 BEVSegFormer创造了新的BEV分割SOTA
BEVSegFormer创造了新的BEV分割SOTA

对自动驾驶而言,BEV(鸟瞰图)下的语义分割是一项重要任务。尽管这项工作已经吸引了大量的研究,但灵活处理自动驾驶车辆上的任意相机配置(单个或多个摄像头),仍然是一项挑战。
为此,Nullmax的感知团队提出了BEVSegFormer,这一基于Transformer的BEV语义分割方法,可面向任意配置的相机进行BEV语义分割。
这项研究的题目为《BEVSegFormer: Bird's Eye View Semantic Segmentation From Arbitrary Camera Rigs》,论文链接:https://arxiv.org/abs/2203.04050。
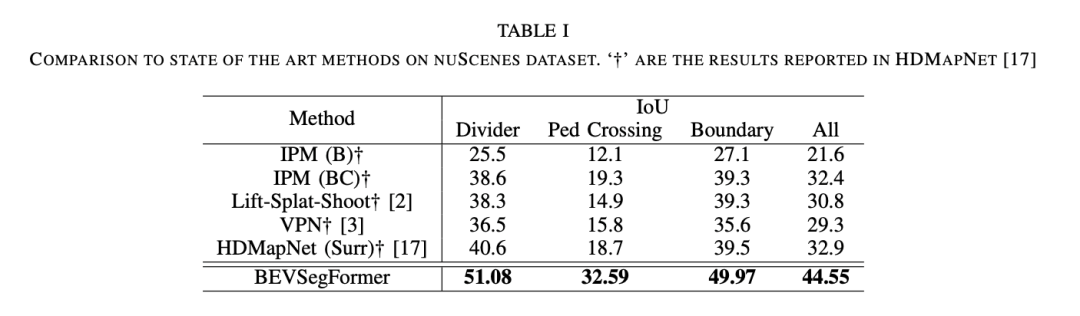
为了评估这一算法的效果,Nullmax在nuScenes公开数据集以及Nullmax的自采数据集上进行了验证。实验结果表明,BEVSegFormer对任意相机配置的BEV语义分割,具有出色的性能表现。并且在nuScenes验证集上,BEVSegFormer创造了新的BEV分割SOTA。
在接下来的工作中,我们还计划针对自动驾驶以及BEV语义分割的一些其他挑战,展开进一步的研究。
欢迎对计算机视觉及自动驾驶感知感兴趣的小伙伴加入我们,一起探索!
01
关于BEVSegFormer
在自动驾驶或者机器人导航系统中,以BEV形式对感知信息进行表征,具有至关重要的作用,因为它可以为规划和控制提供诸多的便利。
比如,在无地图导航方案中,构建本地BEV地图,不仅成为了高精地图外的另一种选择,并且对于包括智体行为预测以及运动规划等感知系统下游任务而言,也非常重要。而利用相机的输入进行BEV语义分割,通常被视为构建本地BEV地图的第一步。
为此,传统方法一般会先在图像空间生成分割结果,然后通过逆透视变换(IPM)函数转换到BEV空间。虽然这是一种连接图像空间和BEV空间的简单直接的方法,但它需要准确的相机内外参,或者实时的相机位姿估计。所以,视图变换的实际效果有可能比较差。
以车道线分割为例,在一些挑战性场景中,比如遮挡或者远处区域,使用IPM的传统方法提供的结果就不够准确,如图所示。

近年来,深度学习方法已被研究用于BEV语义分割。Lift-Splat-Shoot通过逐像素深度估计结果完成了从图像视图到BEV的视图变换。不过使用深度估计,也增加了视图变换过程的复杂度。此外,有一些方法应用MLP或者FC算子来进行视图变换。这些固定的视图变换方法,学习图像空间和BEV空间之间的固定映射,因此不依赖于输入的数据。
而基于Transformer的方法,是在BEV空间下进行感知的另一个研究方向。在目标检测任务中,DETR3D引入了一种3D边界框检测方法,直接从多个相机图像的2D特征生成3D空间中的预测。3D空间和2D图像空间之间的视图变换,通过交叉注意模块的3D到2D查询来实现。
受此启发,我们提出了BEVSegFormer,通过在Transformer中使用交叉注意机制进行BEV到图像的查询,来计算视图变换。
BEVSegFormer由3个主要的组件组成:
共享的主干网络,用于提取任意相机的特征图;
Transformer编码器,通过自注意模块嵌入特征图;
BEV Transformer解码器,通过交叉注意机制处理BEV查询,输出最终的BEV语义分割结果。
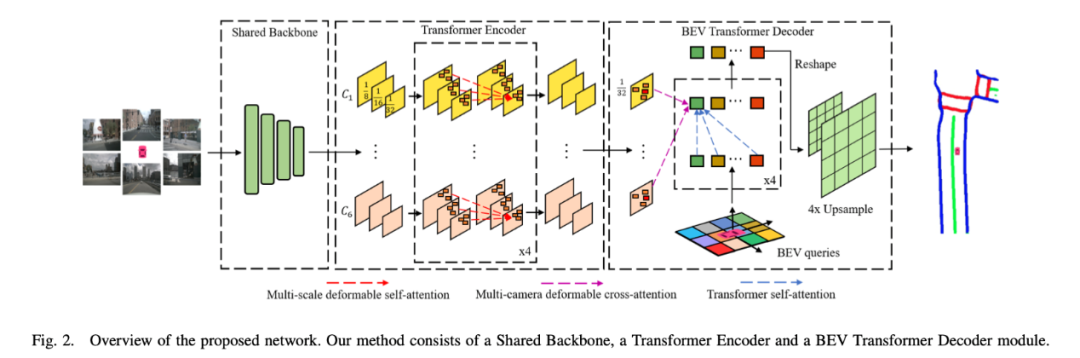
具体来说,BEVSegFormer首先是使用了共享的主干网络,对来自任意相机的图像特征进行编码,然后通过基于可变形Transformer的编码器对这些特征进行增强。
除此之外,BEVSegFormer还引入了一个BEV Transformer解码器模块,对BEV语义分割的结果进行解析,以及一种高效的多相机可变形注意单元,完成BEV到图像的视图变换。
最后,根据BEV中的网格布局对查询进行重塑,并进行上采样,以有监督的方式生成语义分割结果。
我们分别在nuScenes公开数据集以及Nullmax的自采数据集上,检验了BEVSegFormer的算法效果。实验结果表明,BEVSegFormer在nuScenes验证集上创造了新的BEV分割SOTA。通过消融实验,当中每个组件的效果也得到了验证。
02
加入我们
在这项研究中,我们为了应对自动驾驶车辆上任意相机配置的BEV语义分割挑战,提出了BEVSegFormer。
接下来,我们还计划在自动驾驶当中,基于Transformer探索内存效率更高、解释性更强的BEV语义分割方法。
欢迎对BEV、Transformer在自动驾驶中的感知任务感兴趣,以及希望从事于计算机视觉和自动驾驶感知研发的同学,加入Nullmax感知团队。
在这里,你可以直接参与到大量自动驾驶量产项目的落地,以及最前沿技术的预研当中,为你的idea和技术找到一个充分施展的舞台!
审核编辑 :李倩
-
自动驾驶
+关注
关注
794文章
14985浏览量
181444 -
深度学习
+关注
关注
73文章
5604浏览量
124615
原文标题:当BEV语义分割遇上了Transformer,故事的结局是新的SOTA
文章出处:【微信号:Nullmax,微信公众号:Nullmax纽劢】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
SAM(通用图像分割基础模型)丨基于BM1684X模型部署指南
自动驾驶BEV Camera数据采集系统:高精度时间同步解决方案

自动驾驶BEV Camera数据采集:时间同步技术解析与康谋解决方案

赋能 BEV 感知课题!高校科研多传感器时间同步方案

传音TEX AI团队斩获ICCV 2025大型视频目标分割挑战赛双料亚军
手机板 layout 走线跨分割问题
AURIX tc367通过 MCU SOTA 更新逻辑 IC 闪存是否可行?
求助,关于TC387使能以及配置SOTA 中一些问题求解
基于黄金分割搜索法的IPMSM最大转矩电流比控制
禁用直接LPB访问,如何与TC3x 上的 SWAPEN 协同工作?
北京迅为itop-3588开发板NPU例程测试deeplabv3 语义分割

如何将32个步进伺服驱动器塞进小型板材分割机中?

【正点原子STM32MP257开发板试用】基于 DeepLab 模型的图像分割
凡亿Allegro Skill布线功能-检查跨分割



评论