 Series4拥有经得起未来考验的性能和计算密度
Series4拥有经得起未来考验的性能和计算密度

深度学习的多功能性和强大功能意味着现代神经网络在机器翻译、动作识别、任务规划、情感分析和图像处理等领域有着广泛的应用。随着该领域的不断成熟,不可避免的,专业化程度也越来越高,而且呈现加速的趋势。这使保持现有技术水平成为一项挑战,更不用说预测神经网络的未来计算需求了。
神经网络加速器 (NNA) IP 的设计者手头有一项艰巨的任务:确保他们的产品具有足够的通用性,能够应用于当前和未来非常广泛的应用,同时保证高性能。在Imagination公司最前沿的 IMG Series4 NNA 所针对的移动、汽车、数据中心和嵌入式领域中,对带宽、面积和功耗有更严格的限制。Imagination公司的工程师们已经找到了创新的方法来应对这些严峻挑战,并提供超高性能和面向未来的IP。
利用率与灵活性
每个IMG Series4 多核NNA的核心是行业领先的卷积引擎阵列,每秒可执行 10 万亿次操作。四核Series4 NNA每秒可完成惊人的40万亿次操作,简称40TOPS。其架构的一个显著特点是效率:数据尽可能紧密地打包在卷积引擎的输入上,以实现最大可能的利用率,这意味着芯片面积保持最小。Series4 NNA 包含几个高度优化、可快速配置的硬件模块,用于池化、标准化和激活功能等操作。
这种专业化程度显然在网络与硬件很匹配的情况下获得了巨大的回报,也就是说,当网络由卷积层、池化层、激活层等“传统”层组成,但是这样的体系结构如何扩展以支持更复杂的操作,比如注意机制和非最大化抑制?
有两个明显的选择:
在硬件中添加新的专用块。
使硬件具有高度可编程性和通用性。
其中第一个主要问题是,它会导致硬件膨胀和暗硅——如果在一些应用程序中需要多1%的计算时间,那么我们需要一个固定的功能模块吗?不——我们必须获得尽可能重复使用硬件。这也意味着硬件总是保持最前沿的工艺技术。添加固定功能模块说明硬件未来会过时,NNA的设计师们之前遇到过不少硬件适用性受限于操作类型的案例。第一种方法导致硬件膨胀或强制使用额外的“协处理器”,如GPU、DSP或CPU:硅面积、带宽、能量和复杂性都会增加。大多数NNA 设计人员都选择第二种方案。这种方法的例子是基于向量 ALU 和脉动阵列的设计。复杂性从硬件转移到软件,这一切都符合计算机体系结构中历史悠久的 RISC(精简指令集计算机)哲学。然而,要付出巨大的代价——计算密度的降低。为达到40 TOPS 的目标, Series4 NNA架构师必须容忍芯片面积和功耗的大幅增长。Imagination的研究人员认为,一定存在第三种方式。他们的策略是利用新颖的编译技术和他们称之为“简化操作集计算”(ROSC)的新设计理念来换取灵活性。
Series4 NNA具有巨大的计算密度,用于运行标准层,如卷积层、池化层、激活层和完全连接的图层,这些层占据了神经网络中大部分计算需求。从本质上讲,它具有冗余的计算能力。简单地说,ROSC 就是从这个简化的“操作集”中重新配置和重组操作,以构建各种各样的其他操作:乍一看,这些基础操作似乎很难实现。这种重新分配任务通常会导致较低的利用率,因为硬件模块并未用于其主要目的;但是,由于Series4 NNA具有如此多的原始计算能力,即使利用率为1%,例如每秒 400 千兆次操作,在其上运行复杂操作的速度通常仍远远快于在“片外”执行复杂操作的速度,例如在CPU或者GPU上。以这种方式在设备上保持处理可节省宝贵的系统资源,包括 CPU/GPU 时间、功率和带宽。复杂操作可以实施为多个硬件通道的较简单操作计算图。因此,Series4 NNA使用带有张量分块的新型片上存储器系统来保持数据本地化(有关此主题的详细白皮书,请参看链接) - 这可以被用来以最小的系统开销在多个硬件通道上运行复杂的操作。
ROSC 概念背后的关键是,专用硬件模块通常可以配置以执行其他任务。即使由于这种重新分配任务而导致使用率下降,硬件的巨大计算能力也弥补了这一不足。这使得Series4 架构师能够吃上蛋糕——无需额外的硬件复杂性或面积,Series4可以在原始性能很重要的地方具备闪电般的速度,并且在必要时,具有足够的灵活性来处理任意复杂的高级操作。
不要低估架构!
Series4有五种主要可配置的计算硬件模块类型,可称为:
卷积引擎
池化单元
标准化单元
元素操作单元
激活单元
图1:单个硬件模块通常可以配置为执行范围非常广泛的任务。这些可配置的硬件模块每一个都比乍一看可能做的更多。例如,Series 4卷积引擎可以配置为执行图 1所示的操作(以及其他许多操作),而无需依赖于其他计算硬件模块。使用几个这样的模块的组合,可以实现更广泛的操作范围。事实上,Series4可以使用高级的图形降低编译器技术来配置,以覆盖现代神经网络中遇到的几乎所有操作。
标签可能具有误导性。仅仅因为一个硬件模块被标记为“卷积引擎”或“池化模块”并不意味着这是它所能做的全部——在正确的人手中,这些模块可以做的远远超过他们在tin上所说的!下面给出了使用多个硬件模块组合实施复杂操作的两个示例。
Softmax
Softmax是神经网络中的一种常见操作,通常用于需要离散概率的场合。在某些情况下,它也用于使张量进行归一化,以便沿某个轴或多个轴的所有元素都在 [0,1]范围内,且总和为1。在网络中,Softmax通常只占计算的一小部分。例如,在大多数 ImageNet 分类网络中,Softmax占计算的最大比重不到 0.01%。为了与ROSC 避免将芯片面积浪费为“暗硅”的策略保持一致,4系列 没有专用的Softmax硬件;相反,它是在其他可用操作方面实现的。这使它成为我们如何应用上述原则的一个最佳例子。从本质上讲,该策略是用一系列数学上相同但由硬件直接支持的操作构成的操作(“计算子图”)来替换Softmax。Softmax是一个复杂的操作,需要五个阶段,如图2所示。其中四个交叉通道最大化削减、指数、跨通道求和削减和除法——在Series4上也没有专门的硬件!但是,我们可以在Series4上以创造性的方法运行它们,如下所述。图2:将Softmax分解为其组成部分。
一个1×1的卷积与权重张量和一个完全由1组成的过滤器可以用来实现跨通道的求和。
除法可以用一个张量与另一个张量的倒数相乘来实现。Series4的 LRN(本地响应归一化)模块可以配置为计算倒数。
交叉通道最大值可以通过将信道转换置到空间轴上并执行一系列空间最大池化操作来实现。之后,它被转置回通道轴上。
由于指数仅限于负值和零输入值,激活 LUT 可以配置为指数衰减函数。
总之,这将产生一个替换子图,其中包含大约10到15个操作(取决于输入张量的大小),这些操作在几个硬件过程中执行。ROSC的见解是,这个图比在CPU或协处理器上执行更快、更简单。避免了完全可编程和专用固定功能硬件的两种极端情况,并且编译过程中包含了最容易管理的复杂性。
此外,用于Softmax的操作替换可以重用为其他高级操作。一旦实现了一些这样的高级操作,就很容易看到如何构建一个可重用操作替换库,从而使将来的操作更容易降到Series4。这就是ROSC如何引领未来。
三维卷积
卷积引擎和Series4中的相关数据输入和输出针对一维和二维卷积进行了高度优化——这非常有意义,因为在大多数CNN(卷积神经网络)中,这些引擎占据了绝大多数计算量。
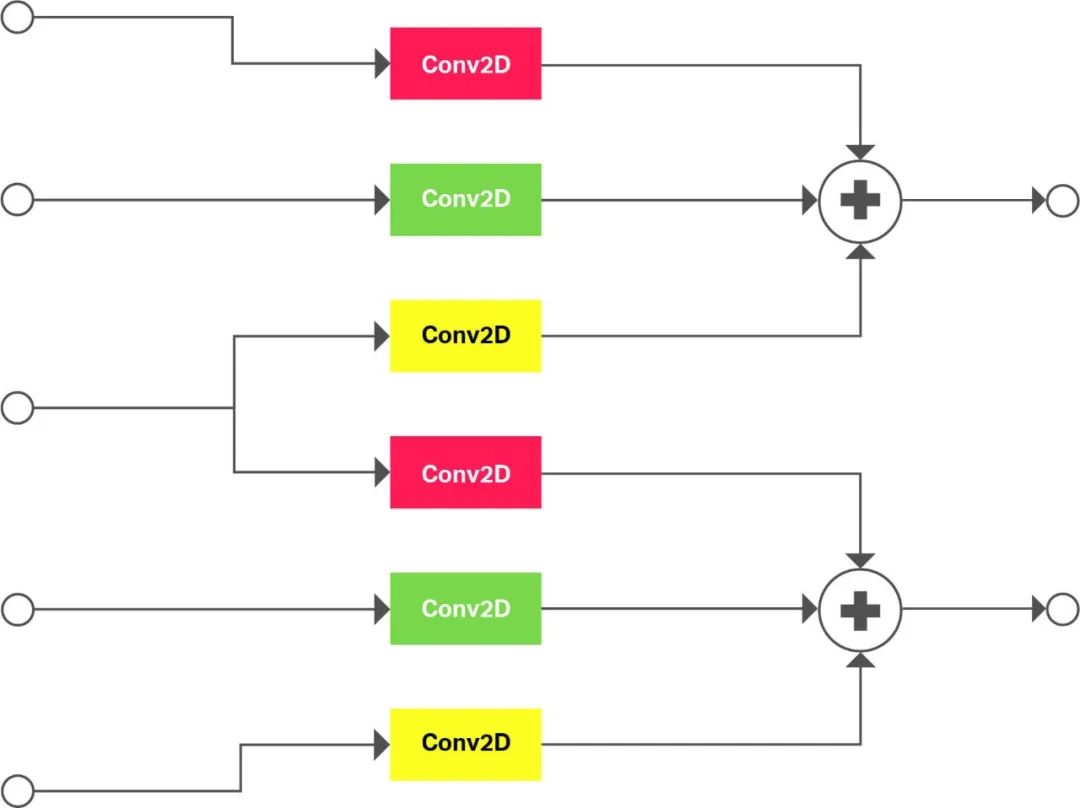
图3:用二维卷积和元素求和实现的三维卷积。
但是,Series4硬件不支持三维和更高维度的卷积。三维卷积是复杂运算的一个具体例子,可使用图形降低技术将其降低到Series4。在这种情况下,该子图是根据二维卷积和元素加法构建的。无论编译器在哪里“看到”原始置身事外中的三维卷积,在Series4上运行的机器代码生成前,编译器都会用该子图形的等效版本替换它。
图3显示了一个三维卷积的例子,在深度轴上,内核大小为3,步长为2。卷积在深度轴上展开。相同颜色的卷积具有相同的权重。这种策略很容易扩展到高维和其他三维操作,如三维池和三维反褶积。这种三维卷积的方法是一个很好的例子,说明了如何将软件设计成与硬件的优点相结合,从而扩展其适用性。
结论
高性能的神经网络加速器很难设计,因为它们需要平衡两个看似矛盾的目标:它们需要大量的并行性和计算密度,以便在几分之一秒内完成一个典型神经网络中的数百万个操作;它们需要足够的灵活性来处理这些问题现代神经网络中有数百种不同类型的操作,还有那些尚未被发明的操作!通常必须在高效、更固定的函数方法和效率较低但更通用的方法之间进行折衷。Imagination公司的工程师们已经开发出一种令人兴奋的创新方法,它提供了两全其美的效果。Series4不包含任何近似ALU的可编程性所需的东西,而是有几个非常有效的硬件模块,设计用于执行特定的、通常发生的操作的计算。使用新的编译技术可以实现完全的灵活性,通过这种技术,可以从一组简化的基本操作中构建非常广泛的操作。这种方法被称为简化运算集计算(简称ROSC)。通过以这种方式协调硬件和软件设计,Series4拥有经得起未来考验的、世界一流的性能和计算密度,同时又不牺牲灵活性。
原文标题:灵活、面向未来、高性能推理的简化操作集计算
文章出处:【微信公众号:Imagination Tech】欢迎添加关注!文章转载请注明出处。
责任编辑:haq
-
神经网络
+关注
关注
42文章
4842浏览量
108188 -
深度学习
+关注
关注
73文章
5608浏览量
124637
原文标题:灵活、面向未来、高性能推理的简化操作集计算
文章出处:【微信号:Imgtec,微信公众号:Imagination Tech】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
深入理解单片机的位数对性能的影响
MLCC电容介电常数对容量密度影响?

国产AI服务器核心工艺突破,高密度贴片良率创新高

高密度光纤布线:未来的数据通信解决方案
OBC功率密度目标4kW/L,如何通过电容选型突破空间瓶颈?
轻量化与高性能兼得:探秘ULTEA®低密度特性在电子材料中的独特优势

您的产品经得起“摔”的考验吗?——跌落试验机全应用

恩智浦MCX C系列MCU助力实现高效迁移
电极压实密度对锂离子电池性能的影响探究

ESP32-P4—具备丰富IO连接、HMI和出色安全特性的高性能SoC
ESP32-P4—具备丰富IO连接、HMI和出色安全特性的高性能SoC
最受欢迎的单板计算机 x 最流行的移动操作系统




评论