 i.MXRT上提升代码执行性能的十八般武艺
i.MXRT上提升代码执行性能的十八般武艺

今天给大家介绍的是在串口波特率识别实例里逐步展示i.MXRT上提升代码执行性能的十八般武艺。
恩智浦 MCU SE 团队近期一直在加班加点赶 SBL 项目(解决客户产品 OTA 需求),这个项目里集成了 ISP 本地升级(UART/USB)功能,其中 UART 口下载升级实现里加入了自动波特率识别支持,具体识别方法见 《串口(UART)自动波特率识别程序设计与实现(中断)》 一文,这一套 ISP 代码其实是移植于 i.MXRT Flashloader(更早期的时候叫 KBOOT)。
ISP 代码放在 SBL 工程里会出现高波特率(比如115200)无法识别的问题,但在低波特率的情况下(比如9600,19200),ISP 代码是功能正常的,说明代码本身并不存在逻辑缺陷,但高波特率下就异常了,大概率是遇到了代码执行性能瓶颈。今天痞子衡就尝试在 i.MXRT 上使用各种方法去提升性能来解决这个高波特率无法识别问题:
一、SBL项目里ISP串口高波特率识别问题
SBL 项目是支持全系列 i.MXRT 平台的,为了具体化问题,我们就选取 i.MXRT1062 型号为例,官方配套 MIMXRT1060-EVK 板子上搭配了一颗四线串行 NOR Flash(芯成IS25WP064A)用于存放代码。
SBL 程序主体是 XIP 执行的,仅部分涉及 IAP 操作的代码被分散加载到了 RAM 里。SBL 中 ISP 功能代码主体当然也是 XIP 为主,且在 SBL 程序里是最先执行的(本地升级超时后才进入 SBL 主体),SBL 工程里跟串口波特率识别相关的源文件一共如下三个:
microseconds_pit.c -- 存放 PIT 计时函数
autobaud_irq.c -- 存放 GPIO 中断回调、波特率识别计算函数
pinmux_utility_imxrt_series.c -- 存放 GPIO 配置与中断处理函数
MIMXRT1060-EVK 板子上串口是 GPIO1[13:12],其中 RXD - GPIO1[13] 是核心的用于波特率识别的引脚,为了便于直观地感受代码执行性能,我们用另一个 GPIO1[12] 来辅助,将其配置为 GPIO 输出模式,初值为高电平,在 GPIO 中断处理函数里保持低电平来标示执行总时间:
- Note :下述代码里中断处理函数实际上有点小缺陷,《中断处理函数(IRQHandler)的标准流程》 一文里给出了改进方法,但这里为了观察中断处理代码是否能在下一次中断来临前执行完毕特意舍弃了文中 2.2.2 小节里的改进)
voidGPIO1_Combined_0_15_IRQHandler(void)
{
//****辅助调试:进入中断时拉低 GPIO1[12],标志执行时间起点
GPIO1->DR&=(uint32_t)~(1U<< 12);
uint32_tinterrupt_flag=(1U<< 13);
//仅当GPIO1[13]下降沿中断发生时
if((GPIO_GetPinsInterruptFlags(GPIO1)&interrupt_flag)&&s_pin_irq_func)
{
//执行一次回调函数
s_pin_irq_func();
//清除GPIO1[13]中断标志
GPIO_ClearPinsInterruptFlags(GPIO1,interrupt_flag);
__DSB();
}
//****辅助调试:退出中断时拉高 GPIO1[12],标志执行时间结束
GPIO1->DR|=(1U<< 12);
}
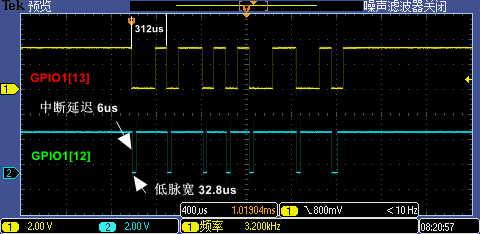
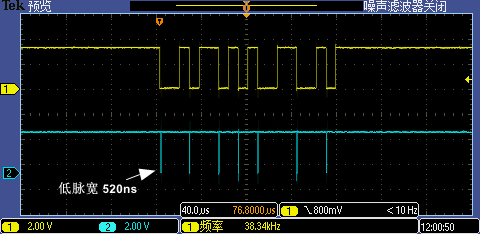
现在我们用示波器同时抓取 GPIO1[13:12] 信号,分别测试 9600 低波特率(下图一)和 115200 高波特率(下图二)下实际波形,根据测量第一次 GPIO 中断处理执行时间大概是 32.8us(7 次中断因代码分支执行不同略有区别),这个时间对于 9600 波特率下单 bit 传输耗时约 104us 的情况来说是足够快的,但是对于 115200 波特率下单 bit 传输耗时约 8.68us 的情况来说就显得有点慢了(最小的下降沿之间间隔是 2bit 传输耗时 17.36us ),这也是 115200 无法被识别的原因,因为有 4 个下降沿中断被漏掉了。
二、提升代码性能的多种方法
既然代码执行性能不够,那就努力提升性能,文章标题叫十八般武艺,这只是一种夸张说法,不过痞子衡确实收集了如下六种提升性能的方法,让我们一一尝试吧,注意下述结果都是叠加前面方法而得的(所有测试均是在 115200 波特率下进行)。
Level 1:提升CPU主频
ISP 功能代码里配置的 CPU 主频是 396MHz,实际上这是根据 BootROM 默认运行配置而来的,而 i.MXRT1062 是可以跑到 600MHz 主频的,将 SDK 代码里 armPllConfig_BOARD_BootClockRUN.loopDivider 由 66 调大到 100 即可。
constclock_arm_pll_config_tarmPllConfig_BOARD_BootClockRUN={
.loopDivider=100,/*PLLloopdivider,Fout=Fin*50*/
.src=0,/*Bypassclocksource,0-OSC24M,1-CLK1_PandCLK1_N*/
};
voidBOARD_BootClockRUN(void)
{
//...
CLOCK_SetDiv(kCLOCK_AhbDiv,0);
CLOCK_SetDiv(kCLOCK_ArmDiv,1);
CLOCK_InitArmPll(&armPllConfig_BOARD_BootClockRUN);
CLOCK_SetMux(kCLOCK_PrePeriphMux,3);
CLOCK_SetMux(kCLOCK_PeriphMux,0);
//...
}
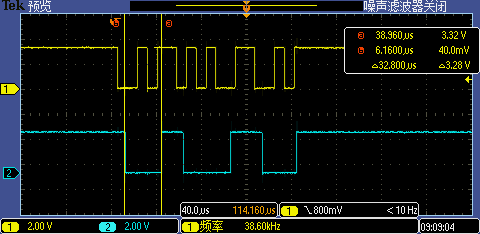
CPU 主频提升后第一次 GPIO 中断处理执行时间从 32.8us 下降到了 32.2us,性能仅有微小提升,看来此时主要性能瓶颈不在 CPU 主频上,应该是 Flash 访问性能在拖后腿。
Level 2:提升Flash访问速度
SBL 工程里启动头 FDCB 配置的是 100MHz Flash 工作频率,但 MIMXRT1060-EVK 板载 Flash(芯成IS25WP064A)最大工作频率是 133MHz,所以我们可以提升 Flash 工作频率。修改 qspiflash_config.memConfig.serialClkFreq 为 kFlexSpiSerialClk_133MHz 即可。不了解 FDCB 结构体工作机制的可以翻阅痞子衡旧文 《从头开始认识i.MXRT启动头FDCB里的lookupTable》 。
constflexspi_nor_config_tqspiflash_config={
.memConfig=
{
.tag=FLEXSPI_CFG_BLK_TAG,
.version=FLEXSPI_CFG_BLK_VERSION,
.readSampleClkSrc=kFlexSPIReadSampleClk_LoopbackFromDqsPad,
.csHoldTime=3u,
.csSetupTime=3u,
.sflashPadType=kSerialFlash_4Pads,
//.serialClkFreq=kFlexSpiSerialClk_100MHz,
.serialClkFreq=kFlexSpiSerialClk_133MHz,
.sflashA1Size=8u*1024u*1024u,
.lookupTable=
{
FLEXSPI_LUT_SEQ(CMD_SDR,FLEXSPI_1PAD,0xEB,RADDR_SDR,FLEXSPI_4PAD,0x18),
FLEXSPI_LUT_SEQ(DUMMY_SDR,FLEXSPI_4PAD,0x06,READ_SDR,FLEXSPI_4PAD,0x04),
},
},
.pageSize=256u,
.sectorSize=4u*1024u,
.blockSize=64u*1024u,
.isUniformBlockSize=false,
};
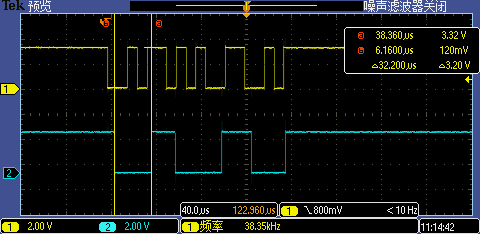
Flash 工作频率提升后第一次 GPIO 中断处理执行时间从 32.2us 下降到了 27.8us,这次的性能提升算有点明显了,但是还是不够,解决不了问题。
Level 3:配置FlexSPI至最优模式
让我们继续从 Flash 传输模式上做文章,ISP 功能代码里配置的是普通 SPI 下 Fast Read Quad I/O SDR Non-Continuous 工作模式,这个模式已经算是非常高效的传输模式了,如果还想改进,要么是切换到 QPI 模式(将 CMD 子序列也从一线变到四线)要么是使能 Continuous Read(除了第一个 CMD 子序列,其后 CMD 子序列全部省掉),综合考虑应该是使能 Continuous Read 性能提升更大一些,具体方法参考 《在i.MXRT启动头FDCB里使能串行NOR Flash的Continuous read模式》。
constflexspi_nor_config_tqspiflash_config={
.memConfig=
{
//...
.lookupTable=
{
FLEXSPI_LUT_SEQ(CMD_SDR,FLEXSPI_1PAD,0xEB,RADDR_SDR,FLEXSPI_4PAD,0x18),
//FLEXSPI_LUT_SEQ(DUMMY_SDR,FLEXSPI_4PAD,0x06,READ_SDR,FLEXSPI_4PAD,0x04),
//插入JUMP_ON_CS子序列
FLEXSPI_LUT_SEQ(MODE8_SDR,FLEXSPI_4PAD,0xA0,DUMMY_SDR,FLEXSPI_4PAD,0x04),
FLEXSPI_LUT_SEQ(READ_SDR,FLEXSPI_4PAD,0x04,JMP_ON_CS,FLEXSPI_1PAD,0x01),
},
},
//...
};
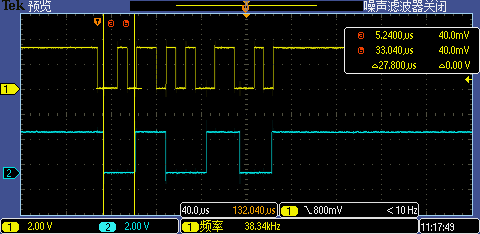
使能 Flash Continuous Read 后第一次 GPIO 中断处理执行时间从 27.8us 下降到了 27.4us,性能仅有微小提升,这应该跟我们使能了 FlexSPI prefetch 特性有关,1KB AHB RX Buffer 的存在导致 CMD 子序列在总传输时序中占比不明显。不过有点收获的是漏掉的下降沿中断从 4 个减少到了 3 个。
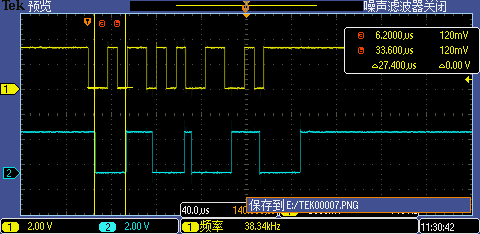
Level 4:打开L1 Cache
对于 XIP 工程来说,不开 L1 I-Cache 加速性能是非常吃亏的一件事,i.MXRT1062 内部有 32KB I-Cache,不把这个 Cache 用起来简直是暴殄天物。虽然工程 SystemInit() 函数里会执行一次 SCB_EnableICache(),但这只是一个 Cache 总开关,要想 Cache 对 Flash 映射地址(0x60000000 之后)产生作用还得借助 BOARD_ConfigMPU() 函数来具体配置 MPU。关于 Cache 对 Flash 读取的性能提升见 《实抓Flash信号波形来看i.MXRT的FlexSPI外设下AHB读访问情形(全加速)》 。
intmain(void)
{
//将MPU配置提到ISP代码之前
BOARD_ConfigMPU();
#if(defined(COMPONENT_MCU_ISP))
boolisInfiniteIsp=false;
isp_boot_main(isInfiniteIsp);
#endif
//BOARD_ConfigMPU();
//...
}
使能 Cache 后第一次 GPIO 中断处理执行时间从 27.4us 下降到了 19us,后面的 GPIO 中断执行耗时更是大大缩短(原因是中断处理函数相关代码在第一次中断触发执行时被顺便放到 Cache 里了),这时候 115200 高波特率已经能够被正常识别了。
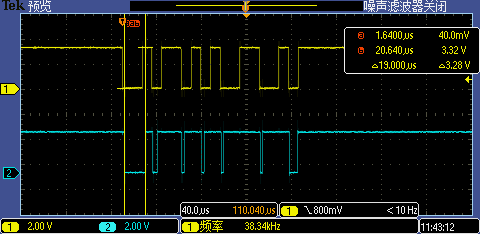
到这里问题已经解决了,但我们还没有榨干 MCU 最后一滴血,优化继续。上图波形里第一次 GPIO 中断处理执行时间相比其后面的 6 次中断执行耗时要明显长,这还是有风险的,比如再高的波特率 256000 还是无法正常识别(至少第一次识别会失败,后面上位机再重复发暗号做第二次识别就可以了)。为了让第一次 GPIO 中断处理时间也大大缩短,我们可以在系统初始化的时候故意调用一下这些中断处理相关函数,将这些代码事先装载到 I-Cache里。
voidautobaud_init(void)
{
s_transitionCount=0;
s_firstByteTotalTicks=0;
s_secondByteTotalTicks=0;
s_lastToggleTicks=0;
s_ticksBetweenFailure=microseconds_convert_to_ticks(kMaximumTimeBetweenFallingEdges);
enable_autobaud_pin_irq(pin_transition_callback);
//故意调用一下,让I-Cache事先将代码Cache住
GPIO1_Combined_0_15_IRQHandler();
pin_transition_callback();//即第一节代码中的s_pin_irq_func()
}
将中断处理函数相关代码预装载到 I-Cache 后第一次 GPIO 中断处理执行时间从 19us 锐降到了 2.12us,跟其他中断处理执行差不多的耗时,现在即使是 256000 高波特率也能一次识别成功。
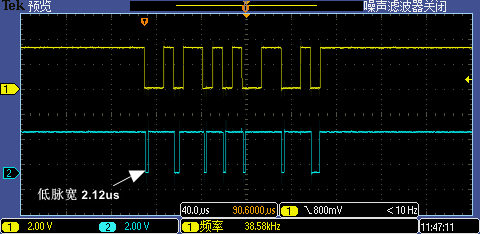
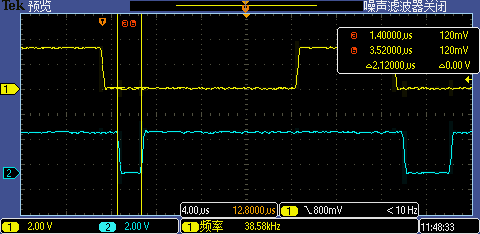
Level 5:拷贝到TCM里
靠 Cache 这种无法精准控制的优化策略始终让我们无法放心,还是将中断处理相关代码直接放到 TCM 里更可靠,我们在工程链接文件(MIMXRT1062xxxxx_flexspi_nor.icf)里做如下修改将第一节里列出了三个源文件全部弄到 RAM 区里执行(对于 XIP 工程来说,RAM 区是 DTCM, 当然对于代码来说 ITCM 效率要更高,不过 DTCM 也够用了)。
initialize by copy {
readwrite,
/* Place in RAM flash and performance dependent functions */
object microseconds_pit.o,
object autobaud_irq.o,
object pinmux_utility_imxrt_series.o,
// ...
section .textrw
};
do not initialize { section .noinit };
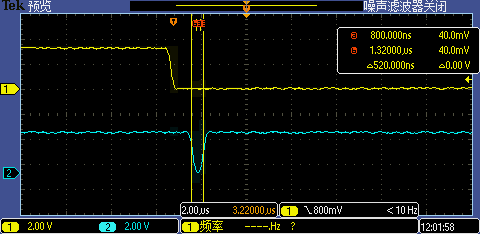
将中断处理函数相关代码重定位到 DTCM 执行后第一次 GPIO 中断处理执行时间从 2.12us 再降到了 520ns,这下 1M 超高波特率也能被识别了。
Level 6:指定函数地址以八字节对齐
性能提升结束了吗?痞子衡还有一招,参见 《链接函数到8字节对齐地址或可进一步提升i.MXRT1xxx内核执行性能》 一文,将中断处理相关函数全部链接到八字节对齐地址还可以再利用 Cortex-M7 内核指令双发射特性。我们查看下工程映射文件(sbl.map),三个相关函数仅有计时函数 microseconds_get_ticks() 被自动分配到了八字节对齐的地址,其他两个函数不是,所以还有提升空间。
Entry Address Size Type Object
;---- ------- ---- ---- ------
GPIO1_Combined_0_15_IRQHandler
0x2000'0b2f 0x3e Code Gb pinmux_utility_imxrt_series.o [1]
pin_transition_callback 0x2000'0175 0x8e Code Gb autobaud_irq.o [1]
microseconds_get_ticks 0x2000'08e9 0x22 Code Gb microseconds_pit.o [1]
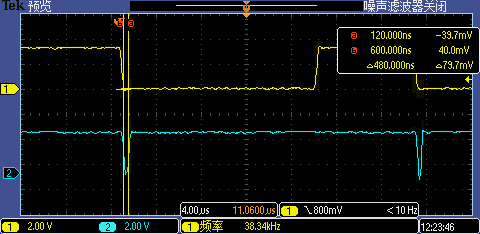
将非八字节地址对齐的中断处理相关函数调整到八字节地址对齐后(具体方法这里就不展开介绍了),第一次 GPIO 中断处理执行时间从 520ns 降到了 480ns,这几乎是性能极限了。
至此,在串口波特率识别实例里逐步展示i.MXRT上提升代码执行性能的十八般武艺痞子衡便介绍完毕了,掌声在哪里~~~
审核编辑 :李倩
-
波特率
+关注
关注
2文章
320浏览量
35721 -
代码
+关注
关注
30文章
4985浏览量
74595
原文标题:提升MCU代码执行性能的十八般武艺
文章出处:【微信号:mcu168,微信公众号:硬件攻城狮】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
探秘LTC1694 - 1:提升SMBus/I²C性能的利器
LTC1694 SMBus/I²C加速器:提升数据传输性能的利器
MXRT1041XJM5B MCU 无复位处理程序无法执行
i.MXRT1173跨界处理器能支持2GB NOR闪存吗?
全能智慧守护:沐渥揭秘下一代氮气柜控制板,如何用“十八般武艺”重塑晶圆安全存储新标杆

i.MXRT1064无法通过串行连接到MCU Boot Utility怎么解决?
不止控能耗!安科瑞智慧能源方案十八般武艺覆盖全场景

单片机程序的执行
从代码执行看单片机内存的分配
恩智浦i.MXRT1180的FlexSPI NOR启动连接方式

Arm Neoverse CPU上大代码量Java应用的性能测试

戴尔PowerEdge R7715服务器性能评测

第十八章 I2C通信测试
多个i.MXRT共享一颗Flash启动的方法与实践(下)

多个i.MXRT共享一颗Flash启动的方法与实践(上)



评论