 TensorFlow模型优化:模型量化
TensorFlow模型优化:模型量化

1. 模型量化需求
为了满足各种 AI 应用对检测精度的要求,深度神经网络结构的宽度、层数、深度以及各类参数等数量急速上升,导致深度学习模型占用了更大的存储空间,需要更长的推理时延,不利于工业化部署;目前的模型都运行在 CPU,GPU,FPGA,ASIC 等四类芯片上,芯片的算力有限;对于边缘设备上的芯片而言,在存储、内存、功耗及时延性方面有许多限制,推理效率尤其重要。
作为通用的深度学习优化的手段之一,模型量化将深度学习模型量化为更小的定点模型和更快的推理速度,而且几乎不会有精度损失,其适用于绝大多数模型和使用场景。此外,模型量化解锁了定点硬件(Fixed-point hardware) 和下一代硬件加速器的处理能力,能够实现相同时延的网络模型推理功能,硬件价格只有原来的几十分之一,尤其是 FPGA,用硬件电路去实现网络推理功能,时延是各类芯片中最低的。
TensorFlow 模型优化工具包是一套能够优化机器学习模型以便于部署和执行的工具。该工具包用途很多,其中包括支持用于以下方面的技术:
通过模型量化等方式降低云和边缘设备(例如移动设备和 IoT 设备)的延迟时间和推断成本。将优化后的模型部署到边缘设备,这些设备在处理、内存、耗电量、网络连接和模型存储空间方面存在限制。在现有硬件或新的专用加速器上执行模型并进行优化。
根据您的任务选择模型和优化工具:
利用现成模型提高性能在很多情况下,预先优化的模型可以提高应用的效率。
2. 模型量化过程
大家都知道模型是有权重 (w) 和偏置 (b) 组成,其中 w,b 都是以 float32 存储的,float32 在计算机中存储时占 32bit,int8 在计算机中存储时占 8bit;模型量化就是用 int8 等更少位数的数据类型来代替 float32 表示模型的权重 (w) 和偏置 (b) 的过程,从而达到减少模型尺寸大小、减少模型内存消耗及加快模型推理速度等目标。
模型量化以损失推理精度为代价,将网络中连续取值或离散取值的浮点型参数(权重 w 和输入 x)线性映射为定点近似 (int8/uint8) 的离散值,取代原有的 float32 格式数据,同时保持输入输出为浮点型,从而达到减少模型尺寸大小、减少模型内存消耗及加快模型推理速度等目标。定点量化近似表示卷积和反卷积如下图 所示,左边是原始权重 float32 分布,右边是原始权重 float32 经过量化后又反量化后权重分布。
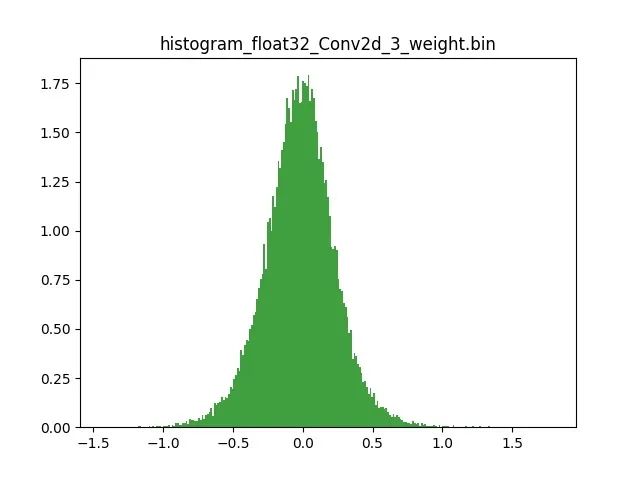
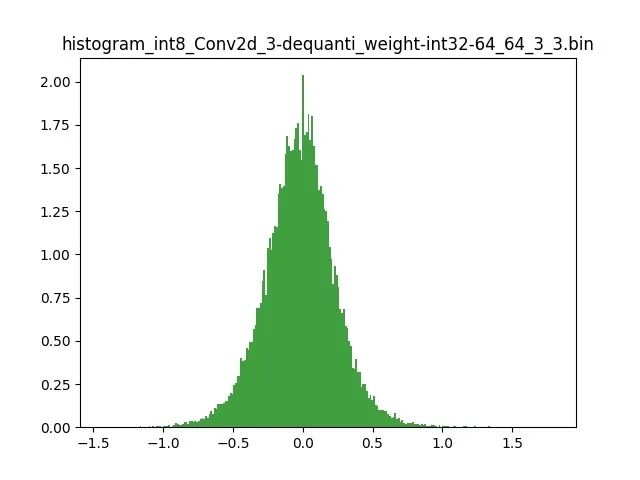
图 2.1 Int8 量化近似表示卷积
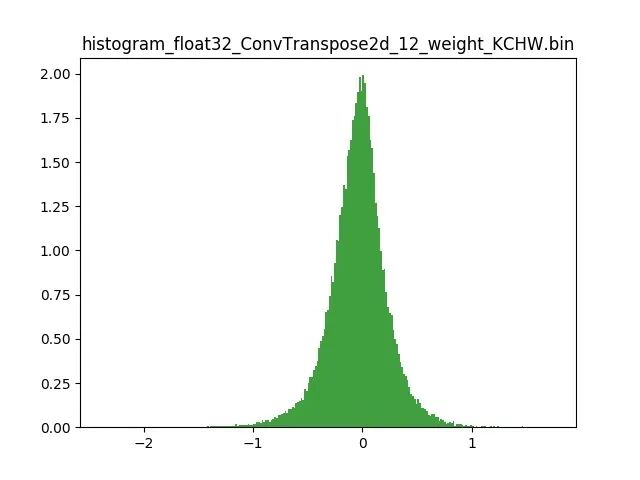
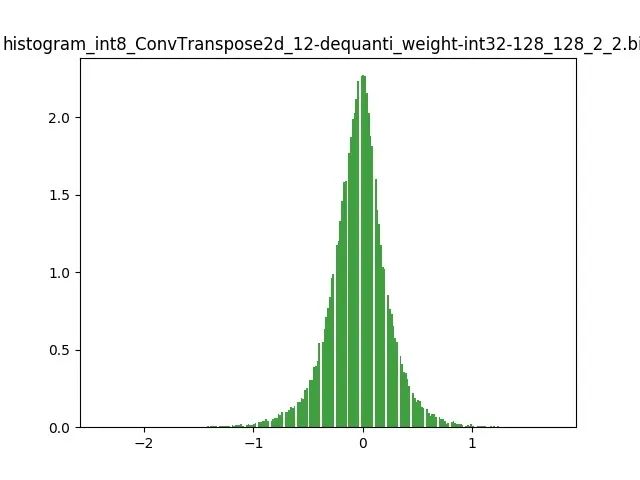
图 2.2 Int8 量化近似表示反卷积
3. 模型量化好处
减小模型尺寸,如 8 位整型量化可减少 75% 的模型大小;
减少存储空间,在边缘侧存储空间不足时更具有意义;
减少内存耗用,更小的模型大小意味着不需要更多的内存;
加快推理速度,访问一次 32 位浮点型可以访问四次 int8 整型,整型运算比浮点型运算更快;CPU 用 int8 计算的速度更快
减少设备功耗,内存耗用少了推理速度快了自然减少了设备功耗;
支持微处理器,有些微处理器属于 8 位的,低功耗运行浮点运算速度慢,需要进行 8bit 量化。
某些硬件加速器如 DSP/NPU 只支持 int8
4. 模型量化原理
模型前向推理过程中所有的计算都可以简化为 x= w*x +b; x 是输入,也叫作 FeatureMap,w 是权重,b 是偏置;实际过程中 b 对模型的推理结果影响不大,一般丢弃。原本 w,x 是 float32,现在使用 int8 来表示为 qw,qx;模型量化的原理就是定点 (qw qx) 与浮点 (w,x),建立了一种有效的数据映射关系.。不仅仅量化权重 W ,输入 X 也要量化;详解如下:
R 表示真实的浮点值(w 或者 x),
责任编辑:lq
-
模型
+关注
关注
1文章
3811浏览量
52257 -
机器学习
+关注
关注
67文章
8561浏览量
137208 -
深度学习
+关注
关注
73文章
5604浏览量
124610
原文标题:社区分享 | TensorFlow 模型优化:模型量化
文章出处:【微信号:tensorflowers,微信公众号:Tensorflowers】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
后量化模型在 iMX93 NPU 上运行,但输出不正确怎么解决
在 NPU 上运行了 eIQ TensorFlow Lite 示例模型报错
AWQ/GPTQ量化模型加载与显存优化实战
微电网经济调度理论:成本最小化与效益最大化的优化模型


如何利用NPU与模型压缩技术优化边缘AI
如何精准驱动菜品识别模型--基于米尔瑞芯微RK3576边缘计算盒
西格电力储能容量配置优化模型与工具方法
在Ubuntu20.04系统中训练神经网络模型的一些经验
如何进行YOLO模型转换?
无法在NPU上推理OpenVINO™优化的 TinyLlama 模型怎么解决?
无法将Tensorflow Lite模型转换为OpenVINO™格式怎么处理?
使用 NPU 插件对量化的 Llama 3.1 8b 模型进行推理时出现“从 __Int64 转换为无符号 int 的错误”,怎么解决?
您的模型诊断专家MI:助力把好模型质量关




评论