 深入剖析Linux内核虚拟文件系统
深入剖析Linux内核虚拟文件系统

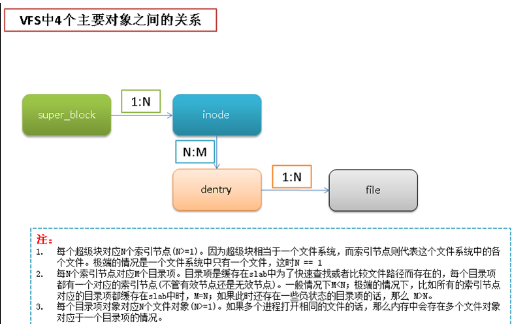
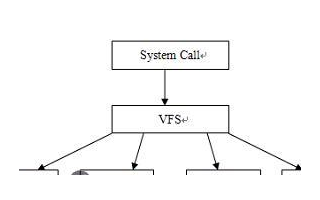
虚拟文件系统(Virtual File System,简称VFS)是Linux内核的子系统之一,它为用户程序提供文件和文件系统操作的统一接口,屏蔽不同文件系统的差异和操作细节。借助VFS可以直接使用open()、read()、write()这样的系统调用操作文件,而无须考虑具体的文件系统和实际的存储介质。
通过VFS系统,Linux提供了通用的系统调用,可以跨越不同文件系统和介质之间执行,极大简化了用户访问不同文件系统的过程。另一方面,新的文件系统、新类型的存储介质,可以无须编译的情况下,动态加载到Linux中。
"一切皆文件"是Linux的基本哲学之一,不仅是普通的文件,包括目录、字符设备、块设备、套接字等,都可以以文件的方式被对待。实现这一行为的基础,正是Linux的虚拟文件系统机制。
VFS之所以能够衔接各种各样的文件系统,是因为它抽象了一个通用的文件系统模型,定义了通用文件系统都支持的、概念上的接口。新的文件系统只要支持并实现这些接口,并注册到Linux内核中,即可安装和使用。
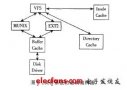
举个例子,比如Linux写一个文件:
int ret = write(fd, buf, len);
调用了write()系统调用,它的过程简要如下:
首先,勾起VFS通用系统调用sys_write()处理。
接着,sys_write()根据fd找到所在的文件系统提供的写操作函数,比如op_write()。
最后,调用op_write()实际的把数据写入到文件中。
操作示意图如下:
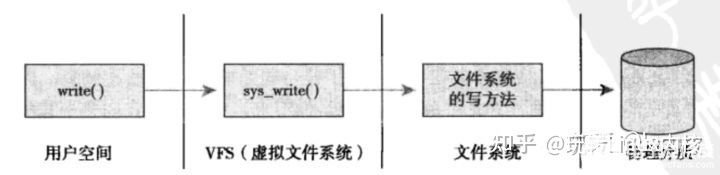
文件系统
Linux下常用文件系统介绍
-
swap 文件系统
swap文件系统用于Linux的交换分区。在Linux中,使用整个交换分区来提供虚拟内存,其分区大小一般应是系统物理内存的2倍,在安装Linux操作系统时,就应创建交换分区,它是Linux正常运行所必需的,其类型必须是swap,交换分区由操作系统自行管理 - Btrfs 文件系统
-
Ext系列文件系统
ext是第一个专门为Linux设计的文件系统类型,称为扩展文件系统。目前已经到了第四版分别是ext2, ext3,ext4 其中 centOS6默认是ext4文件系统 - xfs 文件系统
- NFS文件系统
- FAT系列文件系统
比较
| 文件系统 | 最大文件名长度 | 最大文件大小 | 最大分区大小 |
| ext2 | 255 bytes | 2 TB | 16 TB |
| ext3 | 255 bytes | 2 TB | 16 TB |
| ext4 | 255 bytes | 16 TB | 1 EB |
| XFS | 255 bytes | 8 EB | 8 EB |
| Btrfs | 255 bytes | 16 EB | 16 EB |
选择
| 文件系统 | 适用场景 | 原因 |
| ext2 | U盘 | U盘一般不会存很多文件,且U盘的文件在电脑上有备份,安全性要求没那么高,由于ext2不写日志(journal),所以写U盘性能比较好。当然由于ext2的兼容性没有fat好,目前大多数U盘格式还是用fat |
| ext3 | 对稳定性要求高的地方 | 有了ext4后,好像没什么原因还要用ext3,ext4现在的问题是出来时间不长,还需要一段时间变稳定 |
| ext4 | 小文件较少 | ext系列的文件系统都不支持inode动态分配,所以如果有大量小文件需要存储的话,不建议用ext4 |
| xfs | 小文件多或者需要大的xttr空间,如openstack swift将数据文件的元数据放在了xttr里面 | xfs支持inode动态分配,所以不存在inode不够的情况,并且xttr的最大长度可以达到64K |
| btrfs | 没有频繁的写操作,且需要btrfs的一些特性 | btrfs虽然还不稳定,但支持众多的功能,如果你需要这些功能,且不会频繁地写文件,那么选择btrfs |
【文章福利】小编推荐自己的Linux内核技术交流群:【865977150】整理了一些个人觉得比较好的学习书籍、视频资料共享在群文件里面,有需要的可以自行添加哦!!
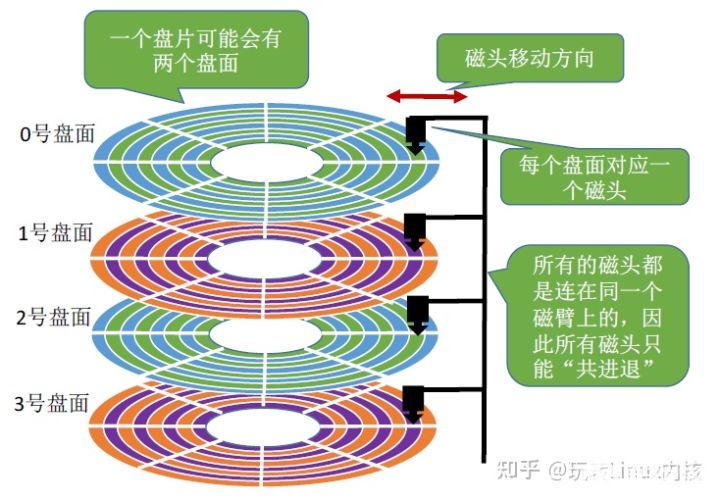
磁盘的组成原理
除了固态硬盘之外,硬盘一般都由磁盘、主轴马达、磁头臂、磁头、永磁铁等部分组成。
盘片
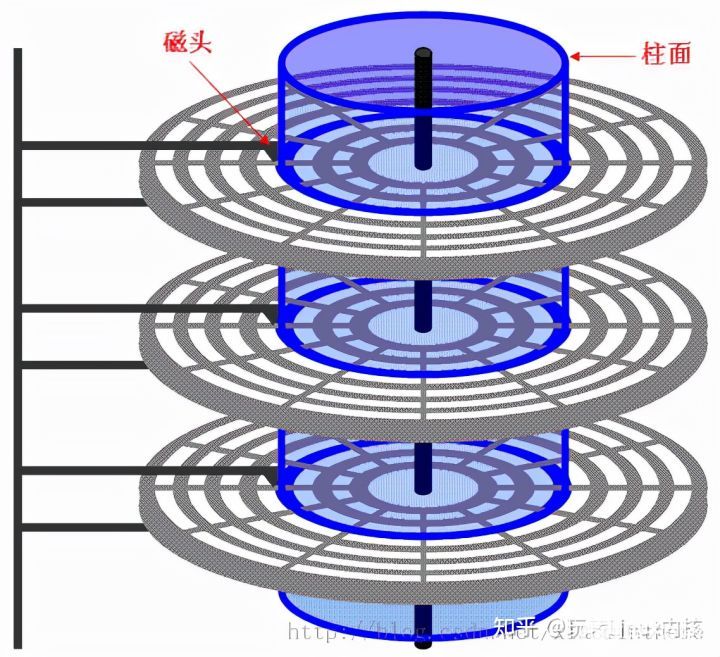
盘片的表面涂有磁性物质,这些磁性物质用来记录二进制数据。因为正反两面都可涂上磁性物质,故一个盘片可能会有两个盘面,硬盘的存储介质是磁性材料,磁头通过电流改变磁盘的磁性来存储数据。硬盘在逻辑上被划分为磁道、柱面以及扇区。
扇区,磁道
每个盘片被划分为一个个磁道,每个磁道又划分为一个个扇区。如下图:
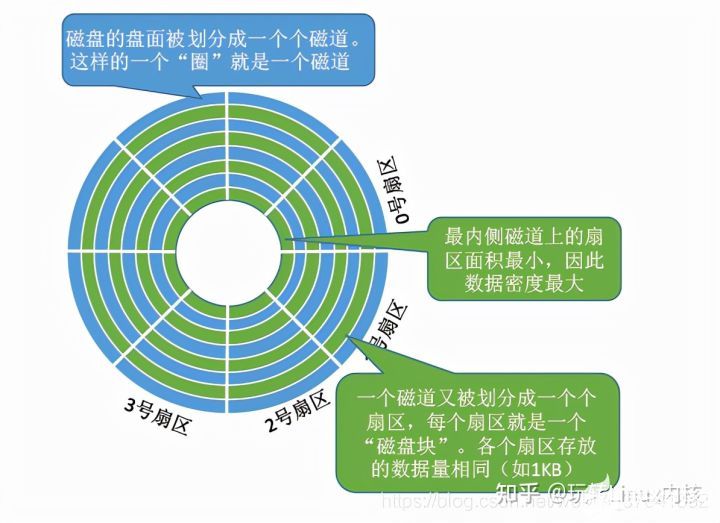
其中,最内侧磁道上的扇区面积最小,因此数据密度最大。
柱面
硬盘通常由重叠的一组盘片构成,每个盘面都被划分为数目相等的磁道,并从外缘的“0”开始编号,具有相同编号的磁道形成一个圆柱,称之为磁盘的柱面。
分区
为什么要对硬盘进行分区呢?
因为我们必须要告诉操作系统:这块硬盘可以访问的区域是从 A 柱面到 B 柱面。如此一来,操作系统才能控制硬盘磁头去 A-B 范围内的柱面上访问数据。如果没有告诉操作系统这些信息,它就无法在磁盘上存取数据。所以对磁盘分区的要点是:记录每一个分区的起始与结束柱面。 实际上,分区时指定的开始和结束位置是柱面上的扇区(sector):
下面我们以CentOS7 为例来看一下分区情况:
[root@CentOS7 ~]# fdisk -l
磁盘 /dev/sda:21.5 GB, 21474836480 字节,41943040 个扇区
Units = 扇区 of 1 * 512 = 512 bytes
扇区大小(逻辑/物理):512 字节 / 512 字节
I/O 大小(最小/最佳):512 字节 / 512 字节
磁盘标签类型:dos # 使 用dos---MBR 分区方式
磁盘标识符:0x000ce1c0
设备 Boot Start End Blocks Id System
/dev/sda1 * 2048 2099199 1048576 83 Linux
/dev/sda2 2099200 41943039 19921920 8e Linux LVM(逻辑卷)
# sda 分区
磁盘 /dev/mapper/centos-root:18.2 GB, 18249416704 字节,35643392 个扇区
Units = 扇区 of 1 * 512 = 512 bytes
扇区大小(逻辑/物理):512 字节 / 512 字节
I/O 大小(最小/最佳):512 字节 / 512 字节
# 交换分区
磁盘 /dev/mapper/centos-swap:2147 MB, 2147483648 字节,4194304 个扇区
Units = 扇区 of 1 * 512 = 512 bytes
扇区大小(逻辑/物理):512 字节 / 512 字节
I/O 大小(最小/最佳):512 字节 / 512 字节
分区的组成结构
MBR
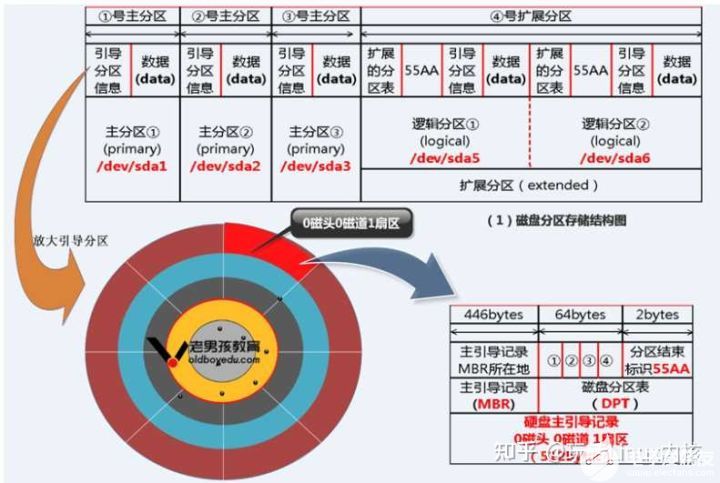
那么,这些分区的信息(起始柱面与结束柱面)被存放在磁盘的主引导区(Master Boot Recorder, MBR)。MBR 在一块硬盘的第 0 轨上,这也是计算机启动之后要去使用硬盘时必须读取的第一个区域。
这个区域内记录了硬盘里所有分区的信息即磁盘分区表,以及启动时可以写入引导程序的位置。因此 MBR 对于硬盘来说至关重要,如果它坏掉了,这块磁盘也就寿终正寝了。
主引导记录由三个部分组成:
- 引导程序占用其中的前446字节(偏移0~1BDH)
- 随后的64字节(偏移1BEH~1FDH)为DPT(Disk Partition Table,硬盘分区表)
- 最后的两个字节“55 AA”(偏移1FEH~1FFH)是结束标志。

分区表:
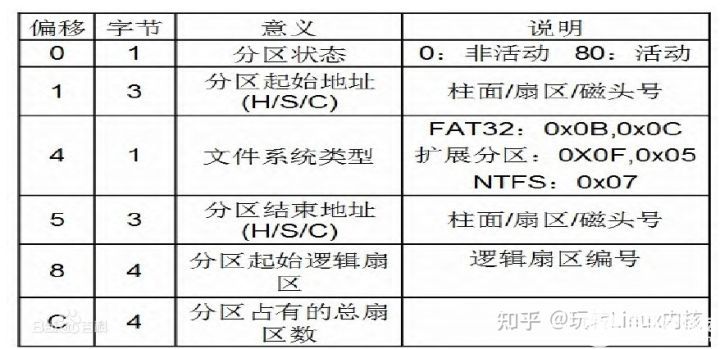
GDT
Disk label type: gpt—GPT
在MBR硬盘中,分区信息直接存储于主引导记录(MBR)中(主引导记录中还存储着系统的引导程序)。但在GPT硬盘中,分区表的位置信息储存在GPT头中。但出于兼容性考虑,硬盘的第一个扇区仍然用作MBR,之后才是GPT头。
跟现代的MBR一样,GPT也使用逻辑区块地址(LBA)取代了早期的CHS寻址方式。传统MBR信息存储于LBA 0,GPT头存储于LBA 1,接下来才是分区表本身。
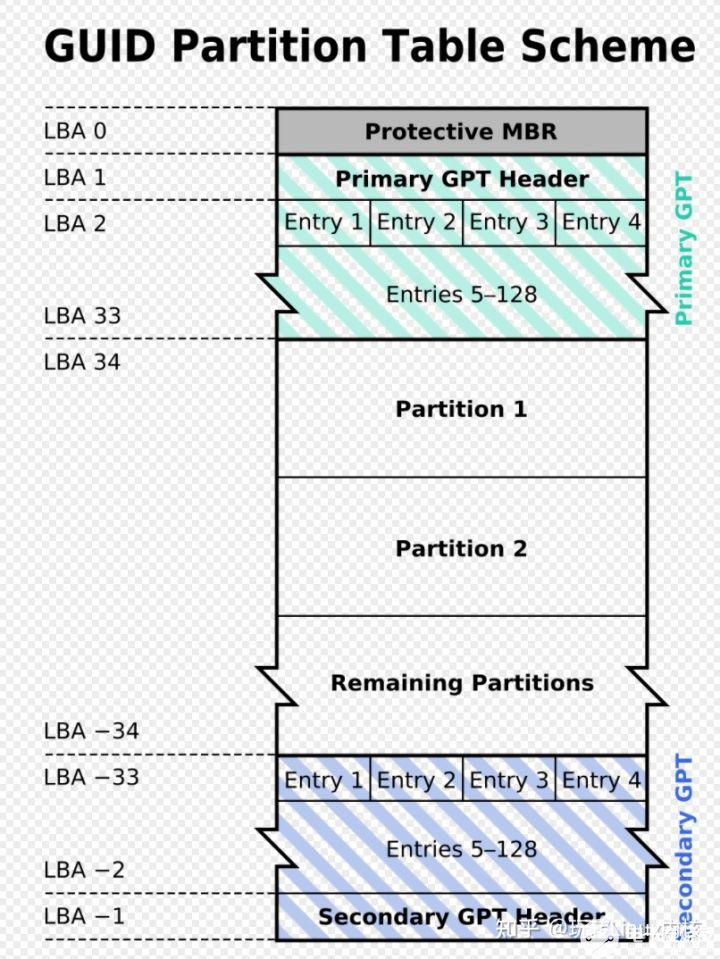
为什么要提出新的方案呢?那就让我们看看MBR分区方案有什么问题。前面已经提到了
- 主分区数目不能超过4个的限制
- 关键的是MBR分区方案无法支持超过2TB容量的磁盘。因为这一方案用4个字节存储分区的总扇区数,最大能表示2的32次方的扇区个数,按每扇区512字节计算,每个分区最大不能超过2TB。磁盘容量超过2TB以后,分区的起始位置也就无法表示了。
有了扇区(sector),有了柱面(cylinder),有了 磁头(head),显然可以定位数据了,这就是数据定位(寻址)方式之一,CHS(也称3D),对早期的磁盘(上图所示)非常有效,知道用哪个 磁头,读取哪个柱面上的第几扇区就OK了。CHS模式支持的硬盘容量有限,用8bit来存储 磁头地址,用10bit来存储柱面地址,用6bit来存储扇区地址,而一个扇区共有512Byte,这样使用CHS寻址一块硬盘最大容量为256 * 1024 * 63 * 512B = 8064 MB(1MB = 1048576B)(若按1MB=1000000B来算就是8.4GB)
但现在很多硬盘采用同密度盘片,意味着内外磁道上的扇区数量不同,扇区数量增加,容量增加,3D很难定位寻址,新的寻址模式:LBA(Logical Block Addressing)。在LBA地址中,地址不再表示实际硬盘的实际 物理地址(柱面、 磁头和扇区)。LBA编址方式将CHS这种三维寻址方式转变为一维的线性寻址,它把硬盘所有的 物理扇区的C/H/S编号通过一定的规则转变为一线性的编号,系统效率得到大大提高,避免了烦琐的 磁头/柱面/扇区的寻址方式。在访问硬盘时,由硬盘控制器再将这种 逻辑地址转换为实际硬盘的 物理地址。
LBA下的编号,扇区编号是从0开始。逻辑扇区号LBA的公式:
LBA(逻辑扇区号)=磁头数 × 每磁道扇区数 × 当前所在柱面号 + 每磁道扇区数 × 当前所在磁头号 + 当前所在扇区号 – 1
例如:CHS=0/0/1,则根据公式LBA=255 × 63 × 0 + 63 × 0 + 1 – 1= 0
也就是说 物理0柱面0 磁头1扇区,是 逻辑0扇区。也就是说 LBA就是扇区的编号, 按照磁道 柱面 和 磁头 从小到大的顺序编号
计算机启动的过程
1. BIOS 程序启动
上个世纪70年代初,“只读内存”(read-only memory,缩写为ROM)发明,开机程序被刷入ROM芯片,计算机通电后,第一件事就是读取它。这块芯片里的程序叫做"基本輸出輸入系統"(Basic Input/Output System),简称为BIOS。
2. 硬件自检
BIOS程序首先检查,计算机硬件能否满足运行的基本条件,这叫做"硬件自检"(Power-On Self-Test),缩写为POST。
如果硬件出现问题,主板会发出不同含义的蜂鸣,启动中止。如果没有问题,屏幕就会显示出CPU、内存、硬盘等信息。
硬件自检完成后,BIOS把控制权转交给下一阶段的启动程序。这时,BIOS需要知道,“下一阶段的启动程序"具体存放在哪一个设备。也就是说,BIOS需要有一个外部储存设备的排序,排在前面的设备就是优先转交控制权的设备。这种排序叫做"启动顺序”(Boot Sequence)。
打开BIOS的操作界面,里面有一项就是"设定启动顺序"。
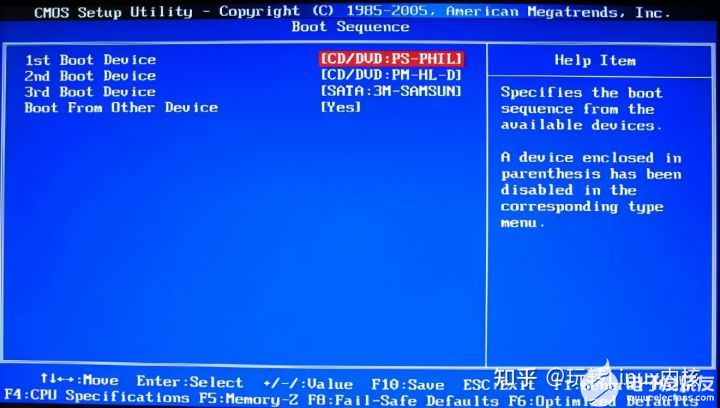
3. 主引导记录
BIOS按照"启动顺序",把控制权转交给排在第一位的储存设备。
这时,计算机读取该设备的第一个扇区,也就是读取最前面的512个字节。如果这512个字节的最后两个字节是0x55和0xAA,表明这个设备可以用于启动;如果不是,表明设备不能用于启动,控制权于是被转交给"启动顺序"中的下一个设备。 这最前面的512个字节,就叫做"主引导记录"(Master boot record,缩写为MBR)。 主引导记录"只有512个字节,放不了太多东西。它的主要作用是,告诉计算机到硬盘的哪一个位置去找操作系统
4. 启动管理器
在这种情况下,计算机读取"主引导记录"前面446字节的机器码之后,不再把控制权转交给某一个分区,而是运行事先安装的"启动管理器"(boot loader),由用户选择启动哪一个操作系统。Linux环境中,目前最流行的启动管理器是Grub。
5. 操作系统
控制权转交给操作系统后,操作系统的内核首先被载入内存。 以Linux系统为例,先载入/boot目录下面的kernel。内核加载成功后,第一个运行的程序是/sbin/init。它根据配置文件(Debian系统是/etc/initab, CentOS 是systemd)产生init进程。这是Linux启动后的第一个进程,pid进程编号为1,其他进程都是它的后代。
然后,init线程加载系统的各个模块,比如窗口程序和网络程序,直至执行/bin/login程序,跳出登录界面,等待用户输入用户名和密码。
文件存贮
文件系统到底是怎么管理磁盘的被?首先,操作系统会将磁盘分区后,同一个文件系统中,我们以ext系列为例来说明: ext系统将空间(这里的空间是指的一段连续的磁盘空间)划分为不同的功能区,比如元数据区和数据区。元数据去主要存贮文件的一些属性,比如说大小,快信息,这些信息被存贮在inode当中,而数据去以datablock 为存贮单元,主要是存放了文件的数据。
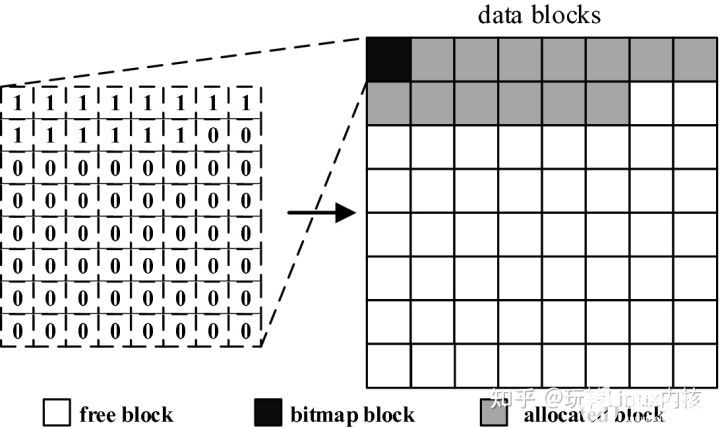
因为磁盘上的数据要和内存交互,而内存通常是以4KB为单位的,所以从逻辑上,把磁盘按照4KB划分比较方便(称为一个block)。现在假设由一个文件系统管理64个blocks的一个磁盘区域:
顺序文件结构
顾名思义,文件的存贮数据块是连续的空间。
优点是不需要额外的空间开销,只要在文件目录中指出文件的大小和首块的块号即可,对顺序的访问效率很高。适应于顺序存取且文件不经常修改的情况。 缺点是
- 文件动态地增长和缩小时系统开销很大;
- 文件创建时要求用户提供文件的大小;
- 存储空间浪费较大。
链式文件系统
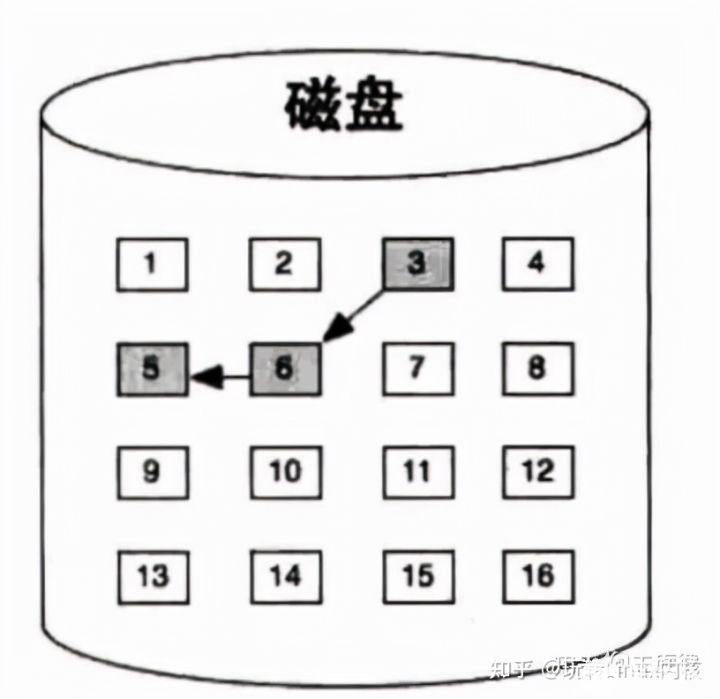
克服了连续文件的不足之处,但文件的随机访问系统开销较大。适应于顺序访问的文件。
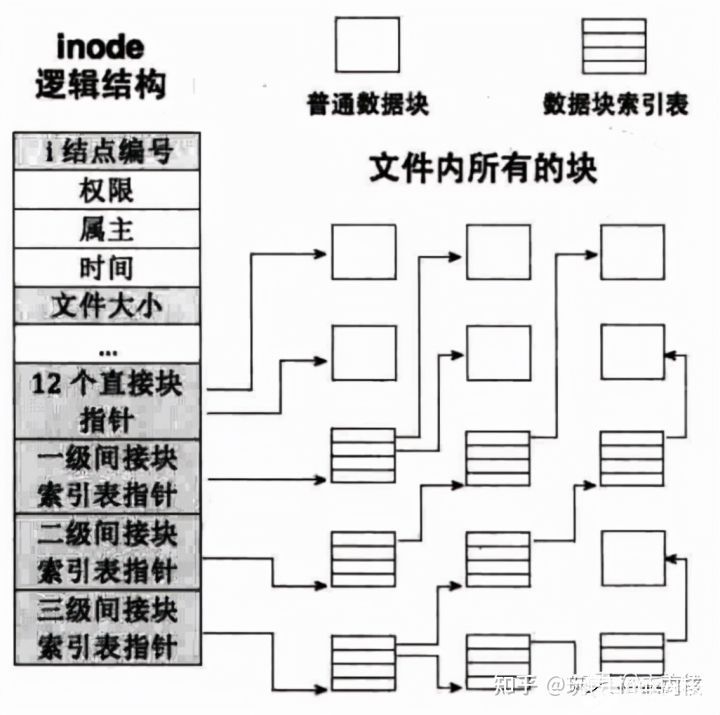
索引式文件系统
在UNIX时代,就已经实现了索引式的文件系统。它的原理是为一个文件的所有块建立一个索引表,索引表就是块地址数组,每个数组元素就是块的地址,第n个数组元素指向文件中的第n个块,这样访问任意一个块的时候,只需要从索引表中获得块地址就可以了。而且文件中的块依然可以分散到不连续的零散空间中。其结构如下图所示
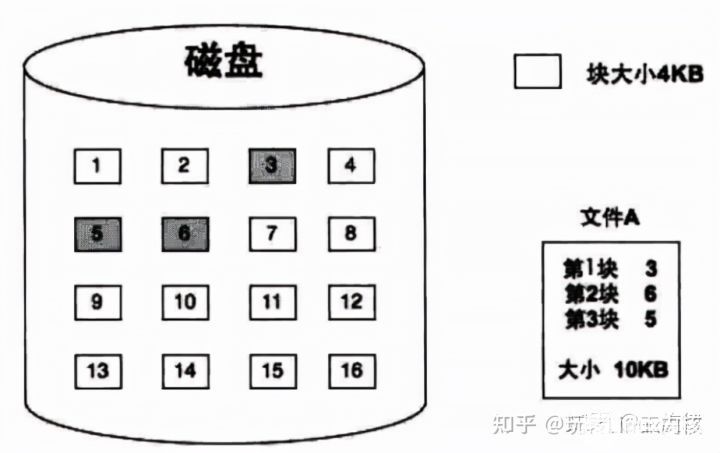
既适应于顺序存访问,也适应于随机访问,是一种比较好的文件物理结构,但要有用于索引表的空间开销和文件索引的时间开销
Ext 文件分区布局
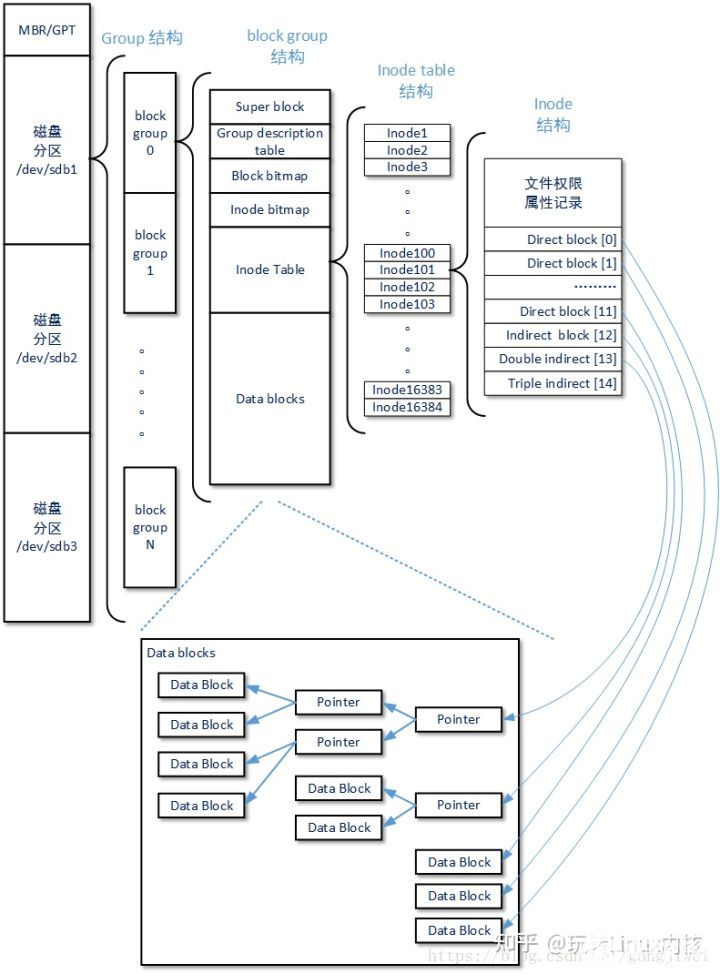
每个分区,将若干个块儿组成一个块组,每个块组会有以下几个结构
超级块
1)超级块(Super Block)描述整个分区的文件系统信息,如inode/block的大小、总量、使用量、剩余量,以及文件系统的格式与相关信息。超级块在每个块组的开头都有一份拷贝(第一个块组必须有,后面的块组可以没有)。
为了保证文件系统在磁盘部分扇区出现物理问题的情况下还能正常工作,就必须保证文件系统的super block信息在这种情况下也能正常访问。所以一个文件系统的super block会在多个block group中进行备份,这些super block区域的数据保持一致。 超级块记录的信息有:
1、block 与 inode 的总量(分区内所有Block Group的block和inode总量);
2、未使用与已使用的 inode / block 数量;
3、block 与 inode 的大小 (block 为 1, 2, 4K,inode 为 128 bytes);
4、filesystem 的挂载时间、最近一次写入数据的时间、最近一次检验磁盘 (fsck) 的时间等文件系统的相关信息;
5、一个 valid bit 数值,若此文件系统已被挂载,则 valid bit 为 0 ,若未被挂载,则 valid bit 为 1 。
它的结构如图所示

对于ext2/3/4文件系统,以上介绍的这些inode bitmap, data block bitmap和inode table,都可以通过一个名为"dumpe2fs"的工具来查看其在磁盘上的具体位置
GDT
2)块组描述符表(GDT,Group Descriptor Table)由很多块组描述符组成,整个分区分成多个块组就对应有多少个块组描述符。
每个块组描述符存储一个块组的描述信息,如在这个块组中从哪里开始是inode Table,从哪里开始是Data Blocks,空闲的inode和数据块还有多少个等等。
Inode 和 Block 位图
4)inode位图(inode Bitmap)和块位图类似,本身占一个块,其中每个bit表示一个inode是否空闲可用。 Inode bitmap的作用是记录block group中Inode区域的使用情况,Ext文件系统中一个block group中可以有16384个Inode,代表着这个Ext文件系统中一个block group最多可以描述16384个文件。
inode
索引表的索引结构称为inode,是"index node"的简称,用来索引,跟踪一个文件的所有块。inode是文件索引结构组织形式的具体体现,一个文件就必须对应一个inode。
5)inode表(inode Table)由一个块组中的所有inode组成。一个文件除了数据需要存储之外,一些描述信息也需要存储,如文件类型,权限,文件大小,创建、修改、访问时间等,这些信息存在inode中而不是数据块中。
inode表占多少个块在格式化时就要写入块组描述符中。 在Ext2/Ext3文件系统中,每个文件在磁盘上的位置都由文件系统block group中的一个Inode指针进行索引,Inode将会把具体的位置指向一些真正记录文件数据的block块,需要注意的是这些block可能和Inode同属于一个block group也可能分属于不同的block group。我们把文件系统上这些真实记录文件数据的block称为Data blocks。
索引表本身要占用存储空间,如果文件很大时,块就比较多,索引表就会很大。UNIX为了解决这个问题,采用间接索引表来处理。
ls -i 命令可以显示inode 号
➜ command ls -ilt
total 24
3003623(inode号) -rwxr-xr-x 1 root root 78 8 10 16:43 jump
3003622(inode号) -rwxr-xr-x 1 root root 476 8 10 16:42 jumper.sh
3003624(inode号) -rwxr-xr-x 1 root root 3346 3 24 2019 imgcat
data block
6)数据块(Data Block)是用来放置文件内容数据的地方。根据不同的文件类型有以下几种情况:
对于普通文件,文件的数据存储在数据块中。
对于目录,该目录下的所有文件名和目录名存储在所在目录的数据块中,除了文件名外,ls -l命令看到的其它信息保存在该文件的inode中。
文件分区实践
我们根据实践一下磁盘分区的步骤,实践一下ext4下的文件管理系统的步骤。我们的系统如下。
Linux CentOS7 3.10.0-1127.el7.x86_64 #1 SMP Tue Mar 31 23:36:51 UTC 2020 x86_64 x86_64 x86_64 GNU/Linux
首先第一步,我们需要一块硬盘,用于我是CentOS7的系统,这里我在虚拟机上新建了一块硬盘,容量是1G,这块硬盘还没有格式,我可以在我的/dev 目录下找到这块硬盘。
[root@CentOS7 ~]# ls /dev/sd*
/dev/sda /dev/sda1 /dev/sda2 /dev/sdb
查看分区,我一共有两块硬盘,一块是sda,一块是sdb。我们接下来需要格式化一下sdb.
格式化硬盘
首先,我们需要用fdisk 将sdb
[root@CentOS7 ~]# fdisk /dev/sdb
欢迎使用 fdisk (util-linux 2.23.2)。
更改将停留在内存中,直到您决定将更改写入磁盘。
使用写入命令前请三思。
Device does not contain a recognized partition table
使用磁盘标识符 0x30c1a40d 创建新的 DOS 磁盘标签。
命令(输入 m 获取帮助):m #获取帮助命令
命令操作
a toggle a bootable flag
b edit bsd disklabel
c toggle the dos compatibility flag
d delete a partition
g create a new empty GPT partition table
G create an IRIX (SGI) partition table
l list known partition types
m print this menu
n add a new partition
o create a new empty DOS partition table
p print the partition table
q quit without saving changes
s create a new empty Sun disklabel
t change a partition's system id
u change display/entry units
v verify the partition table
w write table to disk and exit
x extra functionality (experts only)
命令(输入 m 获取帮助):n
Partition type:
p primary (0 primary, 0 extended, 4 free) (这里表示,我们没有任何分许,允许你创建4个可用分区,0个主分区,和一个逻辑分区)
e extended
Select (default p): p (我们来创建主分区)
分区号 (1-4,默认 1): (选择分区号,默认即可)
起始 扇区 (2048-2097151,默认为 2048): (0-2048) # 前2048是系统预留空间
将使用默认值 2048
Last 扇区, +扇区 or +size{K,M,G} (2048-2097151,默认为 2097151): (我们直接全部将1g划分为这个分区)
将使用默认值 2097151
分区 1 已设置为 Linux 类型,大小设为 1023 MiB
创建文件系统
使用CentOS7 自带的文件系统格式工具,将sdb整个硬盘格式化成ext4文件格式。
mke2fs:ext系列文件系统专用管理工具
[root@CentOS7 ~]# mkfs.ext4 /dev/sdb
mke2fs 1.42.9 (28-Dec-2013)
/dev/sdb is entire device, not just one partition!
无论如何也要继续? (y,n) y
文件系统标签=
OS type: Linux
块大小=4096 (log=2)
分块大小=4096 (log=2)
Stride=0 blocks, Stripe width=0 blocks
65536 inodes, 262144 blocks # inodes数量和blicks 是数量
13107 blocks (5.00%) reserved for the super user
第一个数据块=0
Maximum filesystem blocks=268435456
8 block groups # 8个块组
32768 blocks per group, 32768 fragments per group
8192 inodes per group # 每组 inode 的数量
Superblock backups stored on blocks: # 超级快的存贮位置
32768, 98304, 163840, 229376
Allocating group tables: 完成
正在写入inode表: 完成
Creating journal (8192 blocks): 完成 # 创建日志区
Writing superblocks and filesystem accounting information: 完成
查看分区
经过生面的步骤,我们已经将分区创建完毕,我们使用blkid 命令来查看一下分区
[root@CentOS7 ~]# blkid
/dev/sda1: UUID="79678d4f-9276-4d1e-8093-28623d77461e" TYPE="xfs"
/dev/sda2: UUID="FtqgeH-yiRM-f1Wr-73LT-QkQf-2kgX-BkXYi1" TYPE="LVM2_member"
/dev/sr0: UUID="2020-04-22-00-54-00-00" LABEL="CentOS 7 x86_64" TYPE="iso9660" PTTYPE="dos"
/dev/mapper/centos-root: UUID="d0412c8e-07f5-4716-8be7-8ed2da9affca" TYPE="xfs"
/dev/mapper/centos-swap: UUID="ac1ae2c7-d653-4496-97fa-d9315f56993f" TYPE="swap"
/dev/sdb: UUID="6285b923-0ee4-444d-9c68-d6af94914bc3" TYPE="ext4"
查看 超级块和块组
dumpe2fs 1.42.9 (28-Dec-2013)
Filesystem volume name:
Last mounted on:
Filesystem UUID: 6285b923-0ee4-444d-9c68-d6af94914bc3
Filesystem magic number: 0xEF53
Filesystem revision #: 1 (dynamic)
Filesystem features: has_journal ext_attr resize_inode dir_index filetype extent 64bit flex_bg sparse_super large_file huge_file uninit_bg dir_nlink extra_isize
Filesystem flags: signed_directory_hash
Default mount options: user_xattr acl
Filesystem state: clean
Errors behavior: Continue
Filesystem OS type: Linux
Inode count: 65536
Block count: 262144
Reserved block count: 13107
Free blocks: 249189
Free inodes: 65525
First block: 0
Block size: 4096
Fragment size: 4096
Group descriptor size: 64
Reserved GDT blocks: 127
Blocks per group: 32768
Fragments per group: 32768
Inodes per group: 8192
Inode blocks per group: 512
Flex block group size: 16
Filesystem created: Wed Sep 30 12:22:05 2020
Last mount time: n/a
Last write time: Wed Sep 30 12:22:05 2020
Mount count: 0
Maximum mount count: -1
Last checked: Wed Sep 30 12:22:05 2020
Check interval: 0 ()
Lifetime writes: 33 MB
Reserved blocks uid: 0 (user root)
Reserved blocks gid: 0 (group root)
First inode: 11
Inode size: 256
Required extra isize: 28
Desired extra isize: 28
Journal inode: 8
Default directory hash: half_md4
Directory Hash Seed: 61f49ab4-d494-4be8-95b7-404358b685aa
Journal backup: inode blocks
Journal features: (none)
日志大小: 32M
Journal length: 8192
Journal sequence: 0x00000001
Journal start: 0
Group 0: (Blocks 0-32767)
Checksum 0x4cc2, unused inodes 8181
主 superblock at 0, Group descriptors at 1-1
保留的GDT块位于 2-128
Block bitmap at 129 (+129), Inode bitmap at 145 (+145)
Inode表位于 161-672 (+161)
28521 free blocks, 8181 free inodes, 2 directories, 8181个未使用的inodes
可用块数: 142-144, 153-160, 4258-32767
可用inode数: 12-8192
Group 1: (Blocks 32768-65535) [INODE_UNINIT]
Checksum 0xabae, unused inodes 8192
备份 superblock at 32768, Group descriptors at 32769-32769
保留的GDT块位于 32770-32896
Block bitmap at 130 (bg #0 + 130), Inode bitmap at 146 (bg #0 + 146)
Inode表位于 673-1184 (bg #0 + 673)
32639 free blocks, 8192 free inodes, 0 directories, 8192个未使用的inodes
可用块数: 32897-65535
可用inode数: 8193-16384
...
审核编辑:汤梓红
-
内核
+关注
关注
4文章
1482浏览量
43154 -
Linux
+关注
关注
88文章
11868浏览量
219908 -
文件系统
+关注
关注
0文章
305浏览量
21090
发布评论请先 登录
Linux平台/proc虚拟文件系统详解
Linux虚拟文件系统的基础知识
VFS虚拟文件系统描述
Linux虚拟文件系统实现技术探讨
玩转Linux,先把文件系统搞懂
linux 虚拟文件可以系统实现
简单介绍Linux虚拟文件系统–VFS
Linux 内核/sys 文件系统介绍
嵌入式Linux文件系统详细介绍
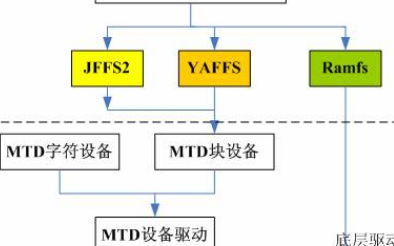
linux文件系统中的虚拟文件系统设计详解





评论