 腾讯广告视频抽帧的全流程GPU加速
腾讯广告视频抽帧的全流程GPU加速

案例简介
腾讯广告的开发人员改进了视频抽帧的实现方式,使得全流程的操作均在 GPU 上完成,取代了原有的 CPU 抽帧流程,提高了性能,并降低了成本。
本案例涉及 GPU 加速的视频解码与图像处理
线上测试集显示,单个 GPU 的视频解码算力与 8 个 CPU 核大致相当
GPU 做图像处理比 CPU 更有性能和成本优势,尤其与 GPU 视频解码联合使用时
本案例使用了 NVIDIA T4 GPU 以及相关软件
客户简介及应用背景
视频已成为内容和广告的主要媒介形式,但目前的视频内容理解或审核等 AI 能力,主流依然是先抽帧,再基于图像帧做特征提取和预测。
腾讯广告部门日常处理大量的视频信息,而抽帧是视频分析的第一步。抽帧由于步骤多、计算重,在视频 AI 推理场景很容易成为性能瓶颈。
客户挑战
在腾讯广告的流量中,视频所占比例逐年快速提升,视频抽帧这里如果出现时耗或吞吐瓶颈(特别是针对高 FPS 抽帧的情况),很容易影响到后续的特征提取以及模型预测性能。在当前的广告视频 AI 推理服务中,抽帧往往占据了其中大部分时耗,因此,视频抽帧的性能对于视频内容理解服务的时耗和整体资源开销,有着举足轻重的地位。
视频抽帧的几个步骤,计算量非常大,传统的 CPU 方式抽帧往往受限于 CPU 整体的计算吞吐,很难满足低时延高性能要求。因此,使用 GPU 加速等手段,来对视频抽帧做极致的性能优化是必然。
应用方案
NVIDIA GPU 具备单独的硬件编解码计算单元,从早期发布的 Maxwell 架构到最新的 Ampere 架构,都有完善的 API 支持,并且 GPU 上为数众多的 CUDA 核心也特别适用于图像数据并行处理加速。目前广泛使用的推理芯片 NVIDIA T4 GPU,包含两个独立于 CUDA 的解码单元,且支持大部分主流的视频格式,是本案例的应用型号。
视频抽帧流程大体上包括以下几个步骤:视频解码、帧色彩空间转换、落盘方式的 JPEG 编码,如果非落盘,则对解码出来的视频帧做预处理,然后交给模型进行特征提取或预测。
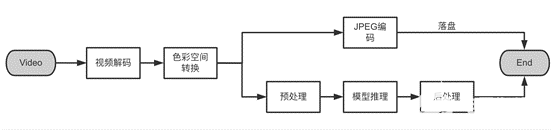
其中帧色彩空间转换、JPEG 编码都涉及像素级别计算,非常适合使用 GPU CUDA kernel 来做并行计算加速。此外,视频解码后得到的帧都是未经压缩的原始数据,数据量很大,如果解码是在 CPU 上进行,或者 GPU 解码后自动传回了 CPU,则需要频繁做 device(显存)与 host(主存)之间的原始帧数据来回拷贝,IO 时耗长且数据带宽拥塞,导致时延明显增加。 因此,该方案的主要目标是尽可能减少 host 与 device 间的数据 IO 交换,做到抽帧过程全流程 GPU 异构计算,充分利用 NVIDIA GPU 自带的硬件解码单元 NVDEC,最大限度减少视频解码对于 CPU 以及 GPU CUDA 核心占用的同时,尽可能低延时、高吞吐地处理视频抽帧以及后续的模型推理。
具体来说,本方案主要从计算和 IO 两个方面着手,解码部分充分利用了 GPU 通常闲置的 NVDEC 解码器,其他步骤以像素或像素块计算为主,因此使用 CUDA kernel 做并行加速。IO 方面,由于中间过程是原始帧,GPU 数据带宽有限,该方案实现了全流程 CPU 和 GPU 无帧数据交换,最大程度提升性能和吞吐,确保视频 AI 推理服务的 GPU 利用率。
计算优化
1. 硬解码
当前线上主力的 GPU 推理卡 T4、P40,以及后续即将升级的 A 系列,主流的视频编码格式基本都已支持,各卡型支持的具体格式如下:
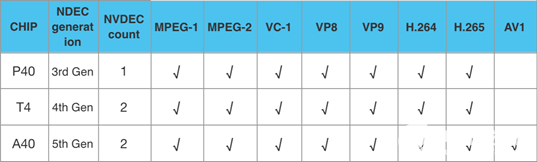
调用 GPU 硬解码主要有两种方式,一种是直接使用 NVIDIA 官方提供的 Video Codec SDK,另一种方式是使用 FFmpeg,其已经封装了对 GPU 硬解码的支持。考虑到目前 T4 GPU 对视频格式的支持还不够完善,因此本文使用的是 FFmpeg 方式,如果遇到 GPU 不支持的视频格式,只需修改解码器类型即可快速降级到 CPU 解码方案,CPU 和 GPU 两种模式抽帧的代码逻辑也较为统一。
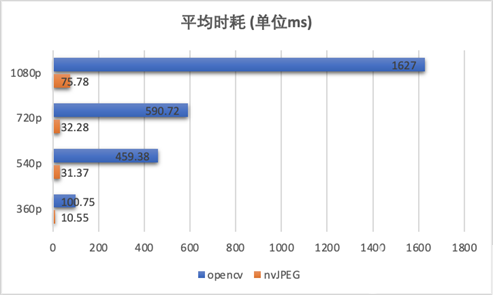
以下分别以 FFmpeg CPU 4、8、16 线程,以及 GPU 硬解码方式,抽取线上 100 个广告视频做离线测试,平均时耗对比如下(CPU 为 2020 年发布的主流服务器 CPU):
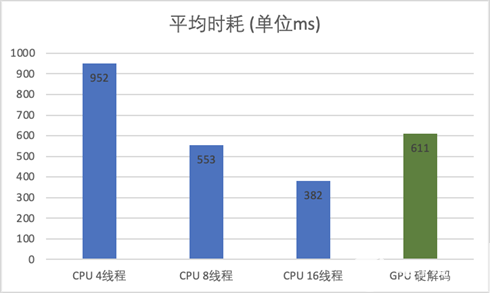
注:视频平均大小约 15M,平均时长 26s,大部分为 720P 视频;FFmpeg 建议最大解码线程数 16
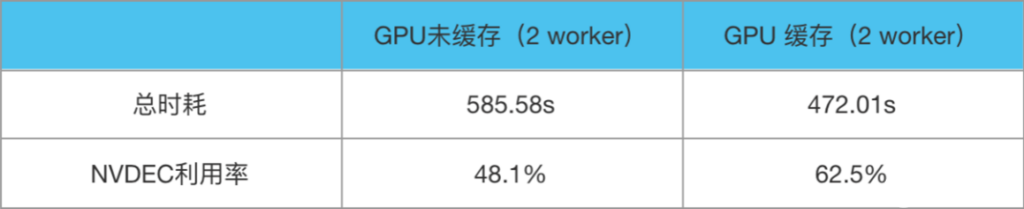
分配给 GPU 模型推理服务的 CPU 核数一般不会太多,因此以 FFmpeg 8 线程、2 worker(在本文中是指单进程多实例的方式)做性能压测,1000 个广告视频测试数据如下:

由此可见,在 GPU 线上推理环境,如果充分利用 T4 GPU 2 个 NVDEC 硬件解码模块,可在几乎不影响线上服务 CPU、CUDA 原有 workloads 计算的情况下,额外增加一倍解码算力,抽帧 QPS 可在原有基础上翻倍。此处应注意,不同架构 GPU 所附带的 NVDEC 硬解模块数不同,并且 NVDEC 不支持外部再用多线程操作解码,应当根据 NVDEC 模块数选择正确的多实例多 worker 进行解码。例如 T4 GPU 有 2 个 NVDEC 硬解码模块,如果只用单实例,则硬解模块利用率将不会超过 50%。如果服务对吞吐的要求高于时延,则此处 GPU 硬解码的 worker 数可以设为大于 n,充分压榨硬件解码模块。
2. CUDA 色彩空间转换
视频解码后得到的帧为 YUV 格式,而通常模型预测或其他后续处理一般需要 RGB/BGR 像素格式,因此需要做一次色彩空间转换,将 YUV 帧转换为模型需要的 RGB 格式。传统方式是调用 FFmpeg 的 swscale 模块来实现,但是该方式只支持在 CPU 进行计算,需要做一次 device 到 host 的数据 IO,并且非常消耗 CPU 资源,计算并行度也不高。统计发现,swscale 计算耗时占比接近 40%。
YUV 到 RGB 格式的转换是 3×3 的常量矩阵与 YUV 三维向量相乘,即逐像素地将明度 Y、色度 U、浓度 V 三个分量按公式线性变换为 R、G、B 三色值(这里的常量矩阵的值取决于视频所采用的颜色标准,比如 BT.601/BT.709/BT.2020,可参见 Video Codec SDK 里面的示例),因此可以很方便地将计算过程改为一维或二维线程块的 CUDA kernel 调用,充分利用 GPU 数以千记的 CUDA 核心并行计算来做提速。
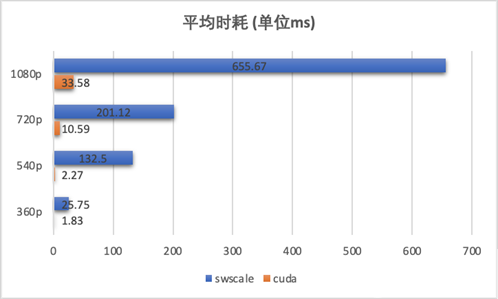
**性能:**对线上 100 个广告视频做性能对比评测,CUDA kernel 调用相对于 CPU 的 swscale 方式平均提速在 20 倍以上,并且视频清晰度越高,优势越明显。
3. CUDA JPEG 编码
如果是在视频预处理等场景,则需要对抽帧结果做 JPEG 编码后再落盘保存。JPEG 编码具体流程如下:

虽然不同于色彩空间转换的逐像素操作,但也是将整张图片划分为 8×8 像素的小分块分别进行离散余弦变换、量化、Huffman 编码等处理,同样非常适合用 GPU CUDA core 计算单元来做并行加速。NVIDIA 从 CUDA Toolkit 10 开始也已经封装了 nvJPEG 模块提供 JPEG 编码能力。
需要说明的是,使用 GPU 做 JPEG 编码,与 CPU JPEG 编码存在一定比例的像素差异。确保 JPEG 文件头中各项参数一致的情况下(压缩质量、量化表、Huffman 表均相同),实测像素差异比在 0.5% 左右。由于 JPEG 编码为有损压缩,因此解码后依然存在像素差异,有可能导致模型给出的预测结果存在偏差。例如 OCR 的目标检测模块,分别使用 CPU 和 GPU 编码的 JPEG 图像作为输入,预测得到的检测框坐标值在部分 case 上存在一定偏差,从而有概率导致文字识别结果出现不一致。一种可行的解决方案,是模型训练也使用 GPU JPEG 编码的图片作为输入,保证模型训练和推理的输入一致性,从而确保模型推理效果。
**性能:**实测线上 1000 个广告视频,CUDA 方式 JPEG 编码约有 15~20 倍性能提升,同样清晰度越高性能优势越大:
IO优化
FFmpeg 使用 GPU 硬解码后,得到的视频帧格式为 AV_PIX_FMT_NV12,通过 NVIDIA 提供的 cudaPointerGetAttributes API 做指针类型检查,为 Host 端内存指针。也就是说调用 NVDEC 模块解码后,默认对视频帧做了一次 device 到 host 的传输。
由于这里的视频帧均为未压缩的原始像素帧,且原始视频的所有 FPS 帧都会做该处理,会占用大量 GPU 与 host 端内存的数据带宽。若有办法做到 GPU 硬解后的视频帧,不默认传回到 host 端,而是直接缓存在显存等待后续计算,则可以无缝对接后续的模型推理或 JPEG 落盘,省去 device 与 host 端的来回两次数据交换时耗,且大幅减轻 GPU 与 CPU 间的数据 IO 吞吐压力。
为此,可使用 FFmpeg 的 hwdevice 相关接口,直接得到显存中的视频帧。这样得到的视频帧格式变为 AV_PIX_FMT_CUDA,且 Y 和 UV plane 的 data linesize 也由 1088 变为 1280,使用时需要注意。此时使用 cudaPointerGetAttributes 检查 frame data 指针类型,已经是 device 端指针,由此打通了全流程异构抽帧的关键一环。
通过 NVIDIA Nsight Systems 抓取到的性能数据可见,cudaMemcpy 由之前的 DtoH & HtoD 来回传输变为一次显存内部的 DtoD,时耗由 173ms x 2 变为 25ms,吞吐也有不少提升。此外,CUDA kernel 计算时间片的连续性也得到不少改善。
**性能:**实测线上 1000 个广告视频,整体性能相较于非硬件缓冲区方式有 25% 左右的提升,GPU 硬解码器 NVDEC 资源利用率提升约 30%。
工程优化
本文以介绍 GPU 全流程抽帧方案为主,过程中为了把性能做到极致也涉及到一些工程优化:
通过显存预分配+复用、AVHWDeviceContext 缓冲区 & JPEG 编码器复用等手段,单次抽帧时耗可再优化百 ms 级别。
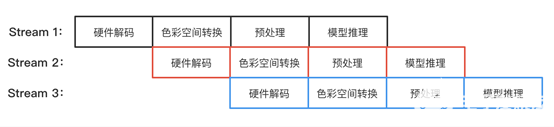
将 NVDEC 硬解码、色彩空间转换、JPEG 编码、模型推理等步骤,利用 CUDA 多流,并对每个环节做 Pipeline overlap 并行化处理,可充分释放每个步骤的最大计算性能,进一步提升计算吞吐和资源利用率。
目前有不少算法服务是基于 Python 进行开发&部署,本方案为保障高性能,使用 C++ 开发。通过 pybind11 基于 C++ 封装 Python 抽帧 API,保障算法开发部署的灵活性与效率的同时,确保高性能的抽帧能力。
不落盘方式,对接模型推理之前一般需要先做预处理操作,如果要做到全流程 GPU,需要将预处理改写为 CUDA kernel 调用。这里可以将常用的 CV 类预处理操作封装为 CUDA 基础函数库,也可以使用 NVIDIA 已经封装好的 NPP 模块、DALI 预处理加速框架等方案。
使用效果及影响
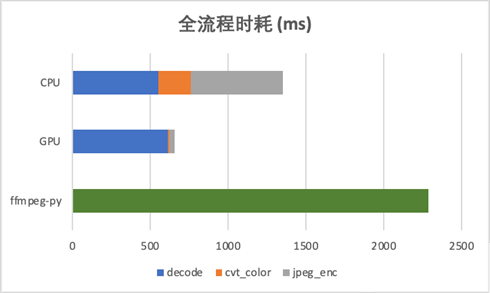
全流程时耗对比:
相较于 CPU 8 线程解码,全流程有一倍左右的速度优势,并且由于几乎不占用 PCIe 数据带宽,对模型推理等 device&host 间数据 IO 基本无影响,在吞吐上也有不少提升。
相较于 Python 算法常用的 ffmpeg-python 方式,有数倍性能提升。
视频抽帧优化是视频 AI 推理优化中的重要一环,本方案从 GPU 硬件加速的角度出发,分别针对抽帧各步骤做性能分析&计算优化,解决了中间过程大数据量的原始视频帧 host 与 device 端数据 IO 交换问题,避免 GPU 与 CPU 间的 PCI-E 数据带宽瓶颈,真正做到全流程 GPU 异构抽帧。基于此,可在 GPU 无缝对接后续的模型推理(不落盘)以及 JPEG 编码(落盘)两种主流的抽帧使用场景,是实现全流程 GPU 视频 AI 推理能力的先决条件。同时,充分利用了 GPU 推理环境通常闲置的 NVDEC 解码芯片,对于整体服务时耗、吞吐,以及硬件资源利用率均有不错的提升,降低了视频 AI 推理服务 GPU/CPU 算力成本,在算力紧缺的 AI2.0 时代有着非常重要的意义。
目前该方案已在腾讯广告多媒体 AI 的视频人脸服务落地,解决了其最主要的抽帧性能瓶颈,满足广告流水对于服务的性能要求。更多视频 AI 算法,特别是高 FPS 抽帧场景也在逐步接入优化中。
“目前该方案已在腾讯广告多媒体 AI 的视频人脸服务落地,解决了其最主要的抽帧性能瓶颈,满足广告流水实时处理对于服务的性能要求。更多腾讯内部视频 AI 算法,特别是高 FPS 抽帧场景也在逐步接入优化中。后续,我们还将与英伟达一起,探索视频抽帧与模型推理的最佳结合方式,力求实现视频AI推理的极致性能。”
向乾彪,腾讯广告AI工程架构师,GPU视频抽帧项目负责人
审核编辑:郭婷
-
cpu
+关注
关注
68文章
11330浏览量
225904 -
gpu
+关注
关注
28文章
5272浏览量
136070 -
AI
+关注
关注
91文章
41156浏览量
302611
发布评论请先 登录
GPU负重前行:一组实验看懂视频色彩空间转换的真相

基于openEuler平台的CPU、GPU与FPGA异构加速实战

NVIDIA携手全球工业软件巨头构建AI智能体加速设计与工程开发流程
RSoft GPU加速技术重塑光子元件设计效率革命

灌封胶气泡消除技巧:搅拌+抽真空+固化全流程排气消泡方法 | 铬锐特实业

沐曦股份GPU加速技术助力药物研发降本增效
工业级-专业液晶图形显示加速器RA8889ML3N简介+显示方案选型参考表
FPGA和GPU加速的视觉SLAM系统中特征检测器研究


GPU 维修进度一键 “秒查”~捷智算GPU维修数字化系统全新上线!

NVIDIA助力枢途科技突破视频提取具身数据技术鸿沟
基于米尔全志T536开发板的视频识别应用方案



评论