 模态分析定义以及模态假设理论
模态分析定义以及模态假设理论

一、什么是模态
模态是结构系统的固有振动特性。线性系统的自由振动被解耦合为N个正交的单自由度振动系统,对应系统的N个模态。每一个模态具有特定的固有频率、阻尼比和模态振型。这些模态参数可以由计算或试验分析取得,这样一个计算或试验分析过程称为模态分析。
模态分析的经典定义为,将线性定常系统振动微分方程组中的物理坐标变换为模态坐标,使方程组解耦,成为一组以模态坐标及模态参数描述的独立方程,以便求出系统的模态参数。坐标变换的变换矩阵为模态矩阵,其每列为模态振型。
通过结构模态分析法,可得出机械结构在某一易受影响的频率范围内各阶模态的振动特性,以及机械结构在此频段内及在内部或外部各种振源激励作用下的振动响应结果,再由模态分析法获得模态参数并结合相关试验,借助这些特有参数用于结构的重新设计。
二、模态假设理论
1. 线性假设
结构的动态特性(模态参数)是线性的,就是说任何输入组合引起的输出等于各自输出的组合,其动力学特性可以用线性二阶微分方程来描述。
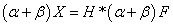
其中,F 为输入力,X 为响应值,H 为传递函数。
一般说来,单一金属材质的结构是满足线性假设的,但对于复杂结构,可能就需要进行线性检查了,而如果结构具有非线性,更应该做这个工作,因为通过施加不同量级的激励力,获得频响函数之后,能使你明白激励力改变多少时,频率移动了多少Hz。因此,如果有条件,最好对结构进行线性检查,通过数据验证更具有说服力。
2. 时不变假设
结构的动态特性不随时间变化,因而微分方程的系数是与时间无关的常数。
质量载荷:当测点较多,而加速度传感器和数据采集通道有限时,可能需要分批移动传感器,而传感器是有重量的,因此,会引起待测结构的质量(附加了传感器的重量)随着传感器的移动变化,从而影响到结构的动态特性。尤其是轻质结构,这个问题更突出。因此,当需要传感器分批移动测量时,分批移动也有一定的技巧:尽量使传感器的重量分布到整个结构中去,而不是一个局部小区域。当然也可以使用轻质的传感器。
支承刚度变化:如果测量过程中,支承结构的支承系统的刚度发生变化,肯定会影响到结构的动态特性,因此,要确定测量过程中,支承刚度发生不变。
温度变化:结构的某些属性,如材料参数,可能会受温度影响,从而导致影响结构的动态特性。
3. 互异性假设
结构应该遵从Maxwell互易性原理,即在j 点输入所引起的k 点响应,等于在k 点的相同输入所引起的j 点响应。此假设使得质量矩阵,刚度矩阵、阻尼矩阵和频响函数矩阵都成了对称阵。
4. 可观测性假设
即系统动态特性所需要的全部数据都是可以测量的。
审核编辑 :李倩
-
传感器
+关注
关注
2577文章
55460浏览量
793781 -
模态分析
+关注
关注
0文章
12浏览量
7154
原文标题:模态分析定义以及模态假设理论
文章出处:【微信号:AMTBBS,微信公众号:世界先进制造技术论坛】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
ADPD4000/ADPD4001:多模态传感器前端的卓越之选
功率放大器在螺旋载荷下管中弯曲模态导波中的应用
多模态感知大模型驱动的密闭空间自主勘探系统的应用与未来发展
商汤科技正式发布并开源全新多模态模型架构NEO

格灵深瞳多模态大模型Glint-ME让图文互搜更精准

亚马逊云科技上线Amazon Nova多模态嵌入模型





评论