 AI算法5秒钟就能克隆你的声音
AI算法5秒钟就能克隆你的声音

今天,给大家介绍一个算法。
AI 算法 5 秒钟,就能克隆你的声音,你信吗?
听听这段音频,猜猜看是 AI 合成音,还是真人录音?
答案是:AI 合成。
这个人的原始声音在这里:
你给这个 AI 克隆声音的算法打几分?
录制一段音频,就可以根据输入的文字,5s 即可自动生成对应的合成音。
突然有个大胆的想法,你说女朋友要是哪天突然不承认自己说过了某句话,我就给她造一份!
兄弟们,我做的对吗?
MockingBird这个算法是基于比较著名的 Real Time Voice Cloning 实现的。
MockingBird 是最近开源的中文版。
论文的名字是:
Transfer Learning from Speaker Verification to Multispeaker Text-To-Speech Synthesis
简单介绍下:
算法分为三个模块:encoder模块、systhesis模块、vocoder模块。
encoder模块将说话人的声音转换成人声的数字编码(speaker embedding)
synthesis 模块将文本转换成梅尔频谱(mel-spectrogram)
vocoder模块将梅尔频谱(mel-spectrogram)转换成(波形)waveform
具体的算法原理,大家可以先看论文:
https://arxiv.org/pdf/1806.04558.pdf
今天主要聊聊,这个算法怎么玩。
项目地址:https://github.com/babysor/MockingBird
有深度学习基础的话,这个应该不难。
就是部署环境,分四步:
Anaconda 配置 Pytorch 开发环境
根据项目 requirements.txt 安装第三方库依赖
下载权重文件
下载训练集,这个几十G,有点大
具体的配置方法,直接看这里:
https://github.com/babysor/MockingBird/blob/main/README-CN.md
环境搭建搞定后,就可以运行代码了。
有两种模式可以启动,Web 模式和工具箱模式。
在项目根目录运行:
python web.py
即可开启 Web ,打开地址 http://localhost:8080 就能操作了。
这个界面比较简陋,建议使用工具箱模式。
python demo_toolbox.py -d 《datasets_root》
datasets_root就是下载好的数据集的地址。
责任编辑:haq
-
语音
+关注
关注
3文章
407浏览量
40091 -
AI
+关注
关注
91文章
41138浏览量
302608
原文标题:危险!我克隆了女朋友的声音
文章出处:【微信号:LinuxHub,微信公众号:Linux爱好者】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录

还在手动拼接 AI 代码?你的 IDE 早就该升级了
如何查看小智是否成功进入声音设置?
欢迎使用中国香河英茂科工豆包智能体
使用NORDIC AI的好处
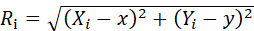
思必驰声音转换算法通过国家备案
【「AI芯片:科技探索与AGI愿景」阅读体验】+AI芯片的需求和挑战
零基础在智能硬件上克隆原神可莉实现桌面陪伴(提供人设提示词、知识库、固件下载)
思必驰声音复刻算法获得深度合成服务算法备案
AI的未来,属于那些既能写代码,又能焊电路的“双栖人才”
思必驰7月份大事件回顾
AP-0316 语音模组:不止是降噪神器,更是即插即用的 USB 声卡全能王
为何时钟晶振用32.768kHz怎么定义一秒钟

声纹解锁个性化!启明云端硅思物语AI平台让设备“认准你的声音”




评论