 抽取式摘要方法中如何合理设置抽取单元?
抽取式摘要方法中如何合理设置抽取单元?

本期导读:文本摘要技术(Text Summarization)是信息爆炸时代,提升人们获取有效信息效率的关键技术之一,如何从冗余、非结构化的长文本中提炼出关键信息,构成精简通顺的摘要,是文本摘要的核心问题。抽取式摘要则是文本摘要技术中效果稳定,实现简单的一类方法,本文结合COLING 2020中抽取式摘要相关的两篇最新工作,对抽取式摘要方法中如何合理设置抽取单元展开介绍。
引言
在自动文本摘要任务中,抽取式摘要方法是从原文中抽取预先设置好的抽取单元,抽取单元一般为句子、短语或词,目前大多数方法还是以句子为抽取单元,虽然句子级的抽取式摘要方法能够实现一个较好的摘要效果,但依然存在以下问题:
冗余性,抽取出的句子存在冗余。
不必要性,抽取出的句子包含了一些不关键的信息。
存在抽取出的句子之间衔接生硬,不够自然。
现有工作通常使用tri-block后处理策略,即跳过和已选择句子存在tri-gram重叠的句子来减少冗余。还有一些工作在抽取的摘要基础上结合生成式摘要方法进行改写和优化,减少不相关的信息,同时提升衔接流畅度。本期介绍的两篇工作从设计一个比句子更细粒度的抽取单元出发,希望通过细粒度的抽取单元,分割出整句中的关键信息和不关键信息,避开冗余的和不必要的内容来解决前两点问题。
At Which Level Should We Extract An Empirical Analysis on Extractive Document Summarization
腾讯的Qingyu Zhou等人发表于COLING 2020会议上的一篇文章,论文主要针对抽取整句摘要方法存在的冗余性和不必要性问题,提出一种以子句作为抽取单元的抽取式摘要方法。本文的主要贡献包括两点:(1)提出了一种子句作为抽取单元的设置方式,介于短语和整句之间。(2)设计了基于BERT的子句摘要抽取模型,性能相比抽取整句有所提升。
子句的定义
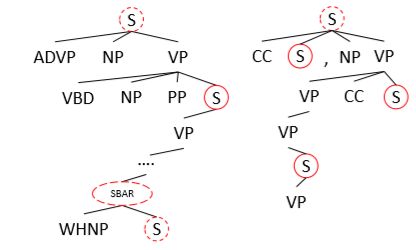
图 1 PTB句法成分解析树
本文通过Penn Treebank(PTB)[1]方法对句子进行句法成分分析,对每一个从句节点S和SBAR都视为子句单元。为了保留更完整的语义信息,如果一个从句节点被包括在更高层的从句节点中,则选择最高层的子句节点(除去根节点)作为抽取的子句单元。例如图1中,红色实线圈中的从句节点是最终选定的子句单元,如果一个句子解析后不存在从句节点,则直接选用整句作为抽取单元。
模型概述
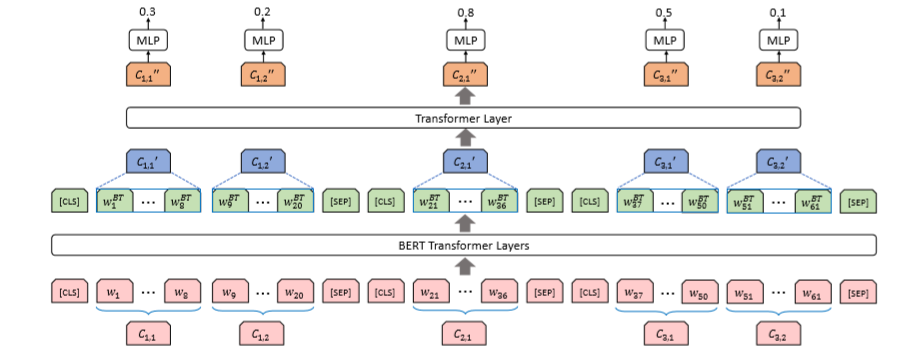
图2 基于BERT的子句抽取模型SSE(Sub-Sentential Extraction )
抽取模型参考了BERTSUM[2],这里对子句范围内的token做平均池化得到子句单元的表示,收集到所有子句单元的表示后再经过一层Transformer层混合上下句之间的信息,经过一层全连接层进行二分类预测当前子句单元是需要抽取。训练时学习每个子句是否需要抽取,预测时选择分数最高的top-N个子句拼接后输出。
实验评价
实验数据集使用经典的文本摘要数据集CNN/DailyMail。
表1 CNN/DM数据集中对参考摘要,句子级抽取的标准摘要,子句级抽取的标准摘要的统计
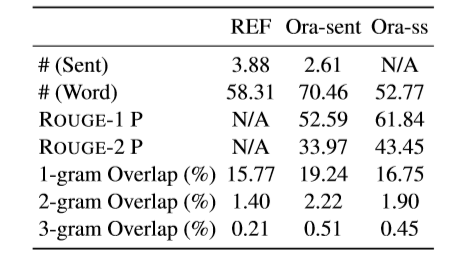
表1中Ora表示抽取式摘要方法中对目标抽取单元的Oracle构造方法,一般以贪心思想依次选择ROUGE增量分数最高的抽取单元加入,选择N个或没有可使ROUGE分数增加的选择时停止。可以看到,以子句作为抽取单元,Ora-ss抽取方法的ROUGE P分数更高,说明以子句为抽取单元能够避免抽取到不必要信息。从n-gram Overlap指标可以看出,Ora-ss抽取的内容重复度更低,冗余性相对抽取整句Ora-sent方法更低。
表2 CNN/DM测试集上的ROUGE F1评测结果
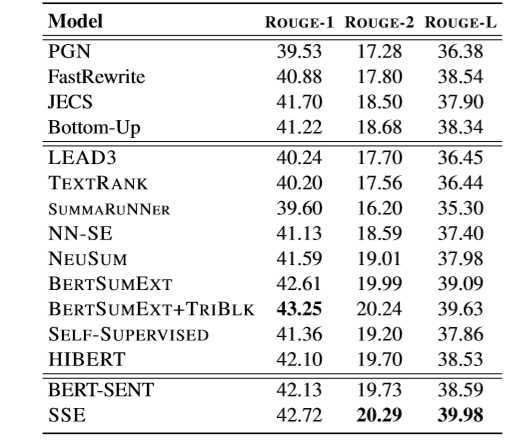
实验结果如表2所示,SSE模型不依赖后处理策略,在ROUGE-2和ROUGE-L上都超越了基线方法,且对比BERT-SENT(作者复现的BERTSUMEXT)提升显著。
表3 人工评估结果
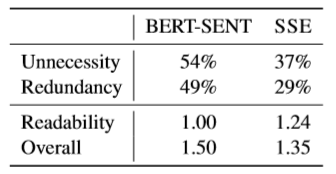
人工评估结果如表3,随机采样了50条样本,经过人工打分对比两个模型之间的优劣,各指标均是越低表示模型表现越优秀。可以看到SSE模型牺牲了一定的可读性,带来了整体上性能的提升,减少了冗余性和不必要性。
结论
以句法成分解析树中从句节点作为抽取式摘要的抽取单元,能够有效降低抽取摘要的冗余性和不必要性,牺牲一定的可读性,提升整体摘要性能,可读性受句法解析器准确率,以及子句片段自身相对于整个句子的不完备性影响,但整体上SSE达到相比抽取句子更优的性能。
Fact-level Extractive Summarization with Hierarchical Graph Mask on BERT
浙江大学Hanlu Wu等人在COLING 2020会议上发表的一篇文章,本文主要贡献包括两点:(1)基于依存分析方法设计了一种子句单元,命名为事实(Fact)。(2)设计了层次化的事实抽取摘要模型,通过改变注意力Mask对BERT直接引入了结构化信息。
事实的定义

图3 依存分析树中对整句拆分出事实片段的例子
本文提出了一种经验性的事实拆分算法,流程如下:
用依存分析方法(Stanford CoreNLP)对候选句子进行解析,每个句子用标点符号、连接词和从句的节点进行拆分,包括PU(标点), CC(连词), IP(从句)。
为了获得完整的语义单元,我们对一些特殊的关系连边两端的子句进行合并,包括acl:relcl,advcl(状语从句修饰词),appos(同位词),ccomp(从句补充)。
判断conj(连接关系)连接的2个元素是从句还是词语,如果2个元素距离低于一个阈值,则视为连接2个词语进行合并,否则视为2个子句。
预先定义了一个最小事实长度和最大事实长度,在执行上述合并过程中,如果某个子句长度超过最大长度,则视为独立的子句,不参与合并。一切合并操作执行完成后,若存在小于最小长度的子句,和前置的子句进行合并,最后所有的子句作为事实。
表4 CNN/DM数据训练集原文切分结果的统计

表4统计了CNN/DM数据中训练集的文章按句子切分和按事实切分后的数量和长度,平均1个句子包含1.6个事实,存在一部分句子独立作为单个事实,其他情况下通常一个句子被拆分为2到3个事实。
模型概述
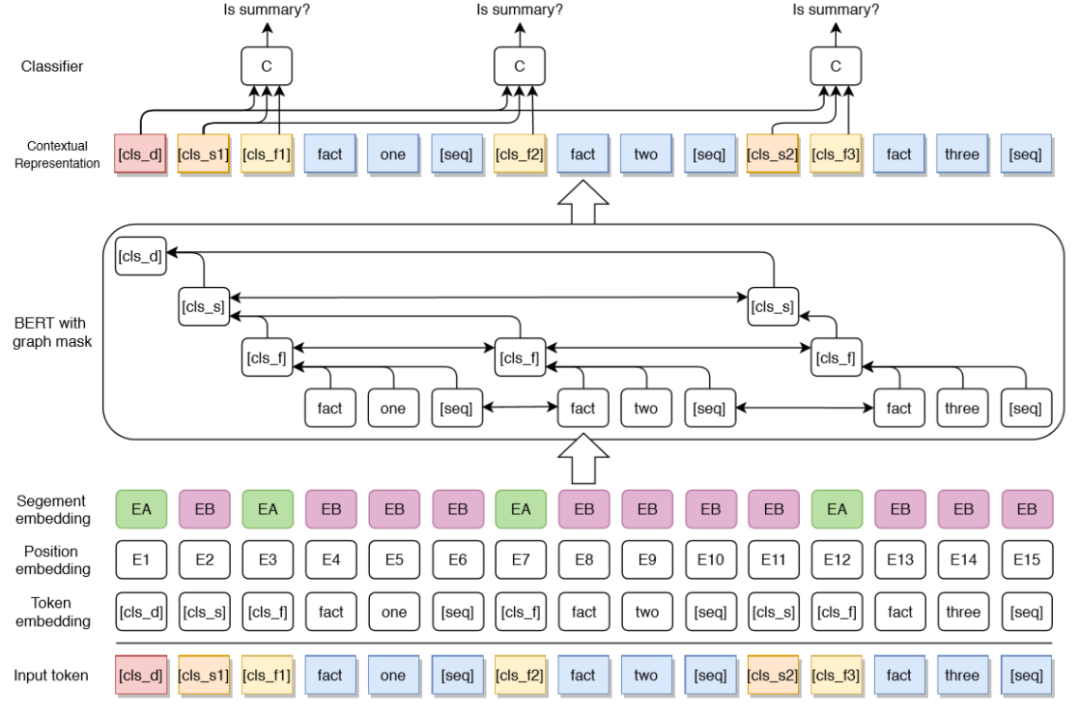
图4 层次化的事实级摘要抽取模型框架
模型如图4所示,在BERT的注意力层加入了一个Mask矩阵来加入层次化的结构信息,主要构造了2种连边:
同粒度下当前token和其他token之间的双向连边,图4中同色token之间都存在双向连边。
细粒度token指向粗粒度token的单向连边,例如图4中蓝色token指向自己所在事实token [cls_f]的连边,以及事实指向句子,句子指向文档的连边。
在输出层用全连接来对每个事实做分类,结合了文档的表示和所在句子的表示:
||表示连接,在输出时使用文档和对应句子的表示一同判断当前事实是否抽取。
训练时只学习事实的loss,预测时预测top-4的事实,加上tri-block去冗余策略。
实验评价
本文实验数据采用CNN/DM数据集。
表5 CNN/DM测试集上不同粒度的Oracle摘要对比
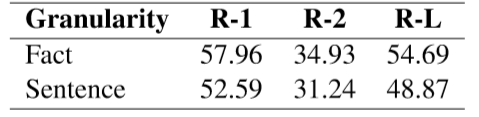
首先展示了基于事实用Oracle方法抽取摘要的效果,如表5所示,基于事实的Oracle方法提高了抽取方法的理论上界,能够生产更精确的抽取标签。
表6 CNN/DM测试集评测结果
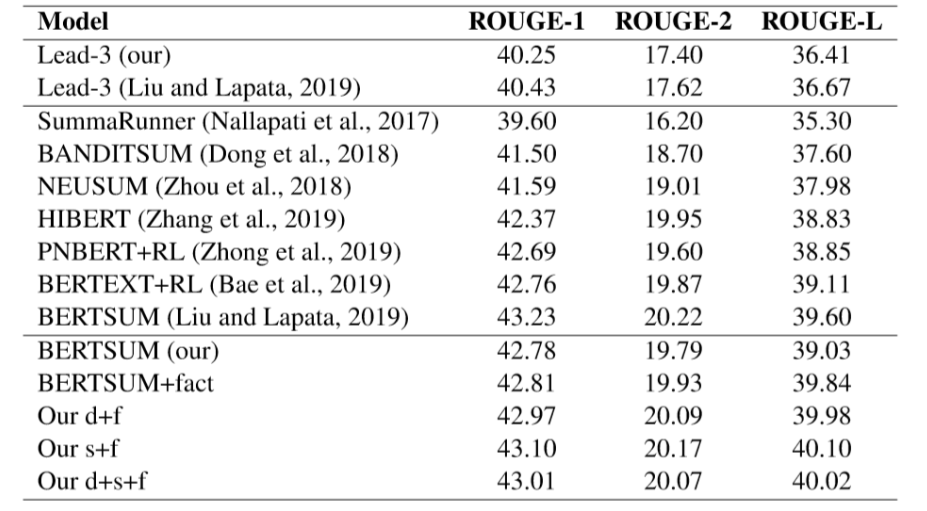
表6显示加入事实后,相对于作者复现的BERTSUM都有一定的提升,其中结合句子级的表示效果最佳,而额外使用文档级的信息没有带来提升,说明句子级的信息能够有助于判断句子内的事实是否应该抽取,而全文的文档级信息过于粗粒度,对判断事实是否抽取没有帮助。
表7 在CNN/DM测试集上的消融实验结果
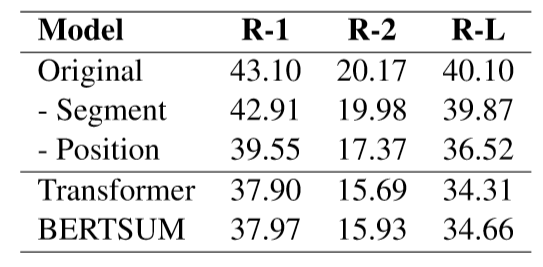
消融实验中对比了减去片段编码和位置编码的模型结果,表7下半部分是两种基线方法去除位置编码的结果,可以看出本文的方法去除位置信息后效果下降相对较小,说明层次化的结构信息有助于更好地帮助模型理解语义信息而不会过度依赖位置信息。
总结
两篇工作都是以设计粒度介于词和句子之间的抽取单元为主要思想,对比来看,第一篇的子句抽取单元粒度更细,有着更高的理论上界,但存在一些可读性上的问题。第二篇定义的事实作为抽取单元,在划分事实的算法中加入经验性的处理,保证了事实拆分的准确度和语义完整度。从模型优化上来看,第二篇提供了一种从修改掩码角度来对预训练模型引入结构化信息的思路,但实验中个人认为缺少了对应的消融验证实验,应当对比结构化掩码和全连接掩码的实验结果。
抽取式摘要是文本摘要中的一类重要方法,除了本期两篇工作关注的冗余性问题和不必要性问题,还存在例如抽取句子之间语义不连贯,衔接生硬等问题,以及如何对抽取式摘要进行准确评价也是值得探究的一个问题。在实际应用中设计方法时我们更应该关注问题本身,使得方法具有更好地满足真实需要。
原文标题:【摘要抽取】抽取式摘要最新研究进展
文章出处:【微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
责任编辑:haq
-
信息抽取
+关注
关注
0文章
6浏览量
6623
原文标题:【摘要抽取】抽取式摘要最新研究进展
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
128Gbps×2 满血双盘位:PCIe 5.0 x8 转双E1.S NVMe 硬盘抽取盒

PCIe 5.0 E1.S硬盘盒重磅上市!可抽取式托盘+主动散热,免开箱秒换SSD

AD8386:高性能10位12通道输出抽取式LCD驱动器的全方位解析
【概念产品CP156】服务器/PC扩容神器:单托盘双U.2/U.3 NVMe硬盘抽取盒,完美兼容3.5寸软驱位

C语言单元测试在嵌入式软件开发中的作用及专业工具的应用
高效部署磁盘阵列:选对硬盘抽取盒,省心又强力

创新企业级NVMe存储拓展方案 艾西达克前置M.2硬盘抽取盒测评

多块 M.2 硬盘拆到崩溃?M.2 硬盘抽取盒才是救星!

边聊安全 | 软件单元测试的设计方法

工业相机数据爆炸?ICY DOCK硬盘抽取盒极速存 + 0宕机!

突破影音录播设备存储瓶颈!ICY DOCK 高密度硬盘抽取盒提升制作效率

【ICY DOCK新品】4盘位2.5英寸U.2/U.3 NVMe SSD硬盘抽取盒

在ANSA中设置ABAQUS独立非线性分析步的方法

最新PCIe5.0 U.2硬盘抽取盒— ICY DOCK MB491V5K-B 开箱测评

【硬盘抽取盒民主实验】你的真话,决定产品命运!敢说就送!




评论