 Arm Neoverse家族新增V1和N2两大平台,突破高性能计算瓶颈
Arm Neoverse家族新增V1和N2两大平台,突破高性能计算瓶颈

Arm 近日公开了Arm® Neoverse V1 和 N2 平台的产品细节,两者满足了基础设施应用的各种需求。这两个平台的设计旨在解决当前正在运行的各种工作负载和应用问题,与上一代N1相比,并分别带来 50%和 40%的性能提升。此外,Arm也同时发布了CMN-700,作为构建基于Neoverse V1和 N2 平台高性能SoC的关键部件。
Neoverse V1:最宽微架构+SVE矢量运算
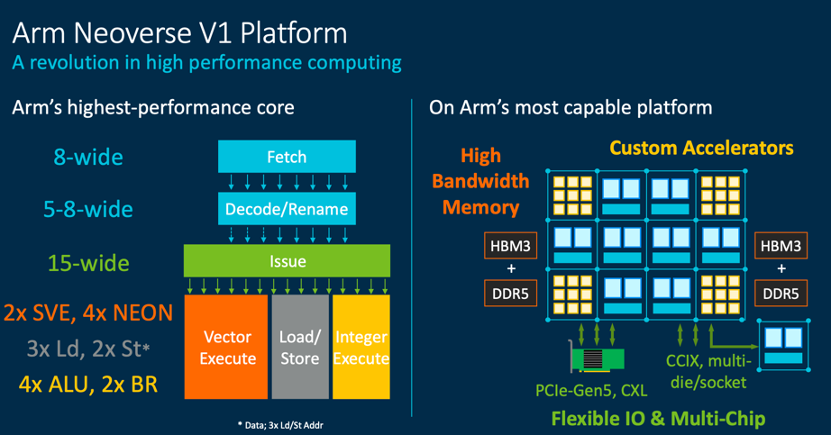
Neoverse V1平台 / Arm
与上一代N1相比,Neoverse V1带来了50%的性能提升和1.8倍的矢量工作负载优化、以及4倍的机器学习工作负载优化。得益于Arm迄今为止最宽的微架构以及SVE功能,Neoverse V1可以容纳更多运行中的指令,延长了代码存活期,也为芯片设计人员提供了灵活性。Arm 现有的 SIMD 指令集 NEON 难以对某些代码进行矢量化处理,而 SVE 可以直接取用相同的代码,并很好地对其进行自动矢量化,相比于 NEON,SVE可将处理速度提高近3.5倍。

已经用到Neoverse V1的HPC项目 / Arm
目前法国芯片公司SiPearl、印度信息技术部(MEITY)韩国电子通信研究所(ETRI)都在各自的HPC项目中用到了Neoverse V1。
Neoverse N2:首个Armv9+SVE2平台
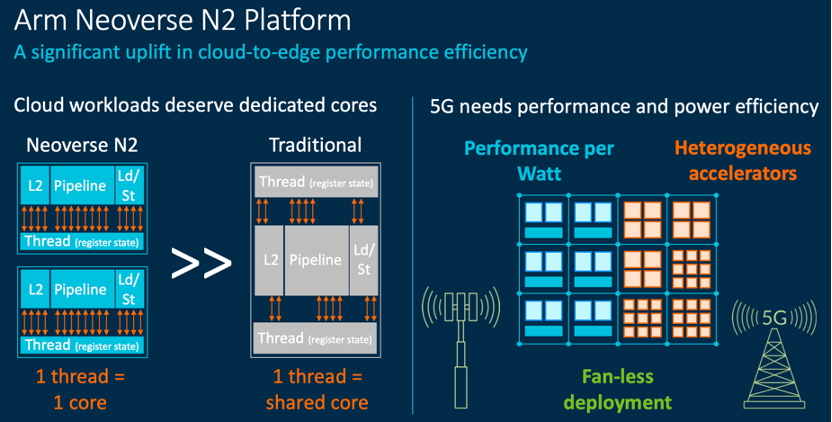
Neoverse N2提高云端到边缘性能效率 / Arm
Arm在几周前发布了Armv9架构,以满足全球对无所不在的专用处理能力的需求,而新公布的Neoverse N2平台正是第一个基于Armv9架构的平台。

SVE2 / Arm
相比于N1,Neoverse N2在保持相同水平的功率和面积效率的基础上,单线程性能提升了40%。不仅如此,Neoverse N2也是第一个具备SVE2功能的平台,作为SVE和Neon的超集,SVE2为云端到边缘的性能效率带来了巨大提升。SVE主要用于加速HPC,而SVE2可广泛运用于机器学习、数字信号处理和5G等应用场景,同时兼具SVE的编程简易性和可移植性等优势。
CMN-700:下一代总线赋能异构SoC

Neoverse CMN-700 / Arm
作为上一代CMN-600的升级,CMN-700支持的最大核心数可达512颗。通过对CCIX 2.0和CXL 2.0的支持,也为客户提供了更多的定制和扩展选项,为紧密耦合的异构计算提供了更大的灵活性。
异构计算的趋势
随着异构计算的逐步发展,我们已经看到了很多CPU和GPU搭配的趋势,比如英伟达近期公布的基于Arm Neoverse的Grace芯片,就是一个用于AI超算的CPU。英伟达在互联技术上采用的是自研的NVLink技术,而非PCIE。Arm基础设施事业部高级副总裁兼总经理 Chris Bergey提到,与多样化的加速器功能进行互联,比如AI加速器,这对未来的市场时相当关键的。比如CMN-700已经支持了CXL和CCIX这样的互联标准,未来Arm期待给市场带来更多的灵活性,并支持更多像Grace这样的系统。
这样的异构趋势也囊括了FPGA,Arm基础设施事业部全球高级总监邹挺补充道,现在已经有合作伙伴将Neoverse N2和FPGA加速卡放在异构计算系统中使用。有的Arm合作伙伴还将FPGA加速器和N2放在一个芯片上做成SoC,通过Chiplet的技术来实现异构计算的灵活性。
公有云的广泛应用

腾讯云加码Arm生态 / Arm 腾讯云
Neoverse的广泛应用在公有云厂商中尤为明显,比如AWS、阿里云和腾讯云等。腾讯专项测试技术中心总监黄闻欣提到腾讯去年和Arm正式签署了一份合作协议,希望通过合作加速Arm Neoverse技术的测评和适配。通过TencentBench测试框架发现,得益于更多可扩展的CPU核心数,Arm服务器比传统的服务器性能表现更强劲,尤其是在AI推理和图片处理领域。
Neoverse V1:最宽微架构+SVE矢量运算
Neoverse V1平台 / Arm
与上一代N1相比,Neoverse V1带来了50%的性能提升和1.8倍的矢量工作负载优化、以及4倍的机器学习工作负载优化。得益于Arm迄今为止最宽的微架构以及SVE功能,Neoverse V1可以容纳更多运行中的指令,延长了代码存活期,也为芯片设计人员提供了灵活性。Arm 现有的 SIMD 指令集 NEON 难以对某些代码进行矢量化处理,而 SVE 可以直接取用相同的代码,并很好地对其进行自动矢量化,相比于 NEON,SVE可将处理速度提高近3.5倍。
已经用到Neoverse V1的HPC项目 / Arm
目前法国芯片公司SiPearl、印度信息技术部(MEITY)韩国电子通信研究所(ETRI)都在各自的HPC项目中用到了Neoverse V1。
Neoverse N2:首个Armv9+SVE2平台
Neoverse N2提高云端到边缘性能效率 / Arm
Arm在几周前发布了Armv9架构,以满足全球对无所不在的专用处理能力的需求,而新公布的Neoverse N2平台正是第一个基于Armv9架构的平台。
SVE2 / Arm
CMN-700:下一代总线赋能异构SoC
Neoverse CMN-700 / Arm
作为上一代CMN-600的升级,CMN-700支持的最大核心数可达512颗。通过对CCIX 2.0和CXL 2.0的支持,也为客户提供了更多的定制和扩展选项,为紧密耦合的异构计算提供了更大的灵活性。
异构计算的趋势
随着异构计算的逐步发展,我们已经看到了很多CPU和GPU搭配的趋势,比如英伟达近期公布的基于Arm Neoverse的Grace芯片,就是一个用于AI超算的CPU。英伟达在互联技术上采用的是自研的NVLink技术,而非PCIE。Arm基础设施事业部高级副总裁兼总经理 Chris Bergey提到,与多样化的加速器功能进行互联,比如AI加速器,这对未来的市场时相当关键的。比如CMN-700已经支持了CXL和CCIX这样的互联标准,未来Arm期待给市场带来更多的灵活性,并支持更多像Grace这样的系统。
这样的异构趋势也囊括了FPGA,Arm基础设施事业部全球高级总监邹挺补充道,现在已经有合作伙伴将Neoverse N2和FPGA加速卡放在异构计算系统中使用。有的Arm合作伙伴还将FPGA加速器和N2放在一个芯片上做成SoC,通过Chiplet的技术来实现异构计算的灵活性。
公有云的广泛应用
腾讯云加码Arm生态 / Arm 腾讯云
Neoverse的广泛应用在公有云厂商中尤为明显,比如AWS、阿里云和腾讯云等。腾讯专项测试技术中心总监黄闻欣提到腾讯去年和Arm正式签署了一份合作协议,希望通过合作加速Arm Neoverse技术的测评和适配。通过TencentBench测试框架发现,得益于更多可扩展的CPU核心数,Arm服务器比传统的服务器性能表现更强劲,尤其是在AI推理和图片处理领域。
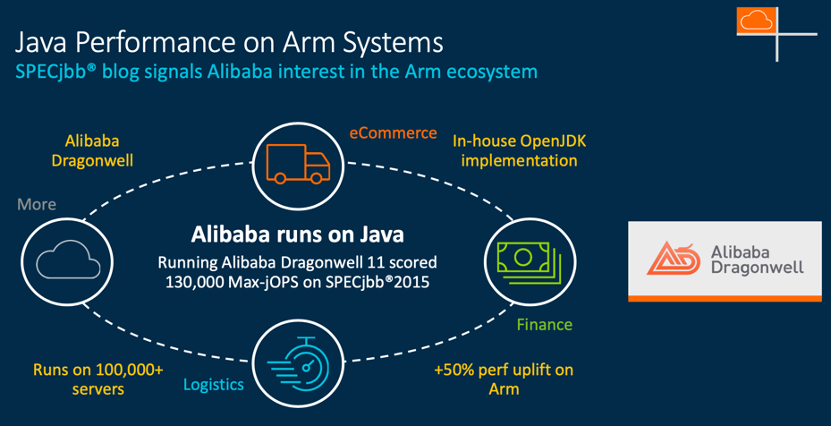
阿里巴巴首席工程师周经森(Kingsum Chow)谈道:Arm的CPU资源的话,在我们现有的软件里会有两个考虑的点,一个是我们有些软件是需要重新编译的,另外一种不需要重新编译,只需要我们把Java applications在JVM(Java Virtual Machine)上跑好就可以了。在这方面,一年之前,我们就跟Arm的员工一起合作,把JVM的性能提高。过去一年里,我们从JDK8到JDK11,通过OpenJDK, 通过阿里巴巴 Dragonwell(OpenJDK的一个发行版),就把我们现有一些Java应用的一些性能提高了50%。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
ARM
+关注
关注
135文章
9615浏览量
394481 -
HPC
+关注
关注
0文章
351浏览量
25116 -
高性能计算
+关注
关注
0文章
97浏览量
13835 -
Neoverse
+关注
关注
0文章
17浏览量
5010
发布评论请先 登录
相关推荐
热点推荐
Onsemi NTTFS1D2N02P1E MOSFET:高性能与紧凑设计的完美结合
Onsemi NTTFS1D2N02P1E MOSFET:高性能与紧凑设计的完美结合 在电子设计领域,MOSFET(金属 - 氧化物 - 半导体场效应晶体管)是不可或缺的关键元件,广泛应用于各种电源
Onsemi NVMFWS2D1N08X:高性能N沟道MOSFET的卓越之选
Onsemi NVMFWS2D1N08X:高性能N沟道MOSFET的卓越之选 在电子设计领域,MOSFET作为关键的功率器件,其性能直接影响着整个电路的效率和稳定性。今天,我们就来深入
探索 onsemi NVMJS1D2N04CL:高性能 N 沟道 MOSFET 的卓越之选
NVMJS1D2N04CL 是 onsemi 精心打造的一款高性能 MOSFET,具有 40V 的耐压能力,极低的导通电阻(低至 1.2 mΩ)和高达 237A 的连续漏极电流,能够满足各种高功率应用的
探索 onsemi NVMYS1D2N04CL:高性能单通道 N 沟道 MOSFET 的技术剖析
探索 onsemi NVMYS1D2N04CL:高性能单通道 N 沟道 MOSFET 的技术剖析 在电子设计领域,MOSFET 作为关键的功率开关元件,其性能直接影响着整个系统的效率和
RZ/N2L Group:高性能MPU的技术剖析与应用潜力
RZ/N2L Group:高性能MPU的技术剖析与应用潜力 在当今电子科技飞速发展的时代,高性能微处理器单元(MPU)对于各种电子设备的性能提升起着至关重要的作用。RZ/
RZ/T2H和RZ/N2H MPU:工业级应用的高性能之选
RZ/T2H和RZ/N2H MPU:工业级应用的高性能之选 作为深耕电子硬件设计领域多年的工程师,我一直关注着高性能MPU在工业应用中的创新与突破
如何在Arm Neoverse N2平台上提升llama.cpp扩展性能
跨 NUMA 内存访问可能会限制 llama.cpp 在 Arm Neoverse 平台上的扩展能力。本文将为你详细分析这一问题,并通过引入原型验证补丁来加以解决。测试结果表明,在基于 Neo
Arm Neoverse平台集成NVIDIA NVLink Fusion
生态系统,实现全缓存一致性与高带宽互连。 随着 AI 数据中心对 Arm Neoverse 的需求持续增长,客户在将工作负载加速器连接至 Arm 平台时拥有更多选择。 人工智能 (A
RISC-V V扩展的指令代码
1.指令集V扩展的主要内容:
矢量指令:针对数据并行性,增加了一系列新的矢量指令,可以同时对多个数据进行操作,提高了计算效率。浮点指令:新增了一些浮点指令,支持更高精度的
发表于 10-21 13:11
全新Arm Lumex CSS平台实现两位数性能提升
及下一代个人电脑加速其人工智能 (AI) 体验的先进计算平台。Lumex CSS 平台集成了搭载第二代可伸缩矩阵扩展 (SME2) 技术的最高性能

西门子 Veloce CS 助力 Arm Neoverse 计算子系统验证与确认
西门子数字化工业软件近日宣布,Veloce Strato CS 与Veloce proFPGA CS 已被 Veloce 的长期合作伙伴 Arm 部署应用,作为Arm Neoverse 计算
知合计算:RISC-V架构创新,阿基米德系列剑指高性能计算
在2025 RISC-V中国峰会上,知合计算处理器设计总监刘畅就高性能RISC-V处理器架构探索与实践进行了精彩分享。 在以X86和ARM为

Arm Neoverse N2平台实现DeepSeek-R1满血版部署
颇具优势。Arm 携手合作伙伴,在 Arm Neoverse N2 平台上使用开源推理框架 llama.cpp 实现 DeepSeek-R

台安N2变频器与Modbus RTU转Profinet网关实现数据互换
在工业自动化领域,Modbus RTU协议与Profinet协议的转换需求日益凸显,尤其是当涉及到台安N2变频器等设备的应用时。本文将深入探讨Modbus RTU转Profinet网关与台安N2变频器通讯的相关知识,帮助读者更好地理解和应用这一技术。




评论