 当诗人遇到熟读2600亿中文参数的大模型
当诗人遇到熟读2600亿中文参数的大模型

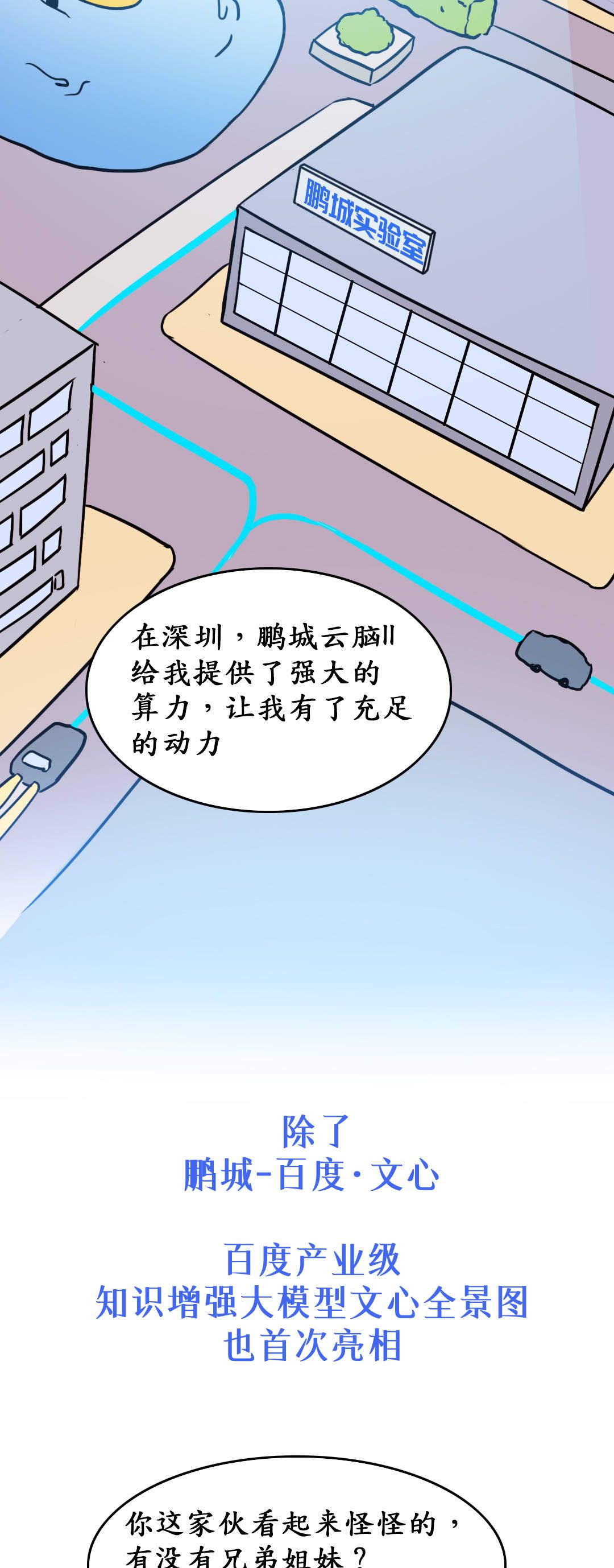
中文,是世界上公认最难的语言。中文有超过十万个字符,这些字符又有自己独立的符号和丰富的含义。交织起来,形成了我们日常应用的语言和文字,结合人类世界庞大的知识系统。让人类学习中文,都不那么容易,更别提人工智能了。为了满足智能对话、文本生成理解等等需求,开发者们往往要付出大量的开发成本。而最近,百度联合鹏城实验室发布了鹏城-百度·文心千亿大模型,它的参数规模达到2600亿,是全球首个知识增强的超大模型。文心的出现,能否为AI开发降低成本,帮助AI更快开启工业化落地之路?




























声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
AI
+关注
关注
89文章
38153浏览量
296811
发布评论请先 登录
相关推荐
热点推荐
浅谈SPICE模型参数自动化提取
在过去的几十年里,半导体器件紧凑型模型已经从 BJT Gummel-Poon 模型中的几个参数发展到 MOSFET BSIM 模型
宁畅与与百度文心大模型展开深度技术合作
与部署。 凭借覆盖训练、推理、微调全流程的AI 服务器产品矩阵,宁畅帮助企业在大模型时代一键打通算力与应用“任督二脉”,显著缩短模型落地周期。 在已启动的深度技术合作中,双方将基于文心

龙芯中科与文心系列模型开展深度技术合作
”解决方案。 强强联合!自主架构赋能大模型训练 文心大模型 文心4.5系列模型均使用飞桨深度学习框架进行高效训练、推理和部署。在大语言
兆芯率先展开文心系列模型深度技术合作
对文心系列大模型的快速适配、无缝衔接。 文心大模型 文心4.5系列开源模型共10款,均使用飞浆深度学习框架进行高效训练、推理和部署。
华为助力中国石油发布3000亿参数昆仑大模型
昆仑大模型完成备案,成为中国能源化工行业首个通过备案的大模型,到2024年11月发布700亿参数昆仑大模型建设成果,中国石油始终紧紧围绕行业

IBIS模型中的Corner参数处理
本文聚焦IBIS(I/O Buffer Information Specification)模型中的Corner(Typ/Min/Max)参数处理,系统分析Corner的定义规则及其对信号完整性
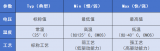
转换Keras H5模型,为什么无法确定--input_shape参数的值?
使用以下命令转换 Keras H5 模型: mo --saved_model_dir model/
遇到以下错误: [ ERROR ] Shape [-1 30 30 3
发表于 03-05 07:51
海康威视发布多模态大模型文搜存储系列产品
多模态大模型为安防行业带来重大技术革新,基于观澜大模型技术体系,海康威视将大参数量、大样本量的图文多模态大模型与嵌入式智能硬件深度融合,发布多模态大
一文说清楚什么是AI大模型
目前,大模型(特别是在2023年及之后的语境中)通常特指大语言模型(LLM, Large Language Model),但其范围也涵盖其他领域的超大规模深度学习模型,例如图像生成





 工商网监
工商网监
评论