 高效框架互操作性第2部分:数据加载传输瓶颈和RDMA解决方案
高效框架互操作性第2部分:数据加载传输瓶颈和RDMA解决方案

高效的管道设计对数据科学家至关重要。在编写复杂的端到端工作流时,您可以从各种构建块中进行选择,每种构建块都专门用于特定任务。不幸的是,在数据格式之间重复转换容易出错,而且会降低性能。让我们改变这一点!
在本系列文章中,我们将讨论高效框架互操作性的不同方面:
在第一个职位中,讨论了不同内存布局以及异步内存分配的内存池的优缺点,以实现零拷贝功能。
在这篇文章中,我们将重点介绍数据加载/传输过程中出现的瓶颈,以及如何使用远程直接内存访问( RDMA )技术来缓解这些瓶颈。
在第三篇文章中,我们深入讨论了端到端管道的实现,展示了所讨论的跨数据科学框架的最佳数据传输技术。
要了解有关框架互操作性的更多信息,请查看 NVIDIA GTC 2021 年会议上的演示。
数据加载和数据传输瓶颈
数据加载瓶颈
到目前为止,我们假设数据已经加载到内存中,并且使用了单个 GPU 。本节重点介绍了 MIG 在将数据集从存储器加载到设备内存或使用单节点或多节点设置在两个 GPU 之间传输数据时出现的几个瓶颈。然后我们讨论如何克服它们。
在传统工作流(图 1 )中,当数据集从存储器加载到 GPU 内存时,数据将使用 CPU 和 PCIe 总线从磁盘复制到 GPU 内存。加载数据至少需要两份数据副本。第一种情况发生在将数据从存储器传输到主机内存( CPU RAM )时。将数据从主机内存传输到设备内存( GPU VRAM )时,会出现数据的第二个副本。
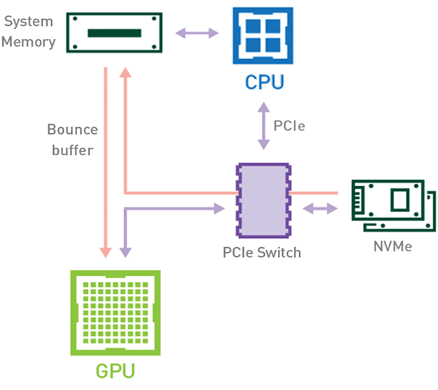
图 1 :在传统设置下,存储器 CPU 内存和 GPU 内存之间的数据移动。
或者,使用利用 NVIDIA Magnum IO GPUDirect Storage 技术的基于 GPU 的工作流(见图 2 ),数据可以使用 PCIe 总线直接从存储器流向 GPU 存储器,而无需使用 CPU 或主机存储器。由于数据只复制一次,因此总体执行时间缩短。不涉及此任务的 CPU 和主机内存也使这些资源可用于管道中其他基于 CPU 的作业。
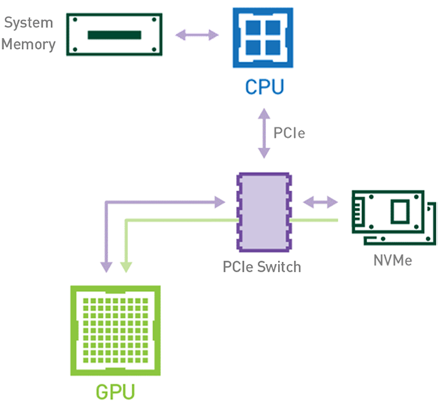
图 2 :启用 GPU 直接存储技术时,存储器和 GPU 内存之间的数据移动。
节点内数据传输瓶颈
某些工作负载要求位于同一节点(服务器)中的两个或多个 GPU 之间进行数据交换。在 NVIDIA GPUDirect Peer to Peer 技术不可用的情况下,来自源 GPU 的数据将首先通过 CPU 和 PCIe 总线复制到主机固定共享内存。然后,数据将通过 CPU 和 PCIe 总线从主机固定共享内存复制到目标 GPU 。请注意,数据在到达目的地之前复制了两次,更不用说 CPU 和主机内存都参与了这个过程。图 3 描述了前面描述的数据移动。
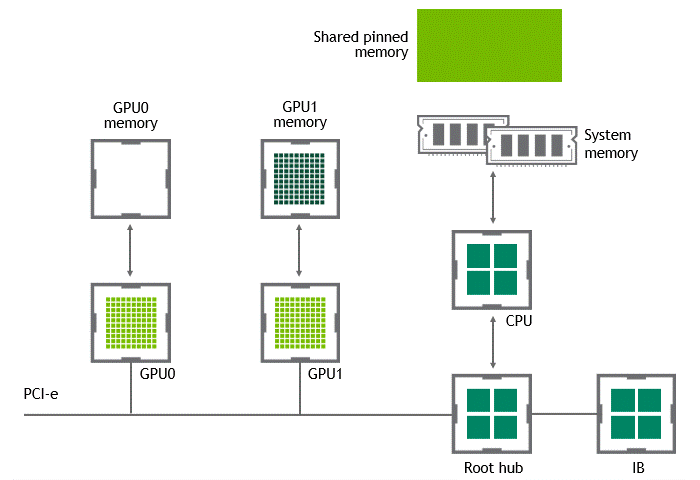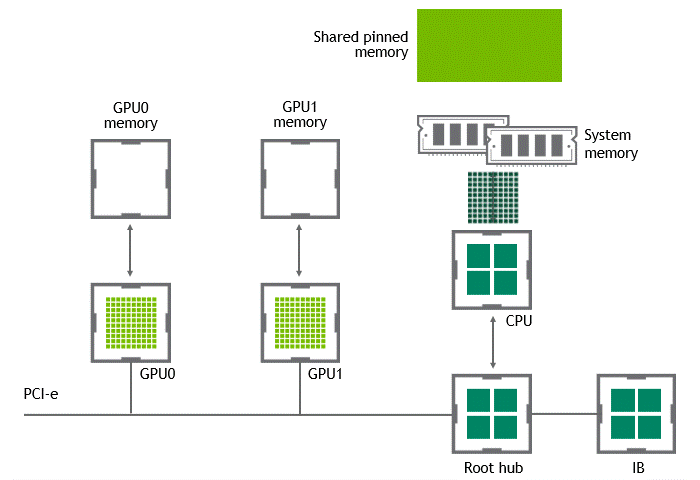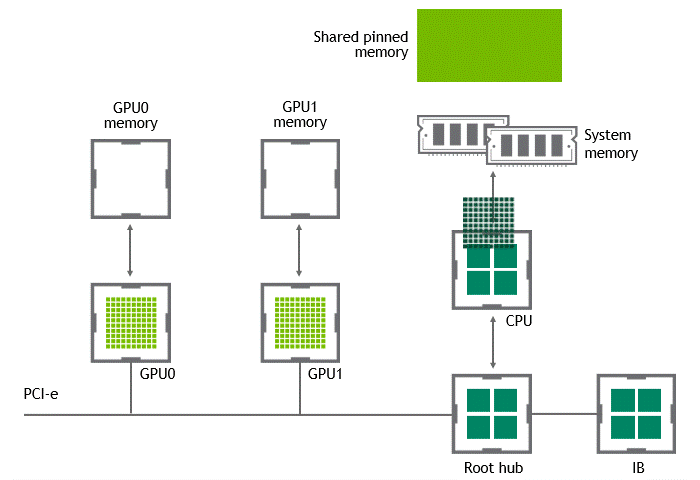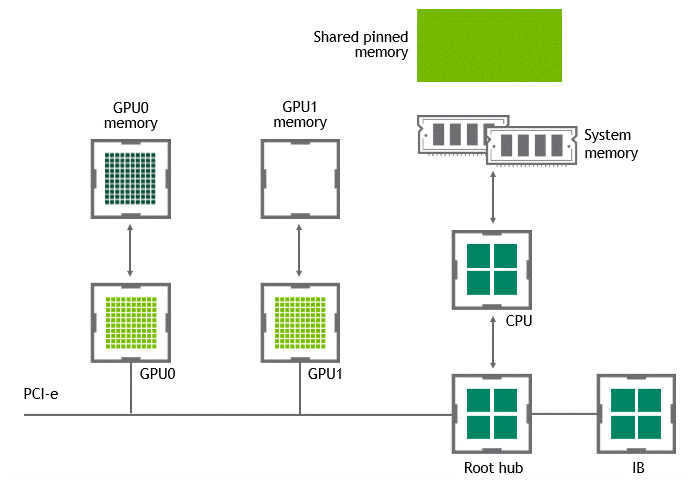
图 3 :当 NVIDIA GPU 直接 P2P 不可用时,同一节点中两个 GPU 之间的数据移动。
当 GPU 直接对等技术可用时,将数据从源 GPU 复制到同一节点中的另一 GPU 不再需要将数据临时转移到主机内存中。如果两个 GPU 都连接到同一 PCIe 总线, GPU 直接 P2P 允许在不涉及 CPU 的情况下访问其相应的内存。前者将执行相同任务所需的复制操作数量减半。图 4 描述了刚才描述的行为。
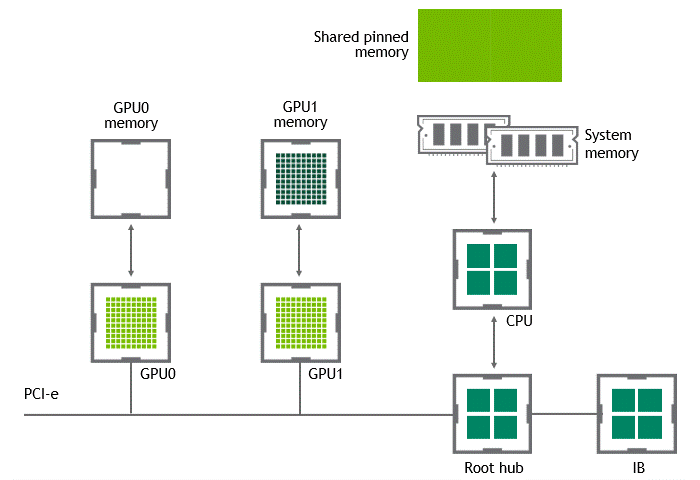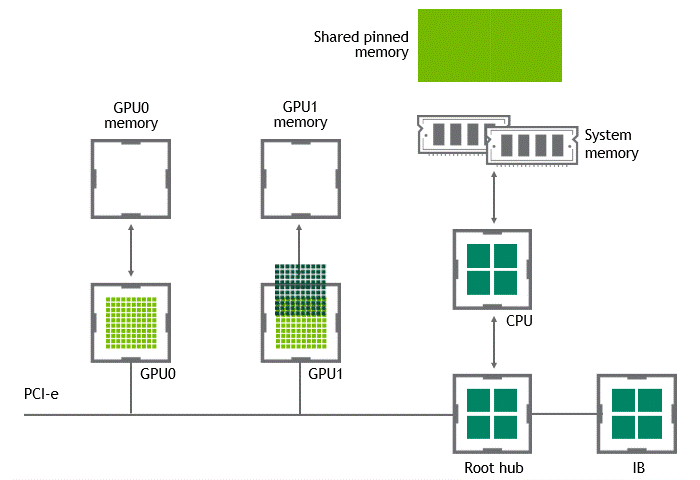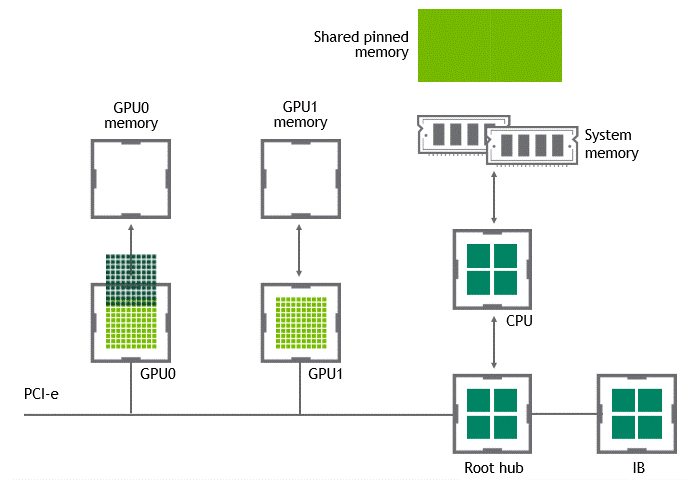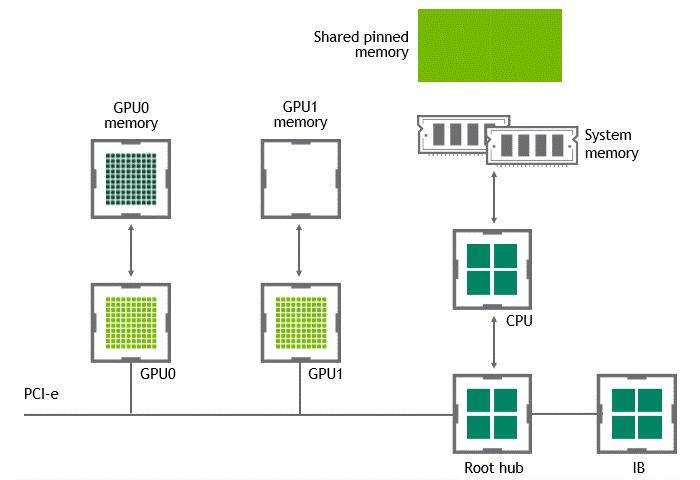
图 4 :启用 NVIDIA GPU 直接 P2P 时,同一节点中两个 GPU 之间的数据移动。
节点间数据传输瓶颈
在 NVIDIA GPUDirect Remote Direct Memory Access 技术不可用的多节点环境中,在不同节点的两个 GPU 之间传输数据需要五个复制操作:
第一次复制发生在将数据从源 GPU 传输到源节点中主机固定内存的缓冲区时。
然后,该数据被复制到源节点的 NIC 驱动程序缓冲区。
在第三步中,数据通过网络传输到目标节点的 NIC 驱动程序缓冲区。
将数据从目标节点 NIC 的驱动程序缓冲区复制到目标节点中主机固定内存的缓冲区时,会发生第四次复制。
最后一步需要使用 PCIe 总线将数据复制到目标 GPU 。
这样总共进行了五次复制操作。真是一次旅行,不是吗?图 5 描述了前面描述的过程。
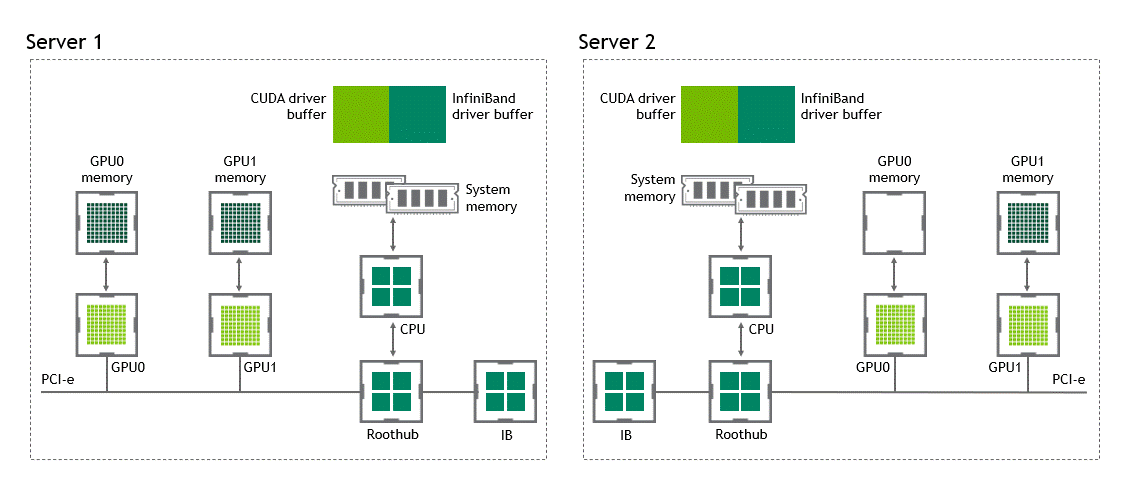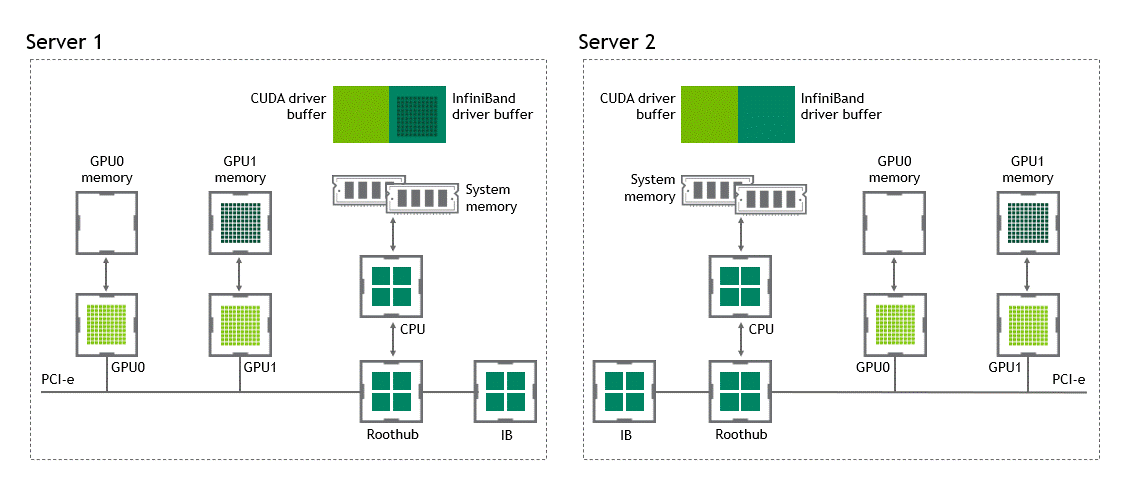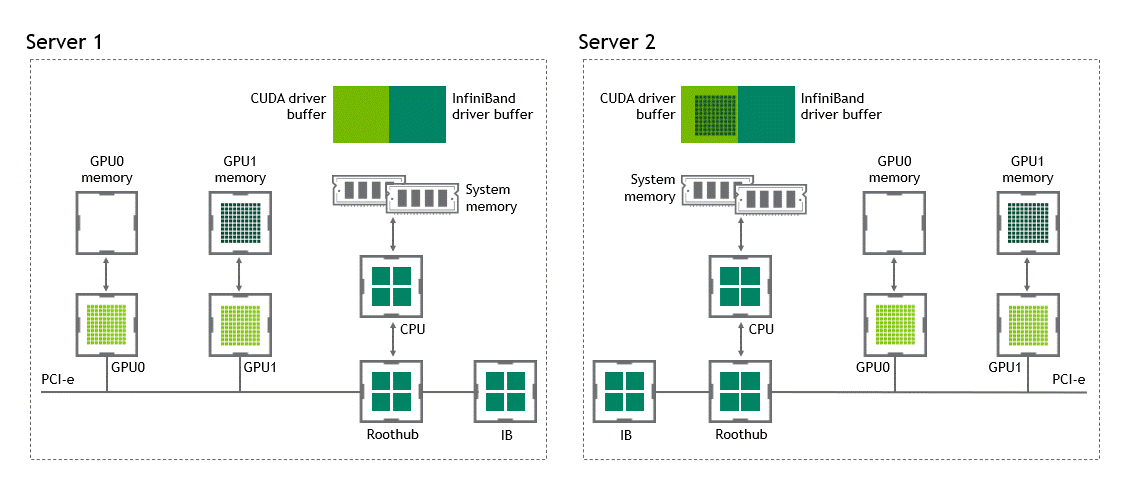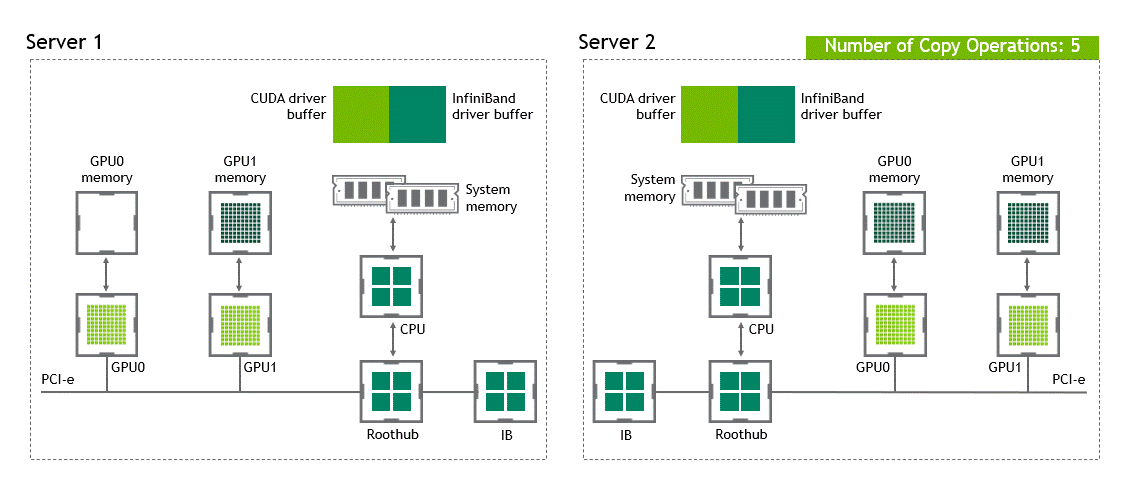
图 5 :当 NVIDIA GPU 直接 RDMA 不可用时,不同节点中两个 GPU 之间的数据移动。
启用 GPU 直接 RDMA 后,数据拷贝数将减少到一个。共享固定内存中不再有中间数据拷贝。我们可以在一次运行中直接将数据从源 GPU 复制到目标 GPU 。与传统设置相比,这为我们节省了四个不必要的复制操作。图 6 描述了这个场景。
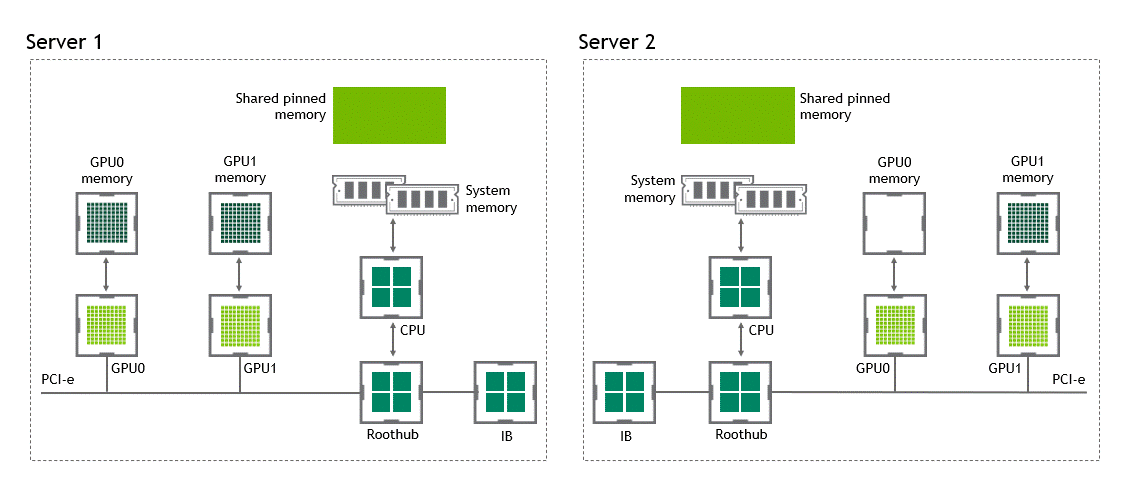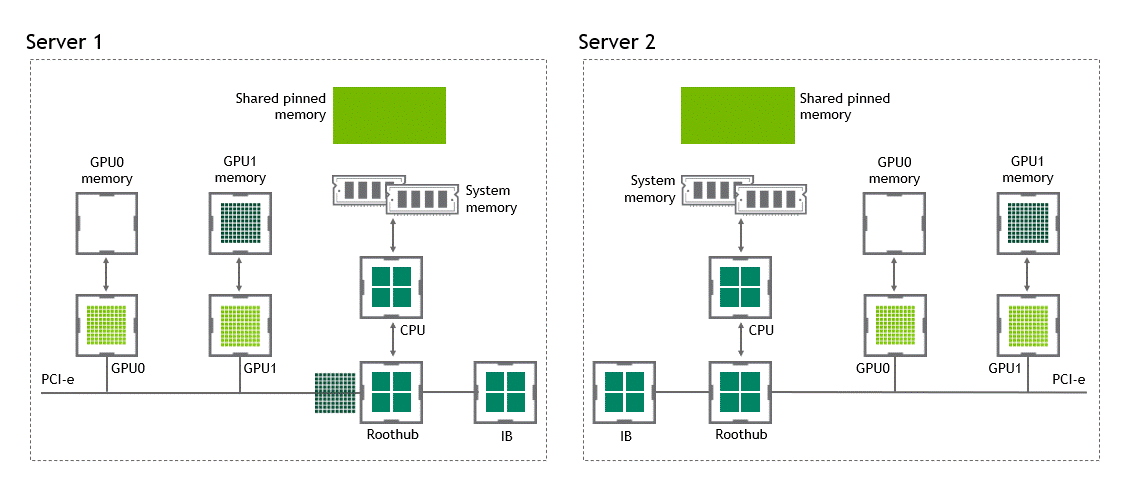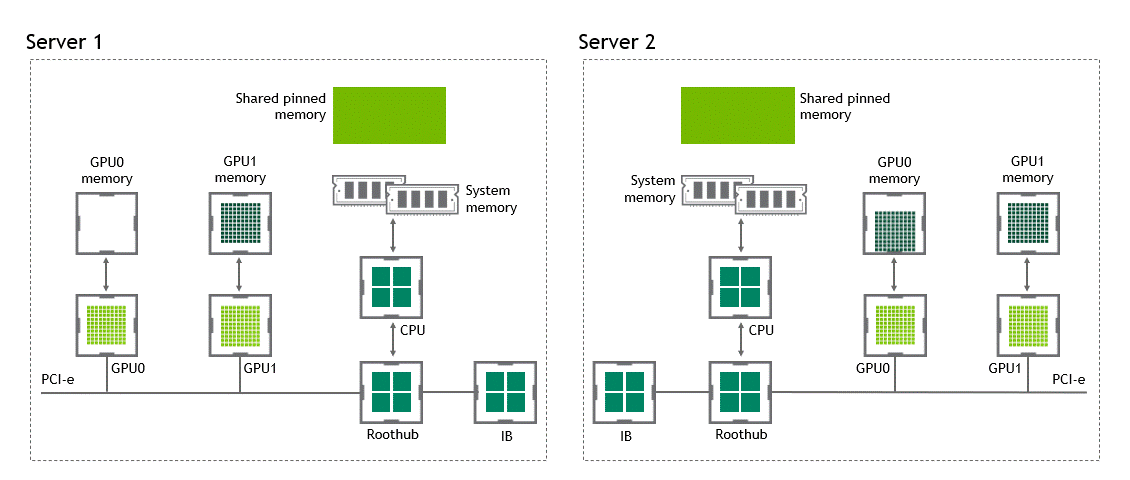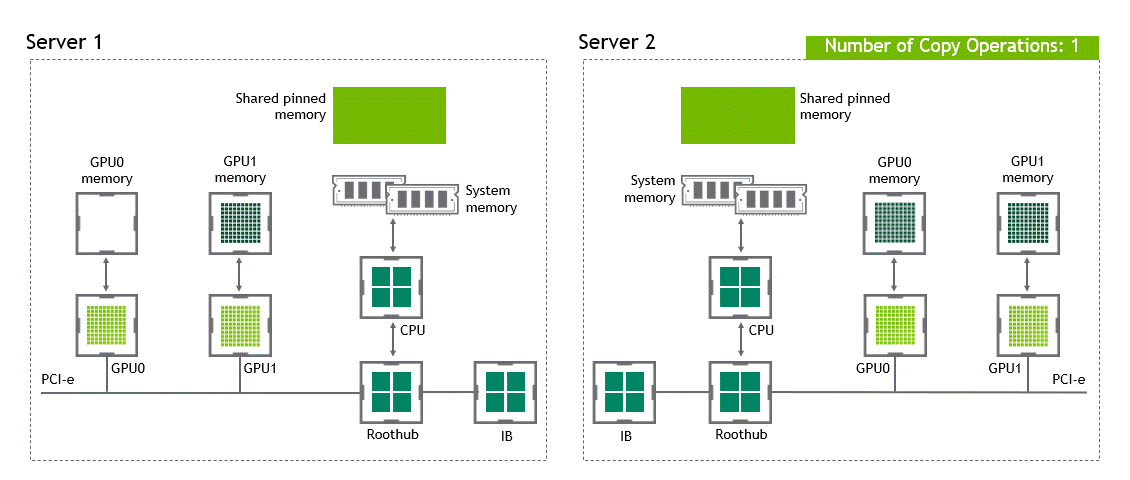
图 6 :当 NVIDIA GPU 直接 RDMA 可用时,不同节点中两个 GPU 之间的数据移动。
结论
在我们的第二篇文章中,您已经了解了如何利用 NVIDIA GPU 直接功能来进一步加快管道的数据加载和数据分发阶段。
在我们三部曲的第三部分中,我们将深入研究医学数据科学管道的实现细节,该管道用于连续测量的心电(ECG)流中的心跳异常检测。
关于作者
Christian Hundt 在德国美因茨的 Johannes Gutenberg 大学( JGU )获得了理论物理的文凭学位。在他的博士论文中,他研究了时间序列数据挖掘算法在大规模并行架构上的并行化。作为并行和分布式体系结构组的博士后研究员,他专注于各种生物医学应用的高效并行化,如上下文感知的元基因组分类、基因集富集分析和胸部 mri 的深层语义图像分割。他目前的职位是深度学习解决方案架构师,负责协调卢森堡的 NVIDIA 人工智能技术中心( NVAITC )的技术合作。
Miguel Martinez 是 NVIDIA 的高级深度学习数据科学家,他专注于 RAPIDS 和 Merlin 。此前,他曾指导过 Udacity 人工智能纳米学位的学生。他有很强的金融服务背景,主要专注于支付和渠道。作为一个持续而坚定的学习者, Miguel 总是在迎接新的挑战。
审核编辑:郭婷
-
NVIDIA
+关注
关注
14文章
5511浏览量
109159 -
深度学习
+关注
关注
73文章
5591浏览量
123974
发布评论请先 登录
RDMA设计5:RoCE V2 IP架构
RDMA设计4:技术需求分析2
RDMA设计2:开发必要性之性能简介
RDMA设计1:开发必要性1之设计考虑
是德科技与HEAD acoustics成功完成新一代eCall系统互操作性测试
Microchip与AVIVA Links实现ASA-ML互操作性验证
RDMA over RoCE V2设计2:ip 整体框架设计考虑
RDMA简介2之A技术优势分析
RDMA简介1之RDMA开发必要性
瑞为技术牵头制定的国家标准《信息技术 可扩展的生物特征识别数据交换格式 第1部分:框架》正式发布
Matter 1.4如何提升智能家居设备互操作性
新思科技与英特尔携手完成UCIe互操作性测试
ISO 16750-2-2010 道路车辆电气和电子设备的环境条件和试验第2部分:电气负载
乐鑫 ESP32-C6 通过 Thread 1.4 互操作性认证

PCIe 6.0 互操作性PHY验证测试方案





 工商网监
工商网监
评论