 如何使用辅助任务来提升情感分类领域适应?
如何使用辅助任务来提升情感分类领域适应?

论文标题:Learning Sentence Embeddings with Auxiliary Tasks for Cross-Domain Sentiment Classification
会议/期刊:EMNLP-2016
团队:Singapore Management University
主要思想: 通过构造两个辅助任务(auxiliary tasks)来从学习句子表示,预测一个句子是否包含有通用情感词。这些句子表示可以增强原本情感分类模型中的句子表示,从而提升模型的总体领域适应能力。
论文要点一览:
1. 借鉴了2006年EMNLP的Structural Correspondence Learning的思想
SCL是2016EMNLP的一篇解决领域适应的论文,想法很新颖。核心想法是,不同领域的文本,通常会有一些通用的“指示词”(称为pivot words/features),比方在词性标注任务中,虽然同一个词性的词可能在不同领域文本中千差万别,但是提示词性的特征往往是类似的,这些共同的特征就称为pivot features。然后,那些随着领域变化的,但跟这些pivot features高度相关的词,就被称为“联系词/对应词”(correspondences),比方在词性标注任务中那些关注的词性对应的词。
领域适应中,麻烦的就是这些随着领域变化的correspondences,它们往往潜藏着类别的信息,但是从表面上看是很领域性的,所以如果有办法把这些词中潜藏着的通用的类别信息给提取出来,或者把它们给转化成通用的信息,那这些领域性的词就变得通用了,就可以适应不同领域了。
这个想法,确实很有意思,值得我们学习。所以这个SCL要解决的关键问题就是,如何让模型看到这些领域词,能转化成通用词。比如在情感分类中,看到评论“这个电脑运行很快!”就能反应出来这个就是“这个电脑好!”。SCL的方法就是,我有一个通用词的list,把这些词从句子中挖去,然后让剩下的部分来预测出是否包含这个词。构造这样的任务,就相当于学习一个“通用语言转化器”,把个性化的语言,转化成通用的语言。
当然,由于是2006年的论文,所以是采用传统的机器学习方法来做,得到句子表示也是通过矩阵分解这样的方法。这个16年的新论文,则是使用的深度学习的方法进行改良和简化,让它变得更强大。
2. 跟传统经典方法的的主要不同
本文提到的主要传统方法有两个,一个就是著名的06年的SCL,一个是大名鼎鼎的Bengio团队在11年ICML的使用auto-encoder的工作。
这两个工作的一个共同点是,是分两步进行的,即是一个序列化的方法(learn sequentially),先得到一个特征表示,改善原来的文本特征,然后再使用经典的模型进行预测。
本论文提出的方法,既可以是两步走的序列化方法,也可以是joint learning,让辅助任务跟主任务共同学习。
另外,之前的auto-encoder的做法,在数据预处理的步骤,没有考虑情感分类任务,也就是跟最终要做的任务无关,这当然也不够好。
3. 本文是一个transductive方法,即训练的时候要利用到全局数据
训练可用的数据包括:
有标签的训练集(source domain)
无标签的测试集(target domain)
4. 辅助任务的设计&对原句子表示的加强
作者设计了两个辅助任务:预测一句话中是否有正/负的通用情感词。
当然,预测前,需要把句子中的通用情感词给挖掉,用剩下的词来预测。这样设计的依据是什么呢?如果一句话中包含来通用情感词,比如“好”,那么这句话多半就是正面的情感,那么这句话剩下的其他的部分,应该也大概率会包含一些领域特定的反应情感的词,比如“(电脑)很快”。那么我们训练一个能够使用这些领域特定的词预测通用情感词的模型,就可以得到一个“通用情感转化器”,把各种不同领域的句子,转化成通用的表示。
辅助任务的损失函数如下:
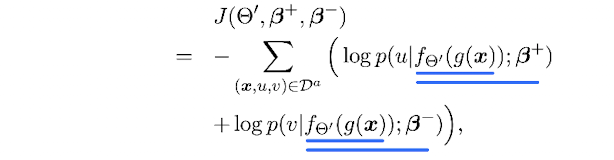
就是二分类交叉熵损失之和。
如下图所示,左半边就是一个传统的分类模型。右边的就是辅助任务对应的模型。
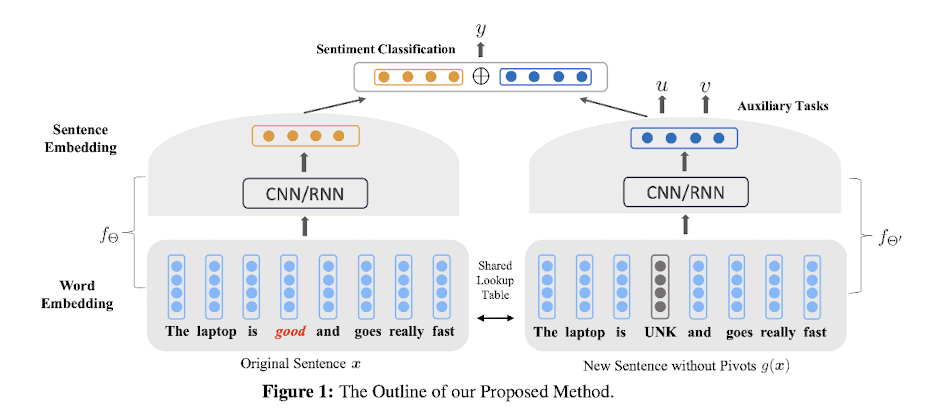
通过把原句子的通用情感词替换成[UNK],然后使用辅助任务训练一个新的模型,就可以得到一个通用的句子表示向量,也就是图中的蓝色的向量。
最后,把这个向量,跟原句子向量拼接起来,就得到来加强版的句子表示,最终使用这个句子表示来做情感分类任务。
5. 联合训练joint learning
上面讲的方法,依然是分两步做的,这样会有些麻烦。其实整个框架可以同时训练,也就是把两部分的损失函数合在一起进行优化:
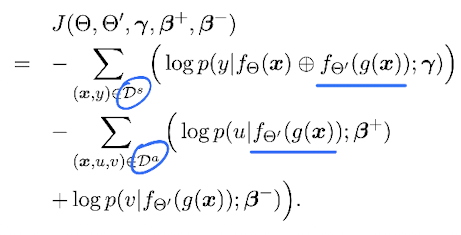
注意,两部分的loss,分别来自不同的数据集,但是在辅助模型分布,是两部分数据都会使用的,见图中画蓝线的地方。
就是代码实现上,我一开始想不通如何让两个不同的数据集(labeled source data和unlabeled target data)放在一起同时训练,看了看作者的代码也没看明白(基于Lua的torch写的),直到我看到了作者readme最后写了一个提示:

就是说,所谓的joint learning,并不是真正的joint,相当于一种incremental learning(增量学习)。每个epoch,先把source部分的数据给训练了,然后再输入target部分来优化auxiliary部分的模型。
6. 如何选择pivot words
本文使用了一种叫weighted log-likelihood ratio(WLLR)的指标来选择最通用的情感词作为pivot words。这个WLLR的公式如下:
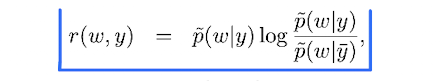
公式里的y就是标签,而y一杠是相反的标签。w则代表某个词。从公式可以看出,当一个词在一个标签的文本中经常出现,而在相反标签的文本中出现很少,那么这个词的WLLR值就高。
在SCL论文中,使用的是互信息,但是作者发现互信息偏爱那些低频词,相比之下WLLR则公平一些,因此作者选择WLLR。
7. 数据集和实验结果
实验结果主要表明,Joint Learning确实可以。但Sequential则效果不敢恭维。。。这一点是我觉得容易让人诟病的地方,毕竟按照前文中介绍的,即使是Sequential,也因为学习到了很好的句子表示,应该效果也很不错才对。
另外实验结果中,对比一下机器学习方法和深度学习方法可以看出,只是用离散特征,效果完全比不是深度学习使用连续特征的方法。注意,这里的NN是指CNN,使用了词向量,而词向量相当于已经拥有了很多外部知识了,所以一个单纯的CNN,不进行任何的domain adaptation的设计,都比传统的SCL等方法都好。
作者还做了一些“使用部分target标注数据来训练”的实验:发现,也有微弱的提升(0.6%实在不算多哈)。并且,随着标注数据量的提升,差距还在缩小:
8. Case Study
这里的case study值得学习,分析的很细致,逻辑清晰,还印证了论文的理论假设。即,作者对比了单纯的CNN和使用了辅助任务来训练的CNN,在分类时的重要词汇是哪些,发现了一些有趣的现象。
我们这里称单纯的CNN为NaiveNN,使用辅助任务的序列化方法为Sequential,联合训练的则为Joint。其中,Sequential和Joint又可以把模型分成两个部分,分别为-original和-auxiliary。
总结一下:
NaiveNN抽取出来的,多半都是“通用情感词”;
Sequential-original提取出来的跟NaiveNN类似;
Sequential-auxiliary提取出的,多半是“领域词”,包括“领域情感词”和“领域类型词”,后者是该领域的一些特征词,但并不是情感词,所以是个噪音,可能会对情感模型产生负面影响;
Joint-auxiliary则提取出的基本都是“领域情感词”,即相比于sequential少了噪音;
Joint-original则可提取出“通用情感词”和“领域情感词”,因为它跟aux部分共享了sentence embedding。
虽然case study一般都是精挑细选过的,但至少作者分析总结的还是很到位,也就姑且信了。
最后:
总的来说,这是一个想法较为新颖,方法较为实用,思路也make sense的工作。巧妙地借用了SCL的思想,并做了合理的简化和升级,取得了还不错的效果。
编辑:jq
-
数据集
+关注
关注
4文章
1240浏览量
26261 -
SCL
+关注
关注
1文章
244浏览量
18067 -
cnn
+关注
关注
3文章
356浏览量
23533
原文标题:使用辅助任务来提升情感分类领域适应
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
九天菜菜大模型agent智能体开发实战2026一月班
汽车驾驶辅助系统领域首个强制性国家标准发布
时间基准的核心力量:低相噪铷原子振荡时钟的多领域应用解析
LuatOS AGPS 辅助定位开发实战教程
广和通发布端侧情感对话大模型FiboEmo-LLM
【「AI芯片:科技探索与AGI愿景」阅读体验】+AI的未来:提升算力还是智力
Task任务:LuatOS实现“任务级并发”的核心引擎

用快手电商 API 实现快手小店商品评论情感分析

QNX助力WeRide打造高级辅助驾驶系统
【「DeepSeek 核心技术揭秘」阅读体验】+混合专家
51Sim利用NVIDIA Cosmos提升辅助驾驶合成数据场景的泛化性
利用NVIDIA Isaac Lab训练工业机器人齿轮装配任务

SMA接口在汽车电子复杂环境下的适应性剖析

NVIDIA如何让灵巧机器人更加适应环境




评论