 超详细EMNLP2020 因果推断
超详细EMNLP2020 因果推断

引言
X,Y之间的因果性被定义为操作X,会使得Y发生改变。在很多领域如药物效果预测、推荐算法有效性,因果性都有着重要作用。然而现实数据中,变量之间还会存在其他的相关关系(confounding)。如何从观察获得的数据中发现不同因素之间的因果关系则是统计学、机器学习和人工智能领域具有挑战性的重要研究问题---统计推断。
本次Fudan DISC实验室将分享EMNLP 2020中有关因果推断的3篇论文,介绍在不同任务下因果推断方法的应用。
文章概览
基于因果推理的逻辑相关多任务学习研究
Exploring Logically Dependent Multi-task Learning with Causal Inference
论文地址:
https://www.aclweb.org/anthology/2020.emnlp-main.173
该篇文章从因果推理的角度出发,使用mediation assumption对逻辑依赖的MTL进行了研究。具体模型使用label transfer利用之前的低级逻辑依赖的任务label,以及Gumbel sampling方法来处理级联错误。
脚本知识的因果推理
Causal Inference of Script Knowledge
论文地址:
https://www.aclweb.org/anthology/2020.emnlp-main.612
该篇文章从概念和实践的角度论证了纯粹基于相关性的方法对于脚本知识归纳是不够的,并提出了一种基于事件干预评估因果效应的脚本归纳方法。
使用因果关系消除偏见的法院意见生成
De-Biased Court’s View Generation with Causality
论文地址:
https://www.aclweb.org/anthology/2020.emnlp-main.56
本文提出了一种新的基于注意力和反事实的自然语言生成方法(AC-NLG),该方法由一个注意力编码器和一对反事实译码器组成。注意力编码器利用原告的索赔和事实描述来学习索赔感知的编码表示。反事实译码器被用来消除数据中的混淆偏差,并与协同的判决预测模型结合来生成法院意见。
论文细节
1

论文动机
以往的研究表明,分层多任务学习(MTL)可以通过堆叠编码器和输出形式的民主MTL来利用任务依赖性。然而,在逻辑相关的任务中,堆叠编码器只考虑特征表示的依赖性,而忽略了标签的依赖性。MLT的三种结构如下图所示
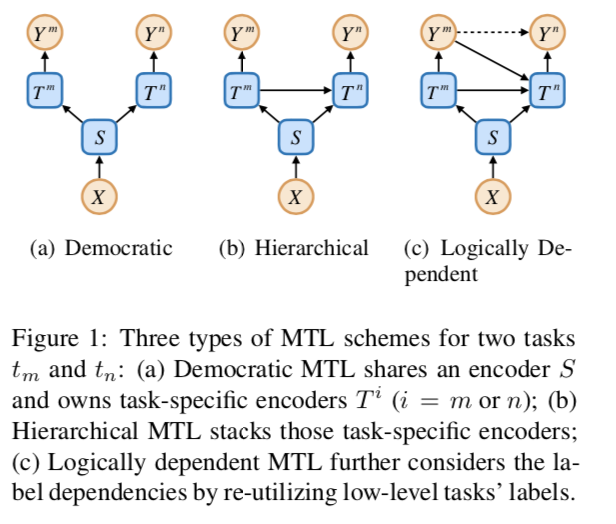
从因果关系的角度来看,前两个方案假设ym和yn是条件独立的,而第三个方案假设ym对yn有因果关系。在这篇文章中,作者认为因果关系对于逻辑相关的任务是重要的,并提出了一种称为标签转移(label transfer,LT)的机制,使得一个任务可以利用其所有较低级别任务的标签。
当使用前任务的标签时,会引入训练和测试的分歧问题。也就是说该策略在训练中使用低水平任务的标注标签,在测试中则需要使用预测的标签,这样会导致任务之间的级联错误。本文使用Gumbel抽样(GS)来解决这个问题。具体来说,模型从每个任务的预测概率分布中抽取一个标签,并将其提供给更高级别的任务。抽样可以看作是一个反事实推理过程,可以估计不同任务标签之间的因果关系。如果因果效应存在,反向传播的梯度将惩罚错误的预测。
方法
1. Basic Causal Assumptions
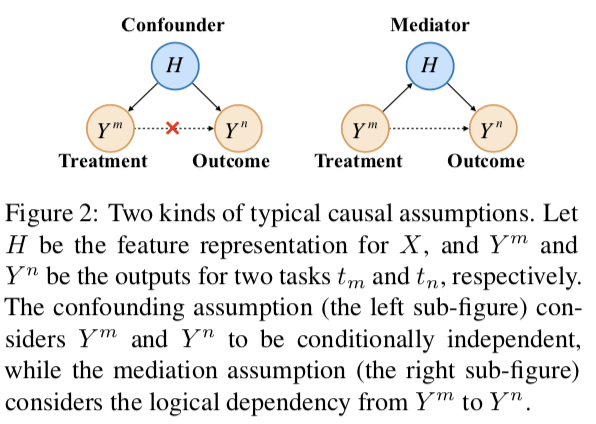
如上图MTL有两种可能的因果假设:confounding 和 mediation。confounding假设是,Ym和Yn是条件独立的,仅由H决定。然而,对于逻辑相关的任务,文章使用mediation假设,即Ym对Yn有因果关系。具体来说,此假设包括Ym和Yn之间的两条因果路径。通过媒体H(实线),称为间接效应。另一个直接链接Ym到Yn(虚线),称为直接效果。一条是通过metiator H(实线)把Ym和Yn联系起来的,称为间接效应。另一个直接连接Ym到Yn(虚线),称为直接效应。
2. Full Causal Graphs
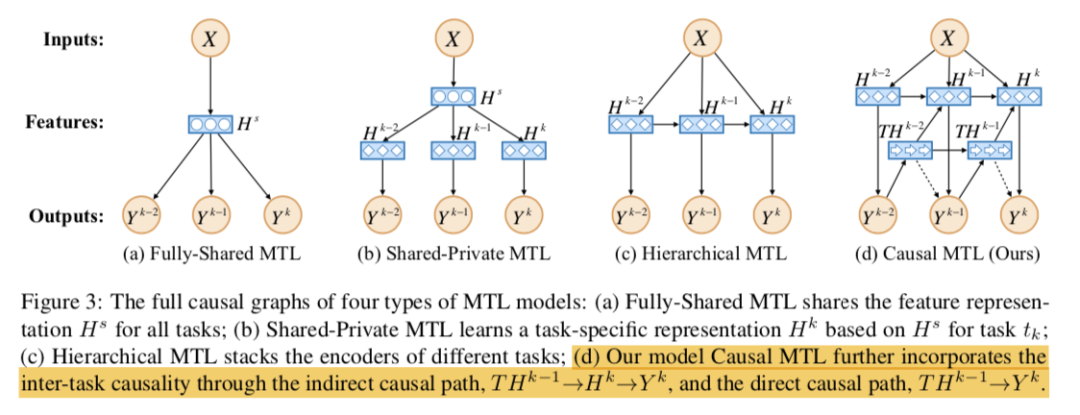
CMTL通过两条路径将任务间因果性结合起来。它首先创建一个中间变量传达之前所有任务的标签信息。然后该模型考虑了路径→→的间接因果效应,还包括路径→的直接因果效应。
3. Model Details
完整模型结构下图所示。
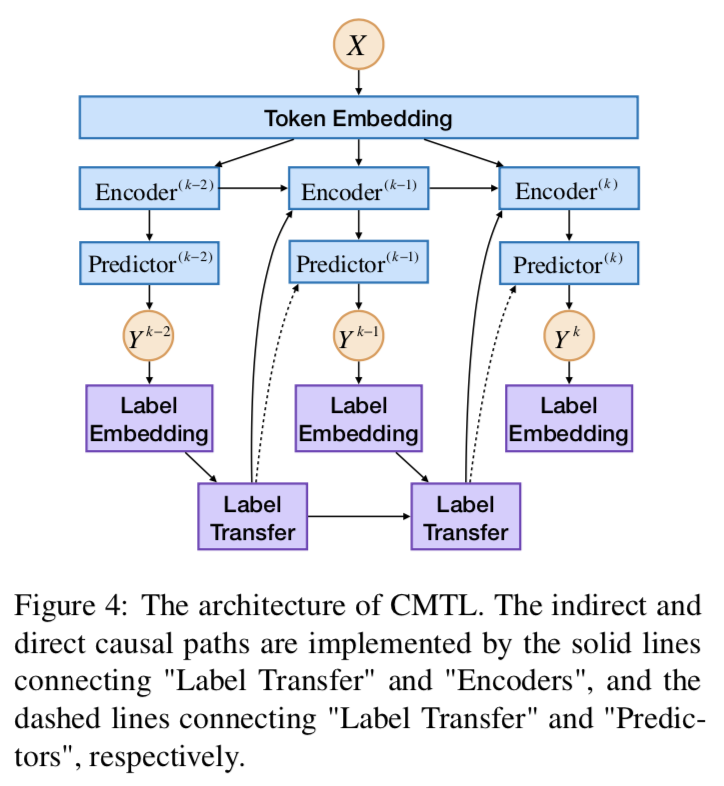
Label Transfer LT使用RNN-LSTM的结构来编码:
**Encoders ** 然后将被送入编码器。如图所示,Encoder^(k) 的输入包括三个部分:词嵌入、转移标签和k-1层的输出。输出可表示为:
¥4f对于JERE和ABSA任务编码器使用Bi-LSTM。对于LJP任务,先使用CNN编码句子,随后使用LSTM编码标签嵌入。
Gumbel Sampling GS使用重参数技巧来估计多项抽样:
其中g符合Gumbel(0,1),是温度参数。在训练过程中将使用来代替标注标签。这样低水平的任务将有一定的概率抽样一个反事实的值,如果因果关系确实存在,会从高水平的任务得到反馈。
4. 因果解释
估计任务tm的标签对任务tn的标签的因果效应:
除了估计标签的因果效应外,还可以检验X中n-grams元素的影响。对原始序列进行干预,得到另一个文本序列,其中n-gram 被屏蔽。由于n-gram可能非常稀疏,因此仅对单个因果效应进行了估计:
实验结果
1. 主要结果
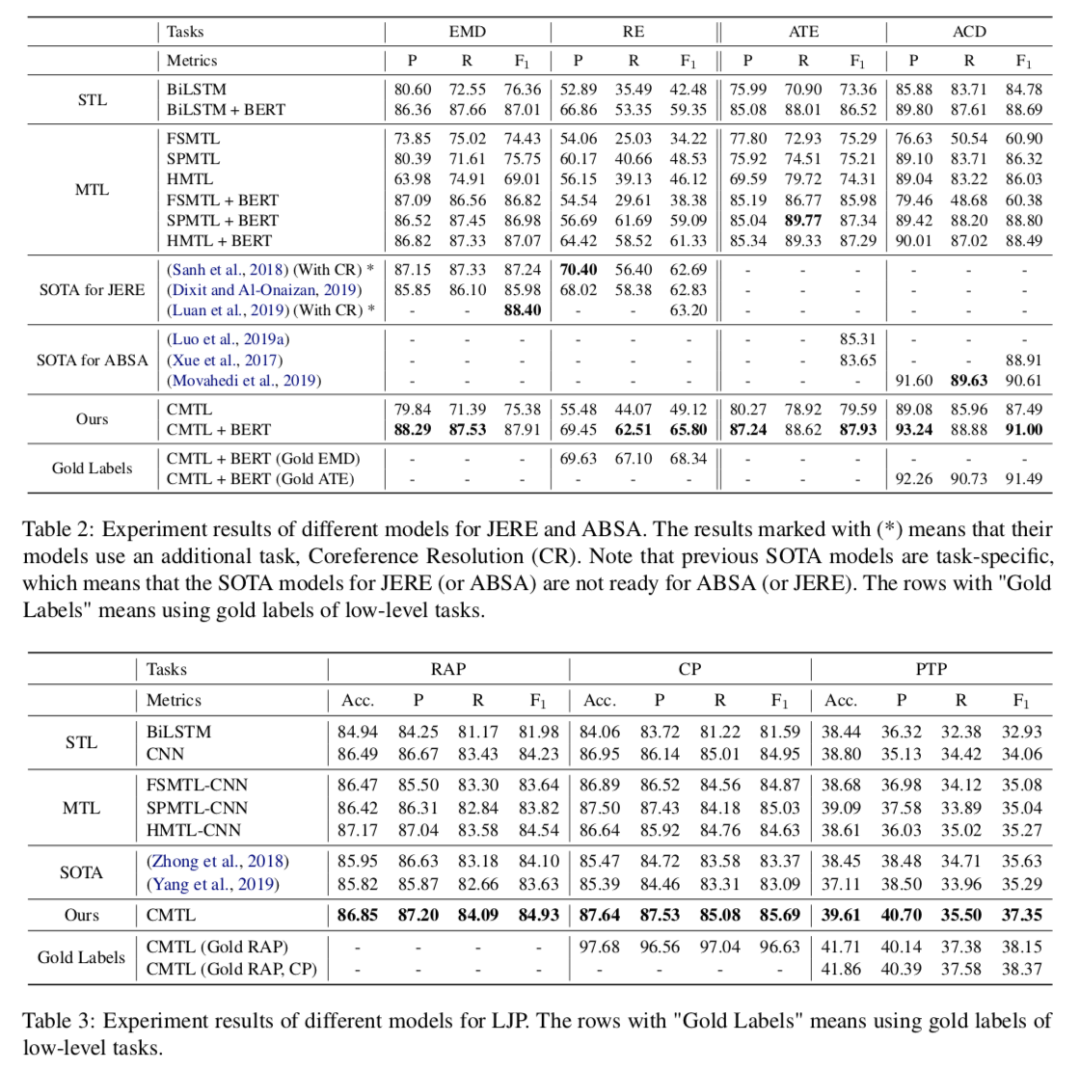
在三个任务上模型都有所提升。
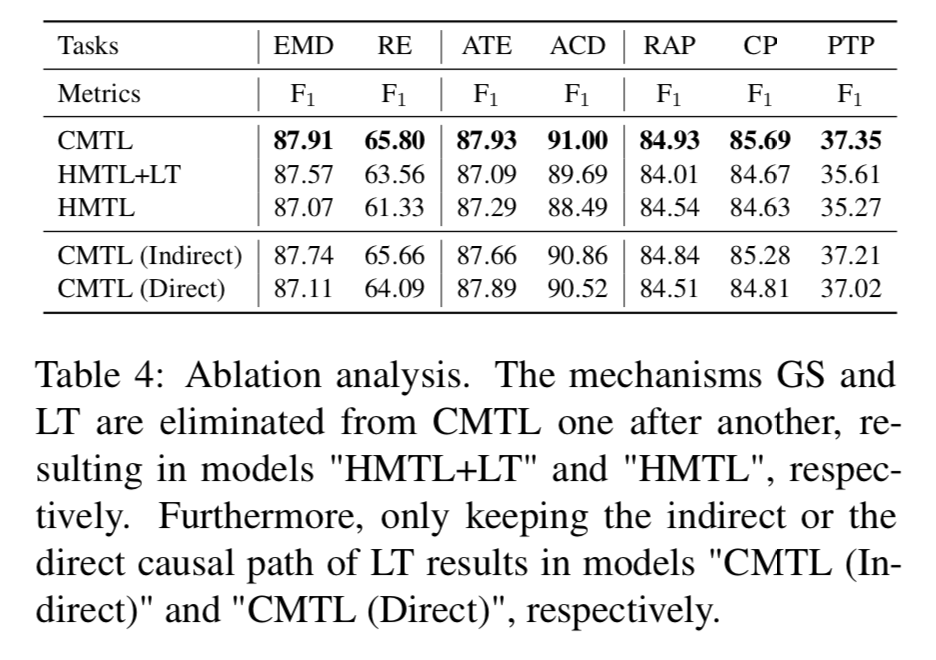
如图所示,GS和LT对模型都是有影响的,特别是对于高水平的任务。例如,消除GS导致RE的F1得分下降2.24分,消除这两种机制导致显著下降4.47分。此外,文章保留了CMTL的间接因果路径或直接因果路径,分别记为CMTL(间接)和CMTL(直接)模型。两种相关模型的性能都略差于CMTL。
2. 案例分析

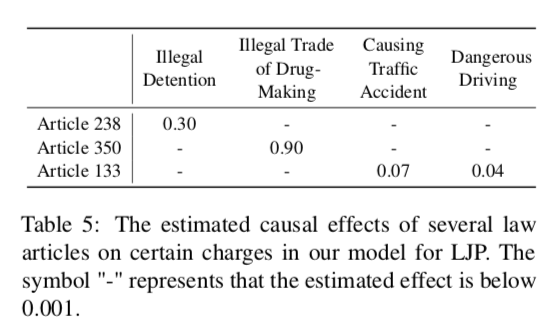
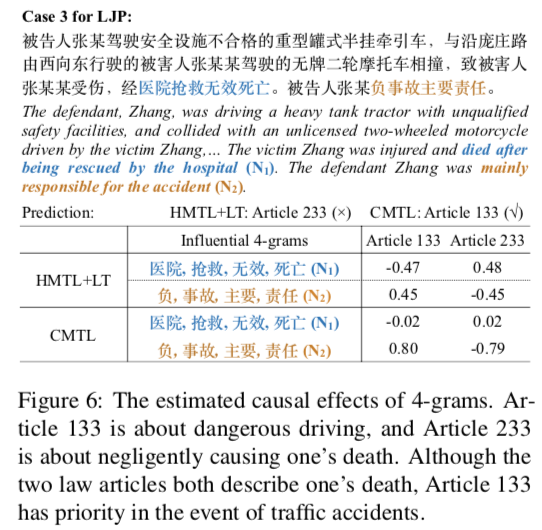
3. 因果效应估计
2

论文动机
长期以来典型事件序列所定义的日常情景的常识性知识,一直被认为在文本理解和理解中起着重要作用。通过数据驱动的方法从文本语料库中学习这样的知识需要确定定量度量标准。虽然观察到的事件之间存在相关性,但相关性并不是决定事件是否形成有意义脚本的唯一因素。这篇文章则提出基于因果关系的方法,用于提取脚本知识。
方法
Step 1: Define a Causal Model
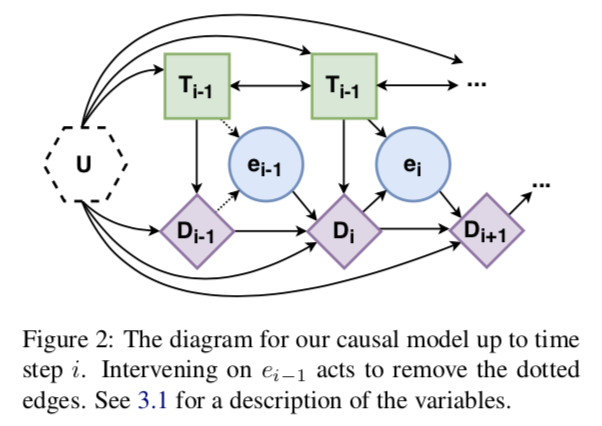
世界,U:生成数据的起点是真实世界,由未测量的变量U显式表示。这个变量是不可知的,通常是不可测量的:我们不知道它是如何分布的,甚至不知道它是什么类型的变量。这个变量由图2中的六边形节点表示。
Text,T:下一种类型的变量是文本。将文本分割成块T1,…,TN,其中N是文本中事件数。因此,变量Ti是与文本中提到的第i个事件相对应的文本块。
事件推断,e:读取一段文本,并推断文本中提到的事件类型。这个类型在模型中由变量 表示,其中E是一组可能的原子事件类型。文本直接因果影响推断的时间类型,所以文本有指向事件的单向箭头。
语篇表征,D:变量ei表示Ti中部分语义内容的高层次抽象。而文本中发生过事件以及它们之间的因果关系是人类阅读时的核心部分,这种信息会显著影响读者基于事件的推理。因此,引入一个话语表征变量,它本身就是两个子变量和的组合。
Step 2: Establishing Identifiability
由后门准则知道:
使用蒙特卡洛估计上述期望。
Step 3: Estimation
通过机器学习方法上述中的
Extracting Script Knowledge
令,则脚本相容分数(因果分数)为。
实验结果
使用人工分别对事件对和事件链评分的结果如下:
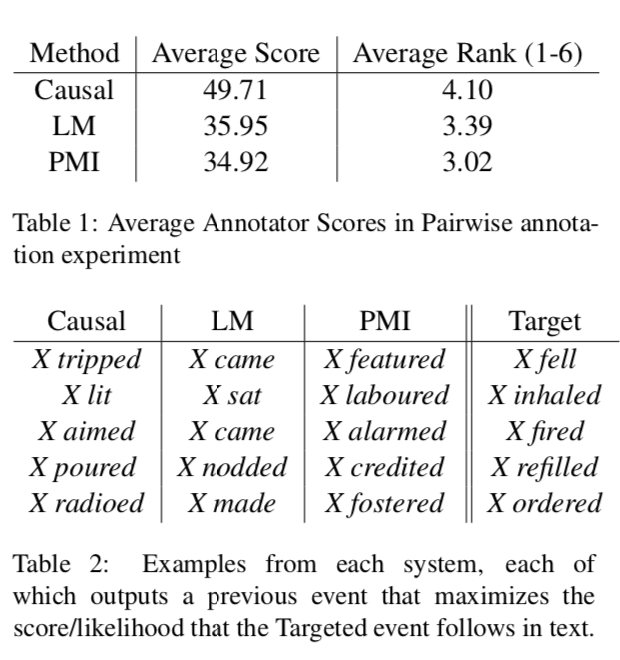
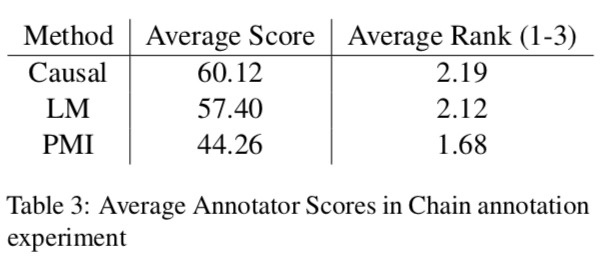
结果表明因果模型的分数更高。
3

论文动机
法院意见生成是法律人工智能的一项新颖而重要的任务,旨在提高判决预测结果的可解释性,实现法律文书的自动生成。虽然先前的文本到文本的自然语言生成(NLG)方法可以用来解决这个问题,但是他们都忽略了数据生成机制中的混淆偏差,这样会限制模型的性能,影响学习结果。主要挑战有:1. 民事法律制度中的“无诉不审”原则,使得判决需要回应原告的索赔;2. 民事案件中判决的不平衡,由于原告只会在有很大把握的前提下提起诉讼,也就导致大部分的判决都是支持的,这样就形成了数据分布不均。
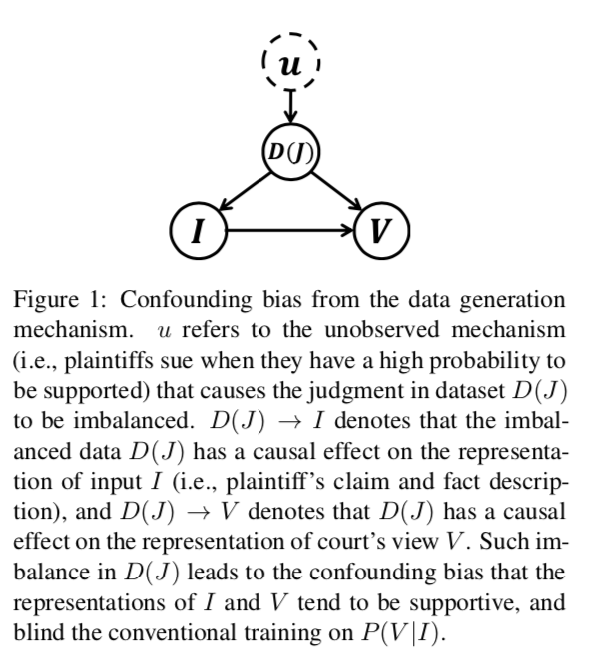
如上因果图角度看,判决的不平衡揭示了数据生成机制导致的混淆偏见。这种不平衡的数据将导致输入(索赔和公认事实)和输出(法院观点)的学习表示倾向于支持,导致输入和输出之间的混淆偏差,并影响传统NLG模型的训练。
针对这些问题,文章提出了一种基于注意力和反事实的自然语言生成(AC-NLG)方法,通过联合优化一个索赔感知编码器、一对反事实解码器来生成判决分辨性法院意见和一个协同判决预测模型。
方法
Backdoor Adjustment
对于一般的生成任务,我们需要计算:如果 ,则 退化为 , 将会忽略 时的表示。后门调整是因果推理中的一个消除混淆的技术。后门调整对进行操作,将后验概率从被动观察提升到主动干预。后门调整通过计算介入后验P(V | do(I))和控制混杂因子来解决混杂偏差:。后门调整切断了和之间的依赖。
Backdoor In Implementation
实现过程中,使用一对反事实解码器估计,使用判据预测模型估计。
Model Architecture
Claim-aware Encoder:原告的权利要求c和事实描述f是句子形式。因此,编码器首先将单词转换为嵌入词。然后将嵌入序列反馈给Bi-LSTM,产生两个隐藏状态序列hc、hf,分别对应于原告的请求和事实描述。之后,我们使用Claim-aware attention来融合hc和hf。对于hf中的每个隐藏状态,是其对的注意权重,注意分布计算如下:
随后产生新的事实描述表示:
经过Bi-LSTM层,得到最终表是。
Judgment Predictor:使用全连接层由h生成判决的概率预测:
Counterfactual Decoder:为了消除数据偏差的影响,使用一对反事实解码器,其中包含两个解码器,一个用于支持的情况,另一个用于不支持的情况。这两种译码器的结构相同,但目的是产生不同判决的法院观点。运用了注意机制:在每个步骤t,给定编码器的输出和解码状态,注意力分布的计算方法与相同,但参数不同。上下文向量是h的加权和:
。上下文向量与解码状态相连接并送到线性层以产生词汇分布:
实验结果
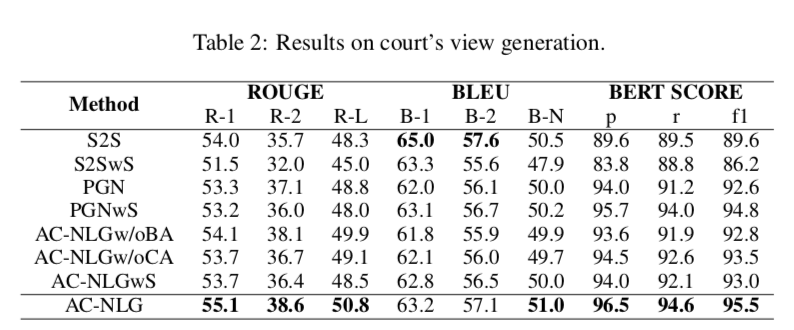
上图显示了法院意见生成的一些评估指标:ROUGE, BLEU, 和 BERT SCORE分数。可以得出:
(1)S2S倾向于重复单词,这使得其BLEU得分较高,而BERT得分较低
(2) 过采样策略对模型没有好处,因此,它不能解决混淆偏差
(3) 与基准相比,AC-NLG具有索赔感知编码器和后门反事实解码器,在法庭视图生成方面取得了更好的性能
(4) AC NLGw/oCA和AC-NLG之间的性能差距证明了索赔感知编码器的有效性,AC NLGw/oBA和AC-NLG之间的差距说明了反事实解码器的优越性。
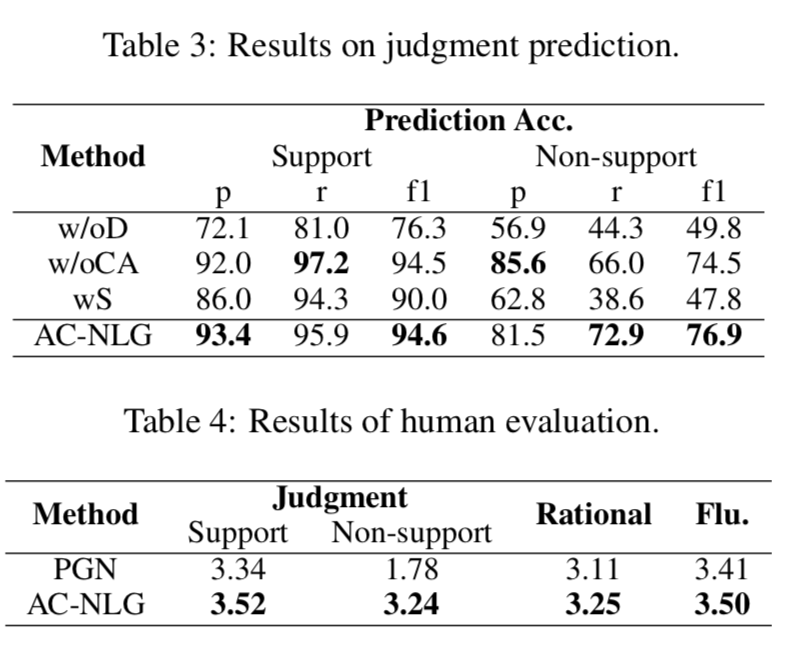
上图显示了判决预测准确率以及人类评估结果:
判据预测结果:
(1) 模型中反事实译码器可以显著地消除混淆偏差,从而在不支持的情况下获得显著的改进,例如将f1从49.8%提高到76.9%
(2) 提出的索赔感知编码器是为提高生成质量而设计的,对判决预测的影响有限。
(3) 过采样并不能给模型带来任何改进。
人类评估结果:
(1) 由于数据中的混杂偏差,PGN中的判决生成在无支持案例中的表现较差,支持案例和无支持案例之间的表现差距很大(1.56)
(2) 通过使用后门反事实解码器,AC-NLG大大提高了判决生成的性能,特别是对于不支持的情况,并且在支持和不支持的情况之间实现了较小的性能差距(只有0.28)
(3) AC-NLG使用了一个支持索赔的编码器,在理性和流畅性方面也取得了更好的性能

上图展示了不同模型产生的法院观点。
总结
此次 Fudan DISC 解读的三篇论文围绕因果推断的应用。对于多任务学习,可以考虑任务标签之间的因果性。对于抽取任务,可以考虑使用因果性评估来筛选想要的抽取内容。对于数据集有偏差的文本生成任务,因果推断可以帮助消除混淆偏差。
编辑:jq
-
编码器
+关注
关注
45文章
4011浏览量
143373 -
译码器
+关注
关注
4文章
313浏览量
52440 -
自然语言
+关注
关注
1文章
292浏览量
14026
原文标题:EMNLP2020 因果推断
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
一文读懂:超景深显微镜的原理

《TEC 温控为什么总是超调?手把手调 PID》
村田LQP01W系列01005超微型电感在可穿戴设备中

超稳激光器与超稳腔技术:从基础理论到前沿应用

超景深显微镜在材料学中的应用
云知声论文入选自然语言处理顶会EMNLP 2025

Keithley 6517B静电计如何实现超微电流测量

纳米超疏水涂层介绍 超疏水材料比三防漆好在哪里

超6类网线的典型传输速率是多少-科兰
超6类网线的传输速率是多少m
超6的网线有屏蔽吗?
AI智能体的技术应用与未来图景
CST+FDTD超表面逆向设计及前沿应用
推断补贴率超700%!美国欲制裁中国电池材料公司
超六类网线怎么接



评论