 关于三篇论文中自然语言研究进展与发展方向详解
关于三篇论文中自然语言研究进展与发展方向详解

引言
自然语言理解(Natural Language Understanding,NLU)是希望机器像人一样,具备正常人的语言理解能力,是人机对话系统中重要的组成部分。NLU主要包括两大任务,分别是意图识别(Intent Detection)和槽填充(Slot Filling)。其中,意图识别就是判断用户的意图,是一个文本分类的问题;槽填充是识别句子中重要的语义成分,常建模成序列标注的任务。
本次分享EMNLP2020中的三篇和NLU相关的文章,介绍这个领域目前的研究进展和关注方向。
文章概览
SlotRefine: A Fast Non-Autoregressive Model for Joint Intent Detection and Slot Filling
论文提出了一个非自回归的意图识别和槽填充联合模型,该模型以Transformer为基本结构,使用两阶段迭代机制显著地提高了模型性能和模型速度。
论文地址:https://www.aclweb.org/anthology/2020.emnlp-main.152
Incremental Processing in the Age of Non-Incremental Encoders: An Empirical Assessment of Bidirectional Models for Incremental NLU
论文提出了三种适用于增量NLU任务的评价指标,探究了目前非增量编码器在增量系统中的模型性能。
论文地址:https://www.aclweb.org/anthology/2020.emnlp-main.26
End-to-End Slot Alignment and Recognition for Cross-Lingual NLU
论文提出了用于一种跨语言自然语言理解的端到端槽位标签对齐和识别模型,该模型运用注意力机制将目标语言文本表示和源语言的槽位标签软对齐,并且同时预测意图和槽标签。
论文地址:https://www.aclweb.org/anthology/2020.emnlp-main.410/
1论文细节

论文动机
以往的自然语言理解模型大多依赖于自回归的方法(例如,基于RNN的模型或seq2seq的架构)来捕捉话语中的语法结构,并且在槽填充任务中常使用条件随机场(CRF)模块来确保序列标签之间的合理性。然而本文作者发现,对于槽填充任务而言,从槽块之间建模依赖关系就足以满足任务需要,而使用自回归的方法对整个序列的依赖关系建模会导致冗余计算和高延迟。因此作者使用非自回归的方法来建模意图识别和槽填充两个任务,从而消除非必要的时间依赖,并且采用两阶段迭代机制来处理由于条件独立性导致的槽标签之间的不合理问题。
模型
模型主要包括两个方面,分别是非自回归的联合模型以及两阶段改善机制。
非自回归的联合模型
模型使用了《Attention is all you need》(Vaswani等人, 2017)这篇论文中提出的Transformer模型的encoder部分作为本文模型编码层的主要结构。与原始Transformer不同的是,作者将绝对位置编码改为相对位置表示来建模文本序列信息。
对于每个输入的文本序列,都会在初始位置添加一个特殊的符号“CLS”来表示句子信息。文本序列的输入为,经过Multi-Head Self Attention编码后得到输出向量为 。其中,向量将用于意图分类,将和每个时刻的拼接用于对应的槽位预测。意图识别和槽填充的计算公式如下:
联合模型的任务目标是通过优化交叉熵损失函数来最大化条件概率分布:
与自回归模型不同的是,这个模型中每个槽位预测可以并行优化,由此提高了模型速度。
两阶段改善机制
由于槽位标签之间的条件独立性,上述非自回归联合模型难以捕获每个槽位块之间的依赖关系,从而导致一些槽位标签不合理现象。如下图所示,根据BIO标签规则,“I-song”并不能跟在“B-singer”后面。
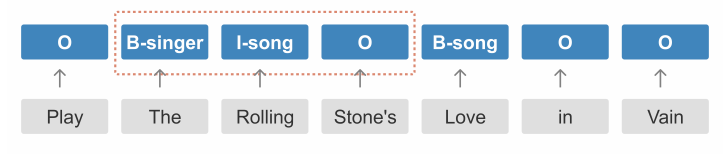
因此,作者提出两阶段的迭代机制,使用两次槽位预测的方法来改善这个问题。模型的输入除了文本信息之外,还有槽位标签信息,初始化的槽位标签均为“O”。在第一阶段,模型的目标是预测每个槽块的起始标签“B-tags”,在第二阶段,预测的“B-tags”将作为相应槽位标签的输入,由此,模型可以进一步预测出“B-tags”后面对应的标签。两阶段的改善机制可以看作是自回归与非自回归之间的权衡,其中完整的马尔可夫过程可以表示为:
其中,是第一阶段的槽标签预测结果。
实验
实验使用的数据集是NLU领域两个经典的公开数据集:ATIS(Tur等人,2010)和Snips(Coucke等人,2018)。作者将本文模型与六种意图识别和槽填充联合模型进行了比较。结果如下:
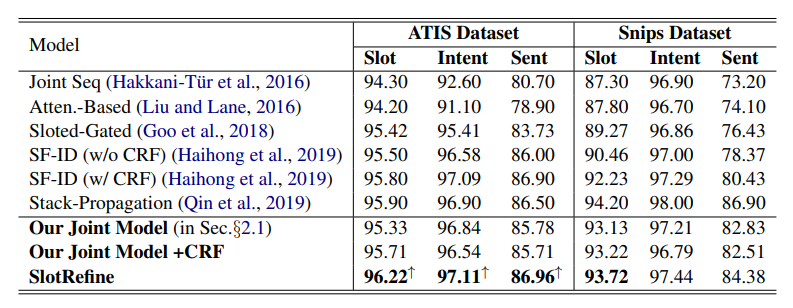
由上表可知,本文模型SlotRefine在ATIS数据集上取得了最佳效果,在槽填充F1值、意图识别准确率和句子层面准确率三个指标上均超过了现有模型。在Snips数据集上,模型效果没有Stack-Propagation好。从消融实验结果看到,在非自回归联合模型上加入CRF层会有效提高槽填充任务的性能,但会降低意图识别准确率和句子层面准确率,而本文提出的两阶段改善机制则可以显著提高模型效果。
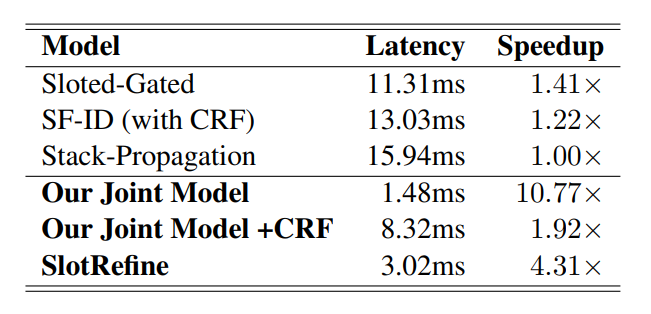
作者还比较了模型速度上的改进效果,由上表可知,在ATIS数据集上,与现有的最优模型Stack-Propagation相比,本文提出的模型SlotRefine的速度提高了4.31倍。由于每个槽标签均可以并行计算,因此模型的推理延迟可以显著减少。

2论文动机
增量学习是指模型能够不断地处理现实世界中连续的信息流,在吸收新知识的同时保留甚至整合、优化旧知识的能力。在NLP领域,增量处理方式在认知上更加合理,并且在工程层面,一些实时应用(如自然语言理解、对话状态追踪、自然语言生成、语音合成和语音识别)要求在一定时间步长的部分输入的基础上必须提供部分输出。虽然人类使用增量的方式处理语言,但目前在NLP中效果最好的语言编码器(如BiLSTM和Transformer)并不是这样的。BiLSTM和Transformer均假定编码的整个序列是完全可用的,可以向前或向后处理(BiLSTM),也可以作为一个整体处理(Transformer)。本文主要想探究这些非增量模型在增量系统下的效果,作者在不同的NLU数据集上实验了五个非增量模型,并使用三个增量评估指标比较它们的性能。
增量系统评价指标
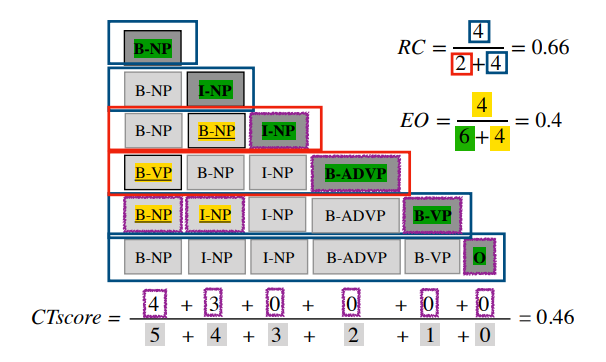
增量系统可以通过添加、撤销和替换输出部分来编辑输出。一个效果良好的增量系统应当能够尽快产生准确的输出,并且撤销和替换要尽可能少。由此,本文提出三个评价指标:编辑开销、校正时间和相对正确性。
编辑开销(Edit Overhead,EO):不必要的编辑比例,范围在0-1之间,越接近于0,说明编辑越少。
校正时间(Correction Time,CT):系统提交某一输出内容的最终决策之前所花的时间,范围在0-1之间,越接近于0,说明系统越快做出最终决策。
相对正确性(Relative Correctness,RC):输出相对于非增量输出时正确的比例,范围在0-1之间,越接近于1表示系统的输出大部分时刻下都是非增量输出的正确前缀。
作者以词性标注任务为例展示了三个评价指标的计算过程。如下图所示:
模型
作者一共探究了五种非增量模型在增量系统中的表现,分别是:(a) LSTM模型;(b)BiLSTM模型;(c)LSTM+CRF;(d)BiLSTM+CRF;(e)BERT。其中,(a)、(b)、(e)模型同时用于序列标注和文本分类任务,(c)和(d)模型只用于序列标注任务。
本文探索了三种策略的效果,分别是截断训练、延迟输出和语言:
截断训练(truncated training):去掉训练集中每个句子的结尾来修改训练机制。
延迟输出(delayed output):允许模型在输出当前时刻单词的标签之前观察后续1-2个时刻的单词。
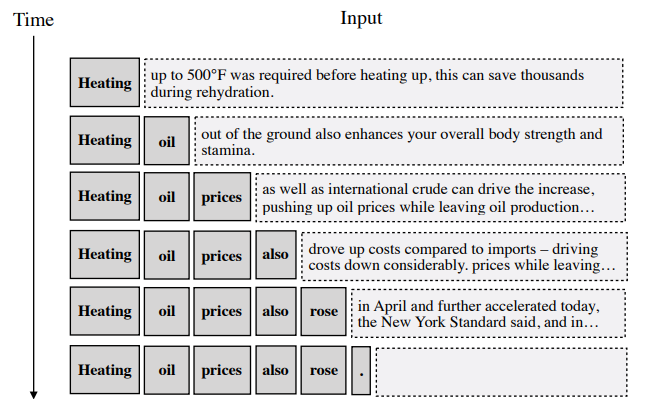
语言(prophecies):使用GPT-2语言模型将每个时刻的输入前缀作为左上下文,并由此生成一个持续到句子末尾的文本,创建一个假设的完整上下文,以满足模型的非增量特性的需要。如下图所示:
实验
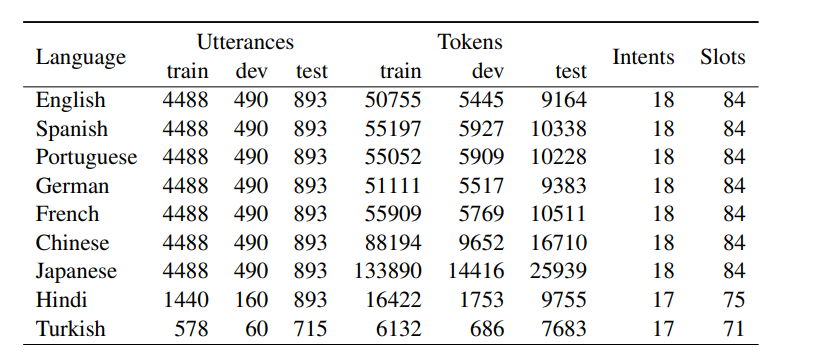
作者一共在十个英文数据集上进行了实验,六个数据集用于序列标注任务:组块分析(Chunk)、槽填充(Slot Filling (ATIS)和Slot Filling (SNIPS))、命名实体识别(NER)、词性标注(Part-of-Speech Tagging) 、语义角色标注(Semantic Role Labeling);四个数据集用于文本分类任务:意图识别(Intent (ATIS)和Intent (SNIPS))、情感分析(Positive/Negative和Pros/Cons)。其中,Chunking、NER、SRL和Slot Filling均使用BIO标签体系并且使用F1值进行评估,其他的任务使用准确率评价。
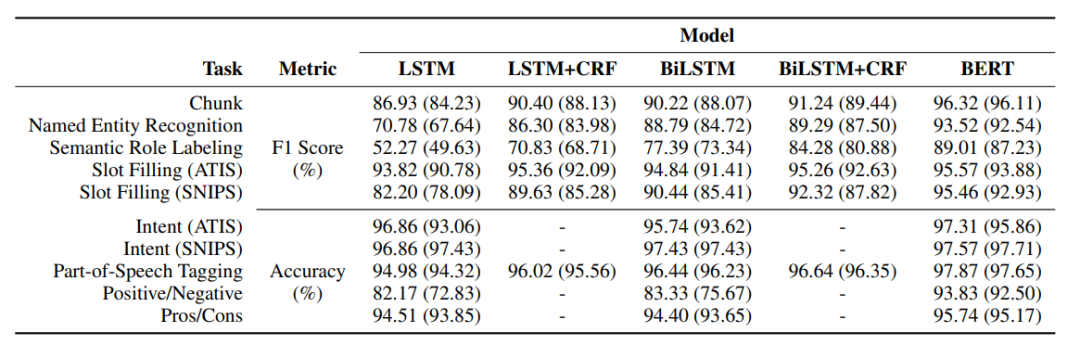
五种模型在上述数据集上的实验结果如下所示,括号里代表使用了截断训练的结果。从中可知,大部分情况下BiLSTM比LSTM效果好;BERT可以提升所有任务性能;截断训练后模型性能都有所下降,但BERT仍优于其他所有模型。整体来说,目前的非增量编码器可以适应在增量系统下使用,其性能产生不会有太大影响。
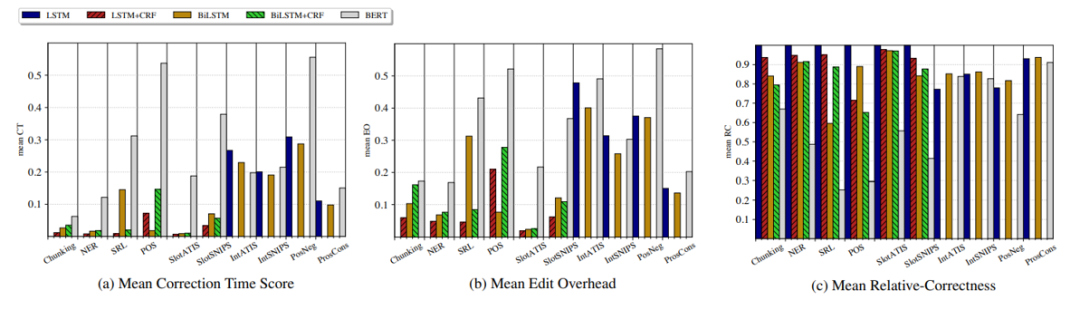
模型在三个增量系统的评价指标上的表现结果如下所示。从中可以发现,除BERT外,模型在序列标注任务的编辑开销和校正时间均较低;在文本分类中,由于往往需要捕捉全局信息,编辑开销和校正时间均较高;对于相对正确性这个指标,在序列标注任务中BERT比其他模型效果都差,在文本分类任务中性能差不多。
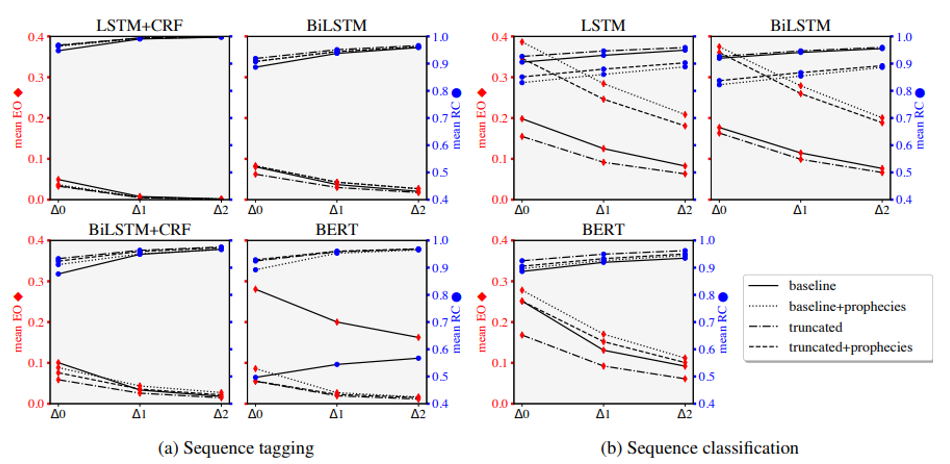
作者还探究了不同策略的效果,从图中可知,截断训练可以有效减少编辑开销,提高相对正确性;预言对于文本分类任务有负面作用,但对于一些序列标注任务可能有效。BERT模型在增量评价指标上的缺陷可以通过这些策略得到一定缓解,从而使其在增量系统下的模型效果与其他模型一样好。
3

论文动机
NLU可以将话语解析成特定的语义框架,以识别用户的需求。虽然目前神经网络模型在意图检测和槽填充方面取得了很高的准确性,在两个公开的英文数据集上模型的效果已经达到95%以上,但如果使用一种新的语言训练这样的模型仍需要大量的数据和人工标注工作。因此考虑通过跨语言学习将模型从高资源语言迁移到低资源语言,从而减少数据收集和标注的工作量。
跨语言迁移学习主要有两种方式:一种是使用多语言模型来实现语言的迁移,例如multilingual BERT;另一种是通过机器翻译的方式先统一语言类型,虽然它在跨语言文本分类上取得了很好的效果,但在序列标注任务上存在一些挑战,源语言的标签需要映射到目标语言中,而如果两个语言差别较大,则较难找到良好的映射关系。
目前跨语言NLU任务中存在一些挑战:(1)可以使用的数据集(Multilingual ATIS)仅支持三种语言,语言类型不足;(2)现有的模型使用机器翻译和槽标签投影的方法将NLU系统扩展到新语言中,这种方法对标签投影错误很敏感。
因此,这篇文章发布了一个新的跨语言NLU数据库(MultiATIS++),探索了不同的跨语言迁移方法的效果,并且提出了一种新的端到端模型,该模型可以对目标语言槽标签进行联合对齐和预测,以实现跨语言迁移。
数据集
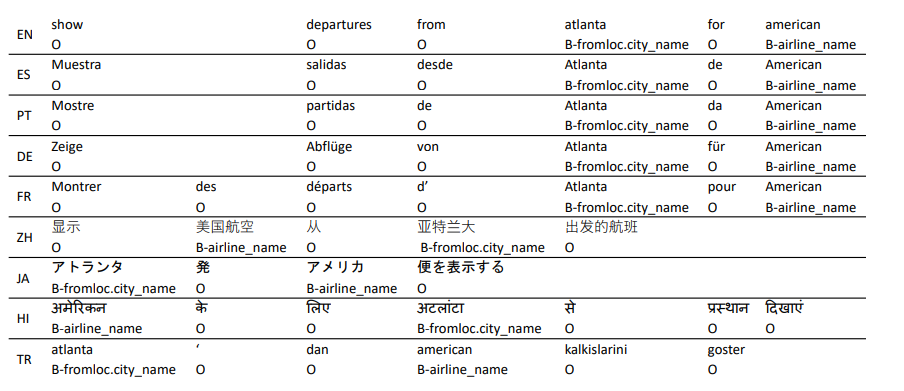
MultiATIS++数据集在Multilingual ATIS数据集基础上新增了六种语言,共覆盖九种语言,并对每种语言人工打上槽位标签(使用BIO标签体系)。数据集样例和数据集的描述特征如下所示:
模型
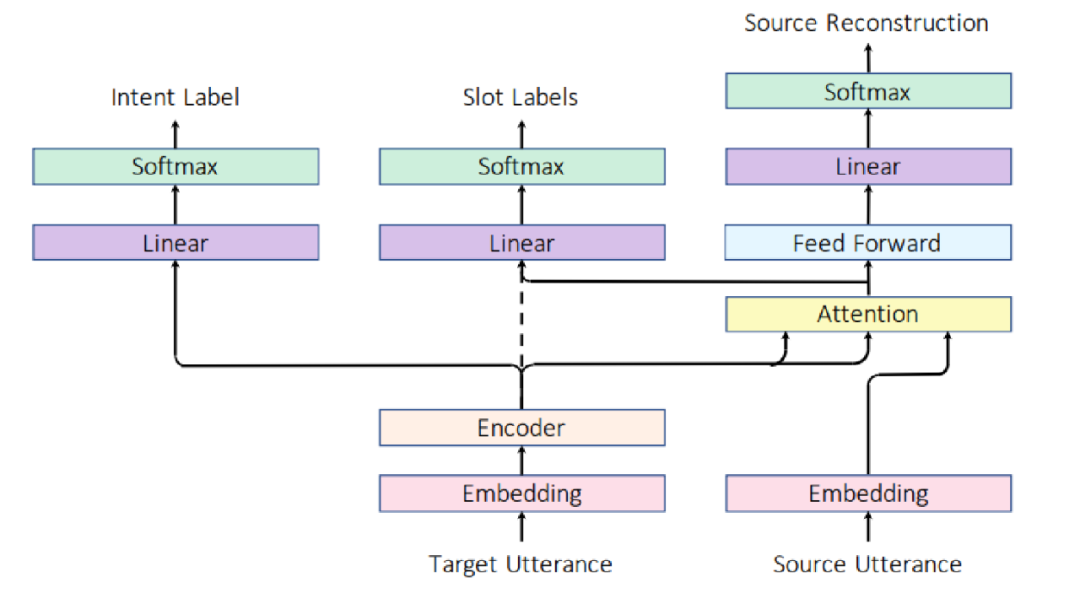
上图为作者提出的端到端槽对齐和识别模型,使用Attention机制将目标语言表示与源语言槽标签进行软对齐,模型直接将编码器模块连接到意图和槽分类层,对目标语言同时预测意图和槽标签。该模型使用额外的Attention层来同时完成槽标签对齐和识别任务,不需要额外的槽标签投影过程。
记为源语言文本序列,为目标语言文本序列,源语言文本经过Embedding之后得到向量表示,目标语言经过Embedding和Encoder后得到上下文表示,其中是额外添加的符号,用于表示目标语言句子表示。意图识别任务的公式如下:
对于槽填充任务,先计算目标语言和源语言的注意力向量,然后再进行目标语言的槽位预测,其公式如下:
此外,作者还提出了一个重构模块来提高目标语言和源语言的对齐效果:
意图识别、槽填充和重构模块的损失函数如下所示,模型的损失函数为三者相加:
实验结果
Multilingual NLU
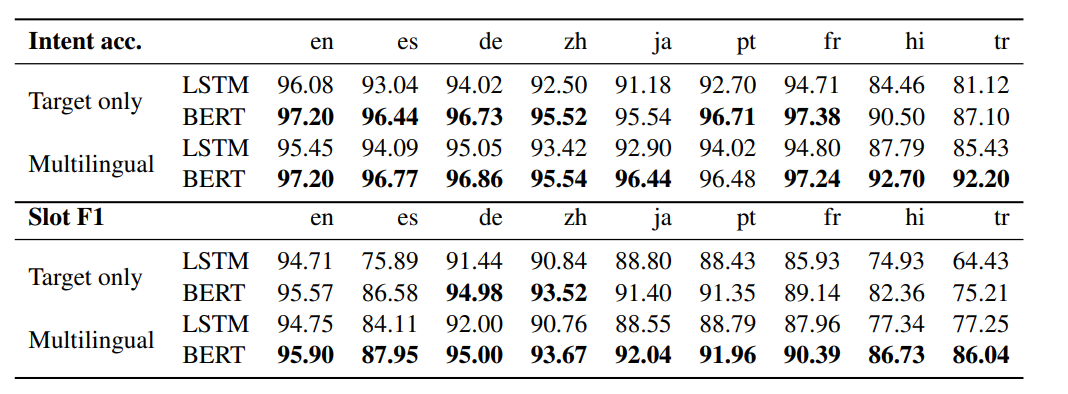
作者使用multilingual BERT预训练模型作为encoder,并比较了仅使用目标语言进行NLU和使用全部的语言进行NLU时监督训练的效果。如图所示,BERT相比于LSTM在不同语言上均能显著提高模型性能,并且多语言监督训练能进一步提高模型性能。
Cross-Lingual Transfer
作者比较了不同的跨语言迁移学习方法,其中源语言是英语,目标语言共有八种。实验结果和模型速度如下所示:
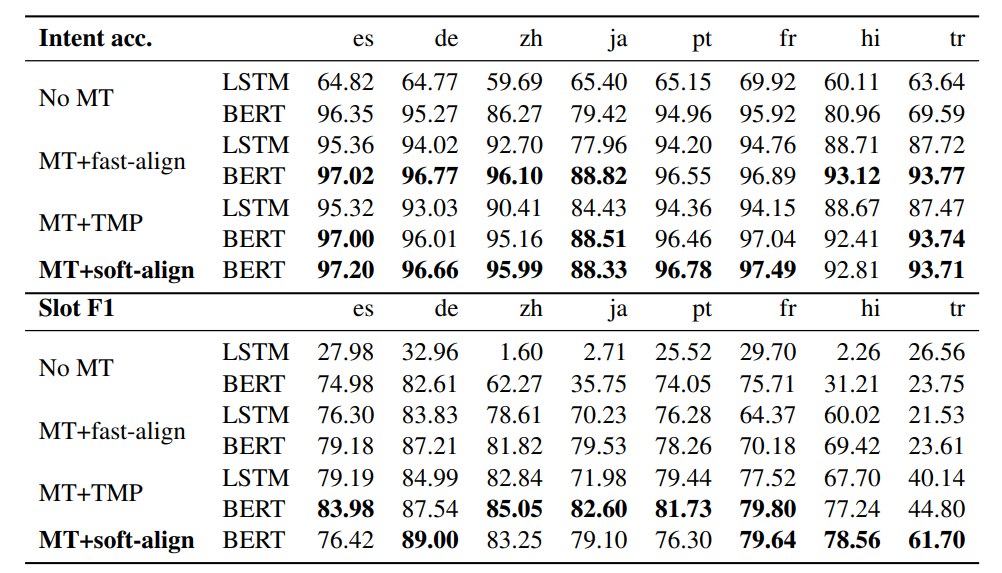
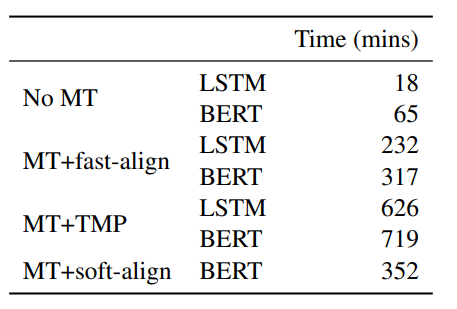
MT+soft-align是本文提出的模型,在八个目标语言数据集中,有五个语言本文模型相比于MT+fast-align的效果更好,并且在意图识别和槽填充任务中本文模型的鲁棒性更强。本文模型的速度明显优于MT+TMP模型,在模型性能上,意图识别任务中,本文模型在六个语言上表现更好,槽填充任务中,本文模型在四个语言上表现更佳。综合模型性能和模型速度,端到端的槽标签软对齐和识别模型在跨语言NLU任务上具有一定优势。
参考文献
[1] Vaswani A , Shazeer N , Parmar N , et al. Attention Is All You Need[J]。 arXiv, 2017.
[2] Tur G , Hakkani-Tur D , Heck L 。 What is left to be understood in ATIS?[C]// Spoken Language Technology Workshop (SLT), 2010 IEEE. IEEE, 2011.
[3] Coucke A , Saade A , Ball A , et al. Snips Voice Platform: an embedded Spoken Language Understanding system for private-by-design voice interfaces. 2018.
编辑:lyn
-
识别模型
+关注
关注
0文章
5浏览量
6857 -
自然语言
+关注
关注
1文章
292浏览量
13917
原文标题:【论文分享】EMNLP 2020 自然语言理解
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
云知声论文入选自然语言处理顶会EMNLP 2025

多光谱图像颜色特征用于茶叶分类的研究进展
【HZ-T536开发板免费体验】5- 无需死记 Linux 命令!用 CangjieMagic 在 HZ-T536 开发板上搭建 MCP 服务器,自然语言轻松控板
思必驰与上海交大联合实验室研究成果入选两大顶级会议

理想汽车八篇论文入选ICCV 2025
后摩智能四篇论文入选三大国际顶会
云知声四篇论文入选自然语言处理顶会ACL 2025

【「零基础开发AI Agent」阅读体验】总体预览及入门篇
自然语言提示原型在英特尔Vision大会上首次亮相
美报告:中国芯片研究论文全球领先
后摩智能5篇论文入选国际顶会

二极管泵浦高能激光的研究进展(1)
石墨烯铅蓄电池研究进展、优势、挑战及未来方向
中山大学:在柔性触觉传感电子皮肤研究进展





 工商网监
工商网监
评论