,而不是像此前方法采用多个复杂的步骤。
对于特征传播模块,与此前的像素级传播相比,该方法中的流引导传播过程在特征空间中借助可变形卷积进行。
通过更多可学习的采样偏移和特征级操作,传播模块释放了此前不能准确进行流估计的压力。
对于内容幻想模块,研究人员则提出了一种时间焦点Transformer来有效地建模空间和时间维度上的长程依赖关系。
同时该模块还考虑了局部和非局部时间邻域,从而获得更具时间相关性的修复结果。
作者:希望成为新基线
定量实验:
研究人员在数据集YouTube VOS和DAVIS上进行了定量实验,将他们的方法与之前的视频修复方法进行了比较。
如下表所示,E2FGVI在全部四个量化指标上都远远超过了这些SOTA算法,能够生成变形更少(PSNR和SSIM)、视觉上更合理(VFID)和时空一致性更佳(Ewarp)的修复视频,验证了该方法的优越性。
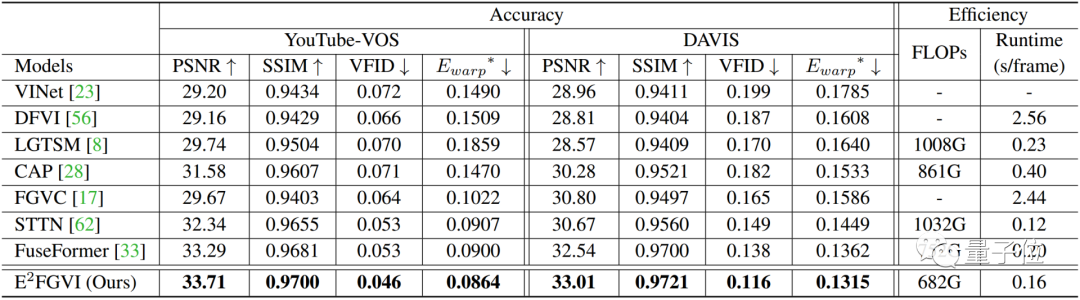
此外,E2FGVI也具有最低的FLOPs值(计算复杂度),尽管训练是在432 × 240分辨率的视频上进行,它的HQ版本做到了支持任意分辨率。

定性实验:
研究人员首先选择了三种最有代表性的方法,包括CAP、FGVC(基于光流法)和Fuseformer(入选ICCV 2021),进行对象移除(下图前三行)和缺失补全(下图后两行)的效果比较。
可以发现,前三种方法很难在遮挡区域恢复出合理的细节、擦除人物也会造成模糊,但E2FGVI可以生成相对真实的纹理和结构信息。

此外,它们还选用了5种方法进行了用户研究,结果大部分人都对E2FGVI修复后的效果更满意。
综上,研究人员也表示,希望他们提出的方法可以成为视频修复领域新的强大基线。
作者介绍

E2FGVI由南开大学和海思合作完成。
一作Li Zhen为南开大学博士生,共同一作Lu ChengZe也来自南开。
通讯作者为南开大学计算机学院教授程明明,主要研究方向是计算机视觉和图形学。
目前,E2FGVI的代码已经开源,作者也提供了Colab实现,未来还将在Hugging Face给出demo。
论文地址: https://arxiv.org/abs/2204.02663
GitHub主页: https://github.com/MCG-NKU/E2FGVI
审核编辑 :李倩
-
计算机视觉
+关注
关注
9文章
1714浏览量
47454 -
数据集
+关注
关注
4文章
1230浏览量
26046
原文标题:CVPR 2022 | 视频P图新SOTA:推理速度快近15倍,任意分辨率均可上演人像消失大法
文章出处:【微信号:CVSCHOOL,微信公众号:OpenCV学堂】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
DeepSeek最新论文:训练速度提升9倍,推理速度快11倍!

基于米尔MYC-LR3576开发板的实时视频识别系统设计与实现
谷歌芯片实现量子计算新突破,比超算快13000倍
今日看点:谷歌芯片实现量子计算比经典超算快13000倍;NFC 技术突破:读取距离从 5 毫米提升至 20 毫米
AURIX tc367通过 MCU SOTA 更新逻辑 IC 闪存是否可行?
求助,关于TC387使能以及配置SOTA 中一些问题求解
Groq LPU 如何让万亿参数模型「飞」起来?揭秘 Kimi K2 40 倍提速背后的黑科技
大模型推理显存和计算量估计方法研究
RK3588核心板在边缘AI计算中的颠覆性优势与场景落地
YOLOv5类中rgb888p_size这个参数要与模型推理和训练的尺寸一致吗?一致会达到更好的效果?
中国电提出大模型推理加速新范式Falcon






 工商网监
工商网监
评论