 最新版本CUDA 11 . 5工具包的基本新功能
最新版本CUDA 11 . 5工具包的基本新功能

NVIDIA 宣布 CUDA 开发环境的最新版本 CUDA 11 . 5 。 CUDA 11 . 5 专注于增强您的 CUDA 应用程序的编程模型和性能。 CUDA 继续推动 GPU 加速的边界,并为 HPC 、可视化、 AI 、 ML 和 DL 中的新应用打下基础,和数据科学。
CUDA 11 . 5 有几个重要特性。这篇文章概述了关键功能:
-
CUDA 编程模型增强
- 扫描合作小组中的集体
- 标准化整数格式
- 块压缩格式
- C ++中可配置的缓存提示
- MPS 增强功能(客户端内存限制)
- WSL 上的 CUDA 驱动程序更新
- CUDA Python GA
- NVIDIA 开普勒驱动器的弃用
- CUDA C ++(有关更多信息,请参阅使用 CUDA C ++编译辅助工具减少应用程序构建时间)
- NSight 计算/系统工具
CUDA 11 . 5 附带 R510 驱动程序,该驱动程序是一个长期支援科. CUDA 11 . 5 可供下载。
CUDA 编程模型增强
此版本引入了关键的增强功能,以提高 CUDA 图形的可用性和性能,而无需对应用程序进行任何修改或任何其他用户干预。它还提高了多进程服务( MPS )的易用性。我们在 CUDA 编程指南中对异步编程模型进行了形式化。
扫描合作小组中的集体
与reductions和障碍,前缀和(也称为scans)一起,它们是并行计算的基石。扫描操作采用二进制运算符(通常为加法),并在输入数组上累积应用该运算符进行迭代。扫描可以是inclusive,包括所有元素x[0]…x[n],或在范围{0,x[0]…x[n-1]}上迭代的exclusive。
例如,使用输入数组[3 1 7 0 4 1 6 3]的+运算符进行独占扫描将导致以下结果:
[0 3 4 11 11 15 16 22]
CUDA 11 . 5 添加了一个新的头
| Inclusive Scan | Exclusive Scan | Description |
template |
templateT exclusive_scan(const Group& g, T&& val, OpType&& op); |
Perform scan using user supplied binary operator. |
template |
template |
Same as above with assumed op == plus |
在所有情况下,返回类型必须与输入值类型匹配。
规范化整数数据类型
标准化有符号和无符号 8 位和 16 位数据类型是 GPU 编程语言最广泛支持的一些纹理格式。 CUDA 一段时间以来一直支持将这些格式用于纹理对象,但在 11 . 5 版本中,我们扩展了对这些数据类型的现有支持,使与其他外部 API 的互操作更加直观。
我们在驱动程序和运行时 API 中引入了新的 CUDA 数组格式。驱动程序 API 公开了 12 种新的数组格式,如下所示:
CU_AD_FORMAT_UNORM_INT8X{1|2|4}
CU_AD_FORMAT_UNORM_INT16X{1|2|4}
CU_AD_FORMAT_SNORM_INT8X{1|2|4}
CU_AD_FORMAT_SNORM_INT16X{1|2|4}
这些可用于创建 1 、 2 或 4 通道 CUDA 阵列。运行时 API 同样公开了 12 种新的等效通道格式:
cudaChannelFormatKindUnsignedNormalized8X{1|2|4}
cudaChannelFormatKindSignedNormalized8X{1|2|4}
cudaChannelFormatKindUnsignedNormalized16X{1|2|4}
cudaChannelFormatKindSignedNormalized16X{1|2|4}
这些还可用于创建 1 、 2 或 4 通道、 8 位或 16 位通道宽度 CUDA 阵列。此外,您现在可以从外部 API (如 DirectX12 / 11 或 Vulkan )导入匹配的格式化纹理,并将其映射为 CUDA 数组。使用资源视图创建纹理对象时,格式 texel 大小必须与数组 texel 大小匹配。
对于纹理对象,可以创建和访问它们,如以下代码示例所示:
cudaArray_t array;
cudaChannelFormatDesc formatDesc = {8, 8, 0, 0, cudaChannelFormatKindUnsignedNormalized8X2};
cudaMallocArray(&array, formatDesc, width, height);
cudaTextureDesc texDesc = {0};
texDesc.addressMode[0] = texDesc.addressMode[1] = cudaAddressModeClamp ;
// (3) Create CUDA texture object
cudaResourceDesc resDesc = {0};
resDesc.resType = cudaResourceTypeArray;
resDesc.res.array = array;
cudaCreateTextureObject(&texObj, &resDesc, &texDesc, NULL);
// Read from texture object in a kernel as follows:
// float4 texel = tex2D(texture, x, y);
// (6) Release all resources
cudaDestroyTextureObject(texObj);
cudaFreeArray(array);
同样,对于曲面对象:
cudaArray_t array;
cudaChannelFormatDesc formatDesc = {16, 16, 16, 16, cudaChannelFormatKindSignedNormalized16X4};
cudaMallocArray(&array, formatDesc, width, height);
// (3) Create CUDA surface object
cudaResourceDesc resDesc = {0};
resDesc.resType = cudaResourceTypeArray;
resDesc.res.array = array;
cudaCreateSurfaceObject(&surfObj, &resDesc);
// Read/Write to/from surface object in a kernel as follows
// Read:
// short4 texel = surf2DRead(surface, xInBytes, y);
// Unformatted stores:
// surf2DWrite(texel, surface, xInBytes, y);
// Formatted stores: (Formatted surface stores are currently not exposed in CUDA runtime device functions)
// sust.p.2d.v4.b32
// (6) Release all resources
cudaDestroySurfaceObject(surfObj);
cudaFreeMipmappedArray(array);
对块压缩数据类型的支持
在所有图形编程语言和框架中,用于减小纹理大小的最常见有损压缩技术之一是使用块压缩( BC )纹理格式。使用这些格式可以显著节省纹理的内存占用。有几种 BC 格式,每种格式都有其独特的优点和缺点,通常称为 BCn 格式。
NVIDIA GPU 体系结构本机支持 BCn 格式,并且通过纹理资源视图在 CUDA 中的支持有限。现在,我们在驱动程序和运行时 API 中引入新的 BC CUDA 数组格式。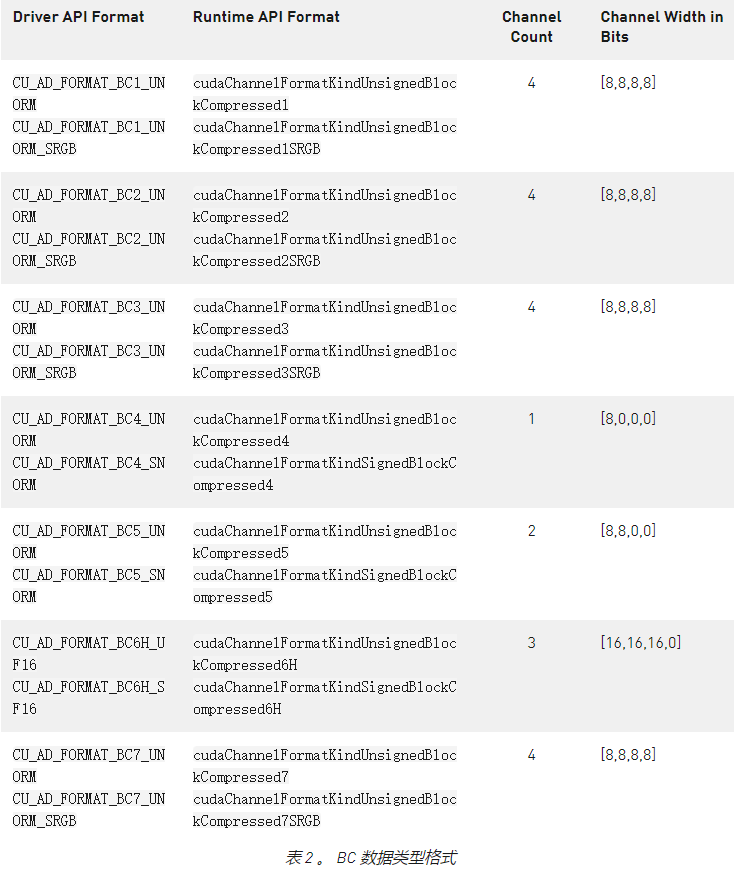
这些格式可用于使用cuArray[3D]Create运行时 API 或cuArray[3D]Create驱动程序 API 创建 BCn 格式的cuMipmappedArrayCreate数组。类似地,可以使用 CUDA 运行时 API 或cuMipmappedArrayCreate驱动程序 API 创建 CUDA mipmapped 数组。使用这些格式创建 CUDA 阵列时,阵列范围必须是压缩块大小的倍数( 2D 为 4×4 , 3D 为 4x4x1 )。这些阵列还可用于创建纹理对象。
C ++中可配置的缓存提示
在在 CUDA 11 . 4 中发现新功能中,我们引入了一个 PTX ISA 扩展,为驻留在 GPU 上的数据向编译器和运行时提供缓存提示。在 CUDA 11 . 5 中,我们将此能力扩展到带有注释指针的 C ++。它们充当普通指针,并应用附加属性。
注释指针是使用
cuda::access_property::normal (evict_normal_demote)
cuda::access_property::streaming (evict_first)
cuda::access_property::persisting (evict_last)
cuda::access_property::shared (shared memory)
cuda::access_property::global (evict_normal)
例如,在内核代码中,声明和使用带注释的指针可能类似于以下代码:
static __device__
void my_kernel(int * in, int * out) {
cuda::access_property ap(cuda::access_property::persisting{});
// Retrieve global id
int i = blockIdx.x * blockDim.x + threadIdx.x;
cuda::annotated_ptr in_ann{in, ap};
cuda::annotated_ptr out_ann{out, ap};
...
}
MPS 增强功能(客户端内存限制)
当 GPU 的计算能力超过任何单个应用程序时,运行共享同一 GPU 硬件的多个应用程序进程可能会很有吸引力。多进程服务( MPS )运行时体系结构控制多个独立进程同时使用单个 GPU 。
但是,当多个独立进程共享 GPU 时,设置总体内存分配限制通常很有用,以避免任何单个进程占用过多的可用 GPU 内存。
在 CUDA 11 . 5 中,我们引入了一组新的控制机制,使您能够限制 MPS 客户端进程的固定内存分配。您可以通过默认的全局限制层次结构控制内存分配。
默认全局限制
可以使用设备的set_default_device_pinned_mem_limit控制命令显式启用默认全局内存限制。设置此命令将在将来生成的所有 MPS 服务器的所有 MPS 客户端上强制执行设备固定内存限制。
$nvidia-cuda-mps-control set_default_device_pinned_mem_limit 0 2G
每服务器限制:对于内存资源限制的细粒度控制,可以使用set_device_pinned_mem_limit控制命令在特定 MPS 服务器上选择性地设置限制。设置此命令将在特定 MPS 服务器的所有 MPS 客户端上强制执行设备固定内存限制。
$nvidia-cuda-mps-control set_device_pinned_mem_limit 1 1G
每个客户限额:前面两种控制机制为特定 MPS 服务器的所有 MPS 客户端设置了一个总体限制。希望更好地控制资源限制的用户;也就是说,在每个 MPS 客户端的基础上,可以通过为每个客户端进程分别设置CUDA_MPS_PINNED_DEVICE_MEM_LIMIT环境变量来实现。
此环境变量与 CUDA \ u VISIBLE \ u 设备具有相同的语义。值字符串可以包含逗号分隔的设备序号和设备 UUID ,每个设备的内存限制由等号(=)分隔。
$export CUDA_MPS_PINNED_DEVICE_MEM_LIMIT="0=1G,1=2G,GPU-7ce23cd8-5c91-34a1-9e1b-28bd1419ce90=1024M"
WSL 驱动程序上的 CUDA
用于英特尔 x86 体系结构的 NVIDIA Windows GPU 驱动程序将支持 WSL2 ,并可在 Windows 11 的 Windows Insider Preview ( WIP )程序之外访问。
CUDA Python
Python CUDA 为现有工具包和库的驱动程序和运行时 API 提供Cython绑定和 Python 包装,以简化基于 GPU 的加速处理。 Python 是科学、工程、数据分析和深度学习应用程序中最流行的编程语言之一。 CUDA Python 的目标是将 Python 生态系统统一为一组接口,提供 Python 对 CUDA 主机 API 的全面覆盖和访问。
库开发人员可以直接从 Python 使用 CUDA Python 与 CUDA 的低级接口。我们很高兴地宣布,从 11 . 5 版开始, CUDA Python 已普遍提供,可以使用 PIP 或 Conda 安装。 CUDA 支持的所有平台都支持该库。
其他增强功能
除了前面讨论的关键功能外, CUDA 11 . 5 中还有一些增强功能,有助于改进基线功能和可用性。
多线程提交吞吐量
在 11 . 5 中,我们减少了 CPU 线程之间 CUDA API 的序列化开销。默认情况下,将启用这些更改。但是,为了帮助对潜在更改可能导致的问题进行分类,我们提供了一个环境变量CUDA_REDUCE_API_SERIALIZATION,以关闭这些更改。这是前面讨论的基础更改之一,有助于 CUDA 图的性能改进。
NVIDIA 开普勒驱动器的弃用
NVIDIA 开普勒微体系结构于 2012 年首次引入,并已逐步淘汰。对于所有基于开普勒 NVIDIA 的 SKU ,我们已经从 R495 版本开始取消了对驱动程序的支持。但是, CUDA 工具包开发工具和对 NVIDIA 开普勒 SKU 的支持将在未来的 CUDA 11 . x 版本中继续。
C ++语言对 CUDA 的支持
作为本版本的一部分,有一些 CUDA 11 . 5 支持的关键 C ++语言增强。
- CUDA C ++编译器支持 NVRTC 和 PTX 中的并发编译,以提高编译时间。编译器现在还可以检测并消除未使用的 CUDA 内核,通过更好的代码优化减少编译时间、二进制大小和总体性能。
- 对 128 位整数值的有限支持作为用户反馈的预览功能发布,同时引入了 NVRTC 的静态库版本,并扩展了主机编译器支持以包括 Clang 12 . 0 。
- CUDA C++编译器具有我们在[VZX57 ]帖子中深入研究的特性。
- NVIDIA C ++标准库( LIbCu +++) 1 . 5 . 0 被 CUDA 11 . 4 发布。
- 推力 1 . 12 . 0 具有新的推力::通用_矢量 API ,使您能够使用推力的 CUDA 统一内存。
NSight 开发人员工具
NVIDIA NSight 开发工具: NSight System 2021 . 4 、 NSight Compute 2021 . 3 和 NSight Graphics 2021 . 4 . 2 现在提供了新版本,用于通过分析和调试 CUDA 代码提高性能。
新发布的 NSight 系统 2021 . 4改进了对 Windows 、 Direct3D12 和 Vulkan 支持的评测。此版本添加了一些功能,以帮助更好地理解操作系统中断时的进程执行,并添加了数据捕获以识别数据包队列瓶颈。特色包括:
- Windows ISR 和 DPC 跟踪
- GPU 基于硬件的调度跟踪
- Windows Direct3D12
- Vulkan 与 WDDM 事件的相关性
- NVTX 事件分类支持
- 多种系统环境的多报告加载
NSight Compute 2021 . 3 添加了一些功能,以帮助用户了解其 CUDA 内核的性能。新的占用率计算器活动对 CUDA 内核的资源利用率进行建模,以便您可以交互式地调整模型参数,以查看它们如何影响占用率。屋顶折线图现在支持分层脱机,它表示除设备内存之外的内存层次中的其他级别。您可以查看内核是否存在与缓存访问请求相关的瓶颈。
还有其他改进,包括更多可配置的基线比较、从 CLI 查看源代码级信息以及其他 SSH 功能。
 图 1 。占用率计算器
图 1 。占用率计算器最新的 NSight 图形 2021 . 4 . 2 现在包括对 Windows 11 的支持。这意味着您现在可以使用downloadDirect3D 和 Vulkan 的 NVIDIA 图形调试器和探查器,在最前沿的 Windows 版本上创建惊人的 3D 图形。
关于作者
Rob Armstrong 是 CUDA 工具包的主要技术产品经理。 20 多年来,他一直专注于使用异构硬件平台加速软件,并对计算机体系结构和硬件/软件交互特别感兴趣。
Arthy Sundaram 是 CUDA 平台的技术产品经理。她拥有哥伦比亚大学计算机科学硕士学位。她感兴趣的领域是操作系统、编译器和计算机体系结构。
Fred Oh 是 CUDA 、 CUDA on WSL 和 CUDA Python 的高级产品营销经理。弗雷德拥有加州大学戴维斯分校计算机科学和数学学士学位。他的职业生涯开始于一名 UNIX 软件工程师,负责将内核服务和设备驱动程序移植到 x86 体系结构。他喜欢《星球大战》、《星际迷航》和 NBA 勇士队。
审核编辑:郭婷
-
NVIDIA
+关注
关注
14文章
5690浏览量
110118 -
应用程序
+关注
关注
38文章
3346浏览量
60421 -
开发环境
+关注
关注
1文章
275浏览量
17674
发布评论请先 登录
芯科科技发布Simplicity Studio 6软件开发套件最新版本SiSDK 2025.12.0
蔚来世界模型NWM全新版本正式推送
嵌入式开发工具版本的选择策略
如何使用新版本J-Flash编程CW32 MCU
【重要通知】华秋DFM旧版本暂停服务公告
HarmonyOSAI编程DevEco AI辅助编程工具
MES工具更新信息 03/2025

Silicon Labs最新版本Simplicity Studio开发工具包SiSDK 2025.6.0增添多项无线技术协作
如何使用新版本J-Flash编程CW32 MCU?
戴尔数据保护软件迎来全新版本
【文章转载】CANoe产品体系19版本新功能(下) - 基础功能与XIL测试




评论