 胶囊网络在小样本做文本分类中的应用(下)
胶囊网络在小样本做文本分类中的应用(下)

论文提出Dynamic Memory Induction Networks (DMIN) 网络处理小样本文本分类。
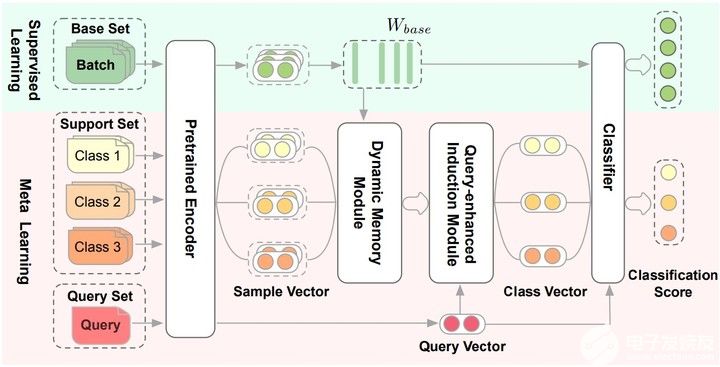
两阶段的(two-stage)few-shot模型:
在监督学习阶段(绿色的部分),训练数据中的部分类别被选为base set,用于finetune预训练Encoder和分类器也就是Pretrained Encoder和Classfiier图中的部分。
在元学习阶段(红色的部分),数据被构造成一个个episode的形式用于计算梯度和更新模型参数。对于C-way K-shot,一个训练episode中的Support Set是从训练数据中随机选择C个类别,每个类别选择K个实例构成的。每个类别剩下的样本就构成Query Set。也就是在Support Set上训练模型,在Query Set上计算损失更新参数。
Pretrained Encoder
用[CLS]预训练的句子的Bert-base Embedding来做fine-tune。$W_{base}$ 就作为元学习的base特征记忆矩阵,监督学习得到的。
Dynamic Memory Module
在元学习阶段,为了从给定的Support Set中归纳出类级别的向量表示,根据记忆矩阵 $W_{base}$ 学习Dynamic Memory Module(动态记忆模块)。

给定一个 $M$ ( $W_{base}$ )和样本向量 q , q 就是一个特征胶囊,所以动态记忆路由算法就是为了得到适应监督信息 $ W_{base} $ 的向量 $q^{'}$ ,
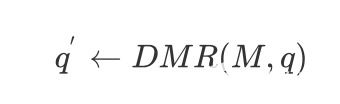
$$ q^{'} \leftarrow DMR(M, q) $$ 学习记忆矩阵 $M$ 中的每个类别向量 $M^{'} $ 进行更新,
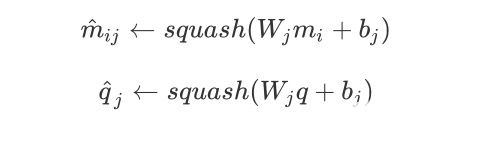
其中
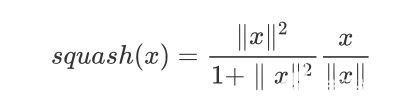
这里的 $W_j$ 就是一个权重。因此变换权重 $W_j$ 和偏差 $b_j$ 在输入时候是可以共享的, 因此计算 $\hat{m}{ij}$ 和 $\hat{q}_j$ 之间的皮尔逊相关系数
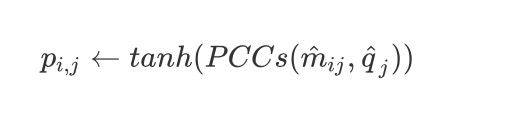
其中
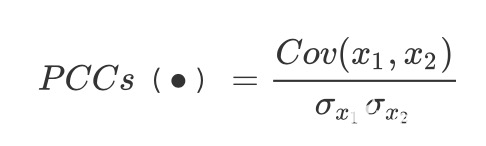
接下来就是进行动态路由算法学习最佳的特征映射(这里添加了$p_{ij}$到路由协议中),到第11行为止。从第12行开始也会根据监督学习的记忆矩阵和胶囊的皮尔逊相关系数来更新$p_{ij}$,最后把部分胶囊
编辑:jq
-
数据
+关注
关注
8文章
7357浏览量
95108 -
Query
+关注
关注
0文章
11浏览量
9663 -
小样本
+关注
关注
0文章
7浏览量
6940 -
动态路由
+关注
关注
0文章
17浏览量
23499 -
网络处理
+关注
关注
0文章
5浏览量
6490
发布评论请先 登录
在 FreeRTOS 下的 RT595 上使用 DMIC DMA 进行音频录制时遇到的问题求解决
新一代单目标 AI 跟踪算法,解决典型困难场景下的跟踪稳定性问题

机器学习特征工程:分类变量的数值化处理方法

海伯森点光谱应用案例之--医用胶囊盖体弧度检测

Linux Shell文本处理神器合集:15个工具+实战例子,效率直接翻倍

TDK 2022样本套件中的NTC热敏电阻:工业温度测量的理想之选
TDK PTC热敏电阻:低压应用加热元件样本套件解析
激光焊接机在焊接胶囊胃镜工艺中的应用
基于级联分类器的人脸检测基本原理
CNN卷积神经网络设计原理及在MCU200T上仿真测试
在Ubuntu20.04系统中训练神经网络模型的一些经验
RFID在垃圾分类中的核心优势

模板驱动 无需训练数据 SmartDP解决小样本AI算法模型开发难题

时间同步设备在复杂网络环境中的调试要点

飞书开源“RTV”富文本组件 重塑鸿蒙应用富文本渲染体验



评论