 用Megatron-CNTRL为语言模型添加外部知识和可控性
用Megatron-CNTRL为语言模型添加外部知识和可控性

大型语言模型,如 Megatron 和 GPT-3 正在改变人工智能。我们对能够利用这些模型来创建更好的对话式人工智能的应用程序感到兴奋。生成语言模型在会话式人工智能应用中存在的一个主要问题是缺乏可控制性和与真实世界事实的一致性。在这项工作中,我们试图通过使我们的大型语言模型既可控又与外部知识库保持一致来解决这个问题。缩放语言模型提供了更高的流畅性、可控性和一致性。
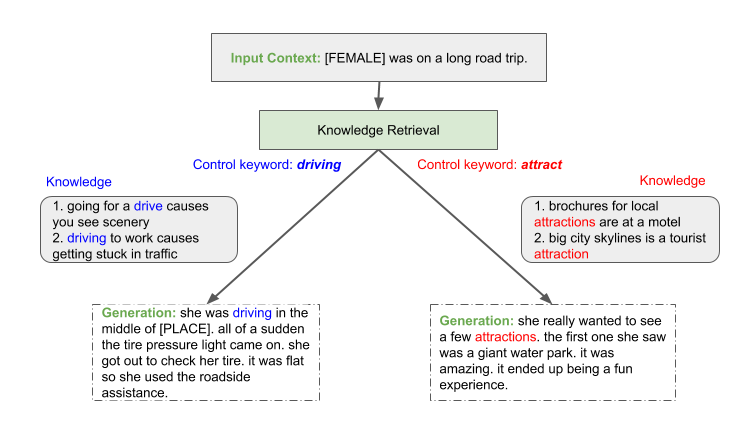
图 1 。故事是由外部知识库中的模型进行调节而产生的,并由不同的关键词如“驾驶”和“吸引”控制。
为了缓解一致性和可控性问题,已经做了几次尝试。 Guan et al.( 2020 年) 通过微调引入常识知识来解决一致性问题。然而,这种天真的方法缺乏可解释性和灵活性,无法决定何时以及从外部知识库中合并什么。
控制文本生成 的许多功能都是可取的。最近,人们开发了不同的方法来控制生成,例如 使用预先添加到模型输入的控制代码 和 以目标演员之前的谈话为条件 。然而,这些控制条件是预先定义好的,并且其能力有限。它们缺乏控制粒度,比如在句子或子文档级别。
我们通过允许在预先训练的语言模型中动态地结合外部知识以及控制文本生成来解决这些缺点。我们利用了我们的 Megatron 项目 ,它的目标是在 GPU 集群上以光效的速度训练最大的 transformer 语言模型。我们提出了一个新的生成框架,威震天 CNTRL ,它使得我们的大型威震天语言模型既可以控制,又可以使用外部知识库保持一致。
通过 土耳其机器人 使用人类求值器,我们展示了缩放语言模型提供了更高的流畅性、可控性和一致性,从而产生更真实的生成。结果,高达 91 . 5% 的生成故事被新关键字成功控制,并且高达 93 . 0% 的故事在 ROC 故事数据集 上被评估为一致。我们预计这一趋势将继续下去,从而激励人们继续投资于为对话型人工智能培训更大的模型。图 1 显示了生成过程的一个示例。
Megatron 控制框架
在问题设置中,我们用第一句话作为输入来完成一个故事。我们使用外部知识库来扩充生成过程,并开发出一种能够指导和控制故事生成的方法。图 2 显示了框架由以下连接步骤组成:
在给定故事背景的情况下,关键词预测模型首先预测下一个句子的关键词集合。
然后,知识检索器获取生成的关键字并查询外部知识库,其中每个知识三元组使用模板转换为自然语言“知识句子”。
一个语境知识 ranker 然后根据外部知识句与故事上下文的关联程度对它们进行排序。
最后,一个生成器将故事语境以及排名第一的知识句作为输入,生成故事中的下一句。输出句子附加到故事上下文中,重复步骤 1-4 。
这个公式自然地允许通过用手动外部关键字代替关键字生成过程来控制。
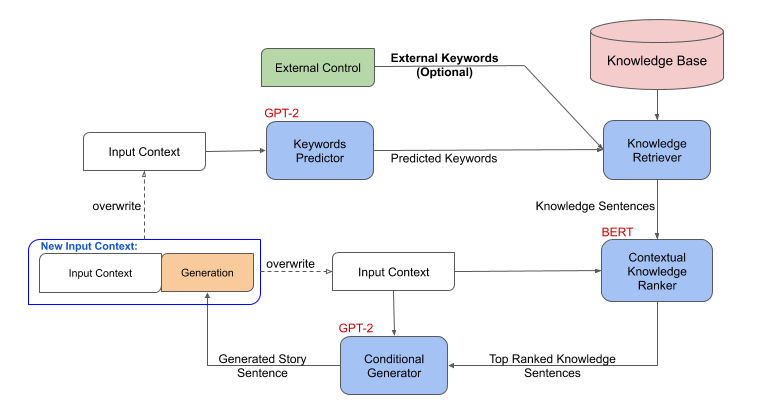
图 2 。威震天控制:生成框架概述。
我们将关键词生成建模为一个序列到序列的问题,它以故事上下文为输入,输出一系列关键字。我们使用 Megatron 模型(基于 GPT-2 )来生成关键字。知识检索器是一个简单的模型,它将关键字与知识库相匹配。对于上下文知识 ranker ,我们首先构建伪标签,通过嵌入一个名为 使用 的句子来找到与故事上下文最相关的知识。然后我们训练一个来自 Megatron 模型的 ranker (基于 BERT ),对由知识检索器过滤的知识进行排序。然后,排名靠前的知识被附加到故事上下文的末尾,作为来自 Megatron 模型的另一个条件生成器的输入,以生成下一个故事句子。
实验装置
我们使用 ROC 故事数据集进行实验。它由 98161 个故事组成,每个故事都包含五句话。按照 Guan et al.( 2020 年) ,对于每个句子,通过用特殊占位符替换故事中的所有名称和实体来执行去毒性。在每个故事的第一句话中,我们的模型的任务是生成故事的其余部分,对于外部知识库,我们使用了由 600k 知识三倍组成的 概念网 。我们分别用 Megatron 对预雨前的 BERT 和 GPT-2 模型进行上下文知识 ranker 和生成模型的初始化。关键字预测器和条件句生成器都遵循相同的设置。
质量评价
我们用自动的困惑、故事重复和 4 克的标准来评价生成的故事的质量,以及人类对连贯性、连贯性和流利性的评价。将 Megatron-CNTRL-124M 模型与表 1 和图 3 中的 Yao et al.( 2018 年) 进行比较,我们获得了更高的 4 克、一致性、流利性和一致性分数,这表明了大型预处理变压器模型的好处。将 Megatron-CNTRL-124M 与 Guan et al.( 2020 年) (不可控)进行比较,该模型还使用了表 1 所示的基于 GPT-2 的模型,我们注意到,我们的模型具有明显的更好的一致性(+ 7 . 0% )和一致性(+ 7 . 5% )。我们将这归因于检索到的知识的使用。通过明确提供与下一句相关的事实,条件生成模型可以集中于生成文本。
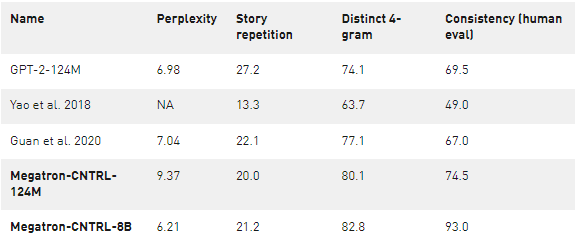
表 1 。评估了以前最先进的模型以及我们的算法在不同的大小。困惑,故事重复,和不同的 4-gram 被自动评估。
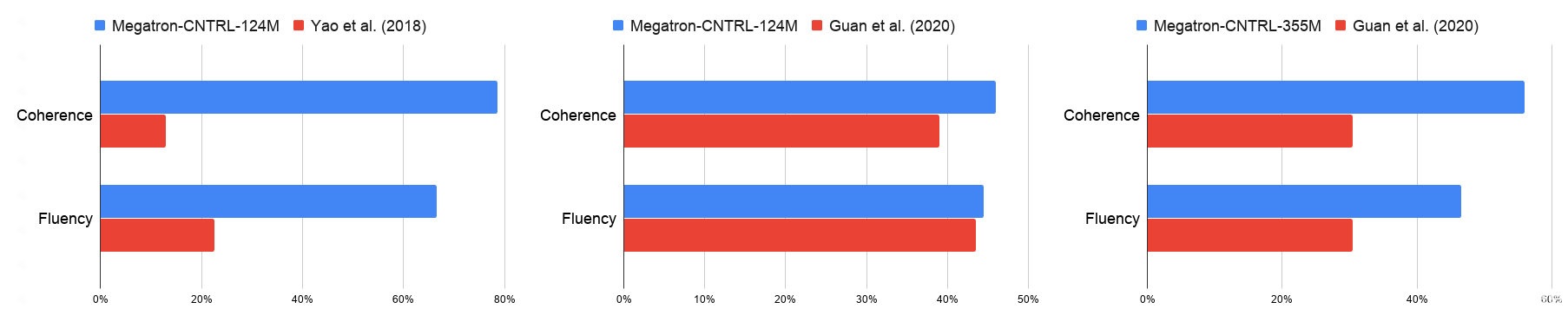
图 3 。我们的模型和基线之间成对比较的人类评估。
当模型尺寸从 124M 增加到 355M 、 774M 、 2B 和 8B 时,我们观察到在困惑、清晰、一致性、连贯性和流畅性方面的一致性改善,这表明进一步缩小模型尺寸几乎总能提高生成质量。为了保持一致性,我们在 8B 参数下的最佳模型达到了 93% 的分数,这意味着 93% 的生成故事被注释为逻辑一致。
可控性评价
我们首先将关键字改为反义词,然后询问注释者生成的故事是否根据新的关键字而变化,以此来评估模型的可控性。表 2 中的结果表明,从Megatron-CNTRL-124M-ANT (它是通过将关键字改为反义词的受控版本)生成的 77 . 5% 是由新关键字控制的。将发电模型从 124M 扩展到 8B ,我们观察到可控性得分提高到 91 . 5% ,这表明大型模型对可控性有显著的帮助。

表 2 。通过将关键字改为反义词,人类对可控性的评价。
可控世代样本
在下面的例子中,我们展示了Megatron-CNTRL 的能力。我们展示了在不同的发电粒度水平下的可控性。给出一个句子,Megatron-CNTRL 提出控制关键字。用户可以使用它们,也可以提供他们选择的外部控件关键字。这个过程一直持续到整个故事生成的结尾。
例 1:我们提供句子“[FEMALE]在一次公路旅行中”和一开始的控制关键字“ driving ”。根据这个输入 Megatron 控制产生“她在路上开车”的条件是“开车”。然后,该模型预测下两步的新关键词“突然”和“拉动,检查”,并生成相应的故事句。在生成最后一个句子之前,我们再次提供外部控制关键字“ help ”。我们观察到,生成的句子“它吸烟严重,需要帮助”跟在控制关键字后面。
视频 1 。使用“ driving ”关键字生成的故事。
例 2:我们给出与示例 1 相同的输入语句:“[FEMALE]在一次公路旅行中”,但是在开始时使用了不同的控制关键字“ excited ”。因此,Megatron-CNTRL 基于“激动”产生了一个新的故事句子:“她兴奋是因为她终于见到了(女性)”。在生成完整的故事之后,我们看到这个新的例子展示了一个关于一只巨大黑熊的可怕故事。由于外部情绪控制关键字引入的情感体验,它比示例 1 中的更具吸引力。
视频 2 。用“激动”关键字生成的故事。
结论
我们的工作证明了将大型的、经过训练的模型与外部知识库相结合的好处以及生成过程的可控性。我们未来的工作将是使知识检索器可学习,并为更长的世代引入结构级控制。
例 2 :我们给出与示例 1 相同的输入语句:“[FEMALE]在一次公路旅行中”,但是在开始时使用了不同的控制关键字“ excited ”。因此,Megatron-CNTRL 基于“激动”产生了一个新的故事句子:“她兴奋是因为她终于见到了(女性)”。在生成完整的故事之后,我们看到这个新的例子展示了一个关于一只巨大黑熊的可怕故事。由于外部情绪控制关键字引入的情感体验,它比示例 1 中的更具吸引力。
结论
我们的工作证明了将大型的、经过训练的模型与外部知识库相结合的好处以及生成过程的可控性。我们未来的工作将是使知识检索器可学习,并为更长的世代引入结构级控制。
关于作者
Peng Xu是香港科技大学的候选人。他的研究重点是情感计算和自然语言生成。通过构建能够理解人类情感的系统,他旨在实现更好的人机交互,并将更多自然世代的界限从机器上推出来。他在中国科学技术大学获得电子工程和信息科学学士学位。
Mostofa Patwary 是 NVIDIA 应用深度学习研究团队的高级深度学习研究科学家。 Mostofa 的研究兴趣遍及自然语言处理、可扩展深度学习、高性能计算和算法工程等领域。在加入 NVIDIA 之前, Mostofa 在百度硅谷人工智能实验室( Silicon Valley AI Lab )致力于扩展大型语言模型和扩展深度学习应用程序的可预测性。 Mostofa 还为能够在超级计算机上运行的机器学习中的几个核心内核开发大规模代码做出了重大贡献。
Mohammad Shoeybi 是一位高级研究科学家,在 NVIDIA 管理应用深度学习研究小组的 NLP 团队。他的团队专注于语言建模, NLP 应用,如问答和对话系统,以及大规模培训。他获得了博士学位。 2010 年从斯坦福大学毕业。在 NVIDIA 之前,他曾在 DeepMind 和美国百度工作,致力于将深度学习和强化学习应用到应用程序中。
Raul Puri 是 OpenAI 的研究科学家。劳尔在加州大学伯克利分校获得电子工程和计算机科学学士学位,重点研究生物医学工程。
Pascale Fung 是香港香港科技大学计算机科学与工程系的 ELE 〔 ZDK0 〕电子与计算机工程系教授。冯教授获哥伦比亚大学计算机科学博士学位。她曾在 at & T 贝尔实验室、 BBN 系统与技术公司、 LIMSI 、 CNRS 、日本京都大学信息科学系和法国巴黎中央经济学院工作和学习。冯教授能流利地讲七种欧洲和亚洲语言,他对多语种演讲和自然语言问题特别感兴趣。
Anima Anandkumar 在学术界和工业界拥有双重地位。她是加州理工学院 CMS 系的布伦教授和 NVIDIA 的机器学习研究主任。在 NVIDIA ,她领导着开发下一代人工智能算法的研究小组。在加州理工学院,她是 Dolcit 的联合主任,与 Yisong Yue 共同领导 AI4science initiative 。
Bryan Catanzaro 是 NVIDIA 应用深度学习研究的副总裁,他领导一个团队寻找使用人工智能的新方法来改善项目,从语言理解到计算机图形和芯片设计。布莱恩在 NVIDIA 的研究导致了 cuDNN 的诞生,最近,他帮助领导了发明 dlss2 。 0 的团队。在 NVIDIA 之前,他曾在百度创建下一代系统,用于培训和部署端到端、基于深度学习的语音识别。布莱恩在加州大学伯克利分校获得了电子工程和计算机科学博士学位
审核编辑:郭婷
-
NVIDIA
+关注
关注
14文章
5783浏览量
110527 -
深度学习
+关注
关注
73文章
5615浏览量
124885
发布评论请先 登录
零基础手写大模型资料2026
AI大模型微调企业项目实战课
解读大型语言模型的偏见


工作流大模型节点说明

什么是大模型,智能体...?大模型100问,快速全面了解!
【「龙芯之光 自主可控处理器设计解析」阅读体验】+可测试性设计章节阅读与自己的一些感想
借助NVIDIA Megatron-Core大模型训练框架提高显存使用效率

知识分享 | 使用MXAM进行AUTOSAR模型的静态分析:Embedded Coder与TargetLink模型

移远通信飞鸢AIoT大模型应用算法成功通过备案



评论