 Imagination展示了多项基于其先进图形处理器和神经网络加速器IP的应用演示
Imagination展示了多项基于其先进图形处理器和神经网络加速器IP的应用演示

集成电路产业是国家战略性支柱产业,是国民经济和社会信息化的重要基础。当前我国集成电路产业发展正处于关键期,国家高度重视并出台一系列政策和措施予以大力支持。集成电路设计业作为整个产业的龙头和技术、产品创新的主要环节,在产业发展中承担着重要责任,而知识产权(IP)在其中则扮演着关键的角色。 12月10日-11日,“中国集成电路设计业2020年会”(ICCAD 2020)在重庆举行,这场集成电路产业的年终盛会也是业内企业和从业人员的一次大聚会。Imagination Technologies作为全球领先的半导体IP厂商也如约出席大会,并通过技术应用展示和主题演讲与业界同仁展开了深入的交流。
Imagination展示了多项基于其先进图形处理器(GPU)和神经网络加速器(NNA)IP的应用演示。例如,基于瑞萨R-Car H3芯片的GPU硬件虚拟化演示,该芯片采用了Imagination的PowerVR GX6650 GPU。通过硬件虚拟化功能,同一个GPU可以同时处理多个任务,并且通过物理隔离确保这些任务互不影响,实现了最高的安全性。
Imagination演示了基于先进IP的多项应用 另一项精彩演示是基于GPU和NNA的汽车环绕视图应用。GPU将摄像头图像拼接在一起推理出光照条件,利用环境光照渲染整个车身;同时,采集一定的图像用于神经网络分析,NNA会基于GoogLeNet SSD算法实现人的检测。 此外,Imagination还展示了领先的低功耗PowerVR光线追踪技术,以及利用不同的神经网络算法,基于NNA来实现语义分割、姿态检测、人脸检测、目标检测等应用。
Imagination的精彩演示吸引多位参观者驻足观看 在本次大会的“IP与IC设计”专题论坛上,Imagination解决方案高级技术经理郑凯发表了题为“SoC IP 助力智能计算实现性能、功耗、面积新突破”的演讲,全面介绍了Imagination新近发布的最新一代GPU和NNA产品。
Imagination解决方案高级技术经理郑凯发表演讲 郑凯表示,中国是全球最大的半导体市场,但85%的半导体器件依赖进口,如何尽快实现半导体产业的进口替代事关国家经济和安全。Imagination作为一家中资拥有的全球性半导体IP企业,致力于通过创新技术和高效服务为中国芯片厂商提供广泛支持,并已在移动、汽车、桌面、云计算、无人机等领域拥有大量合作伙伴。 “Imagination在10月和11月陆续发布了最新的IMG B系列多核GPU和IMG Series4多核NNA,在进一步丰富和强化我们产品线的同时,可以为客户提供更高的性能和渲染能力,以及更低的功耗、延迟和成本。”郑凯介绍道。
相比IMG A系列,B系列在功耗预算相同的情况下实现了30%的性能提升 IMG B系列GPU包括BXE、BXM、BXT、BXS四类产品,郑凯以旗舰款BXT为例介绍了B系列的特性。四核BXT可以提供6 TFLOPS的性能,每秒可处理192 Gigapixel(十亿像素),拥有24 TOPS的AI算力,同时可提供行业最高的性能密度。从手持设备到数据中心,BXT GPU可以为各类应用提供难以置信的高性能。
Imagination Tensor Tiling技术助力Series4 NNA降低了90%的带宽需求
IMG Series4 NNA凭借全新的多核架构实现了超高性能和超低延迟。例如,一个8核集群可以提供100 TOPS的算力,延迟在理想情况下也会减少为单核独立执行时的1/8。此外,Series4包含IP级别的安全功能且设计流程符合ISO 26262车规标准,使其成为先进驾驶辅助系统(ADAS)和自动驾驶等汽车应用的理想选择。
责任编辑:lq
-
集成电路
+关注
关注
5463文章
12667浏览量
375606 -
神经网络
+关注
关注
42文章
4840浏览量
108141 -
IP技术
+关注
关注
0文章
16浏览量
8458
原文标题:进口替代是关键 IMG先进IP技术助力中国集成电路业加快自主发展 |ICCAD 2020
文章出处:【微信号:Imgtec,微信公众号:Imagination Tech】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
探索MAX78002:低功耗卷积神经网络加速器的AI微控制器
神经网络的初步认识

工业级-专业液晶图形显示加速器RA8889ML3N简介+显示方案选型参考表
一些神经网络加速器的设计优化方案
CNN卷积神经网络设计原理及在MCU200T上仿真测试
NMSIS神经网络库使用介绍
SNN加速器内部神经元数据连接方式
CICC2033神经网络部署相关操作
液态神经网络(LNN):时间连续性与动态适应性的神经网络
神经网络的并行计算与加速技术
Andes晶心科技推出新一代深度学习加速器
Arm神经技术是业界首创在 Arm GPU 上增添专用神经加速器的技术,移动设备上实现PC级别的AI图形性能
MAX78000采用超低功耗卷积神经网络加速度计的人工智能微控制器技术手册
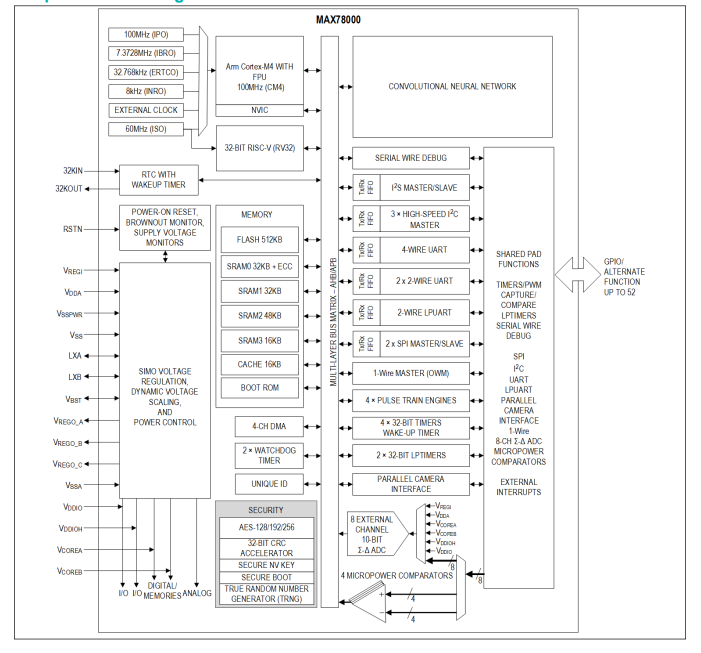
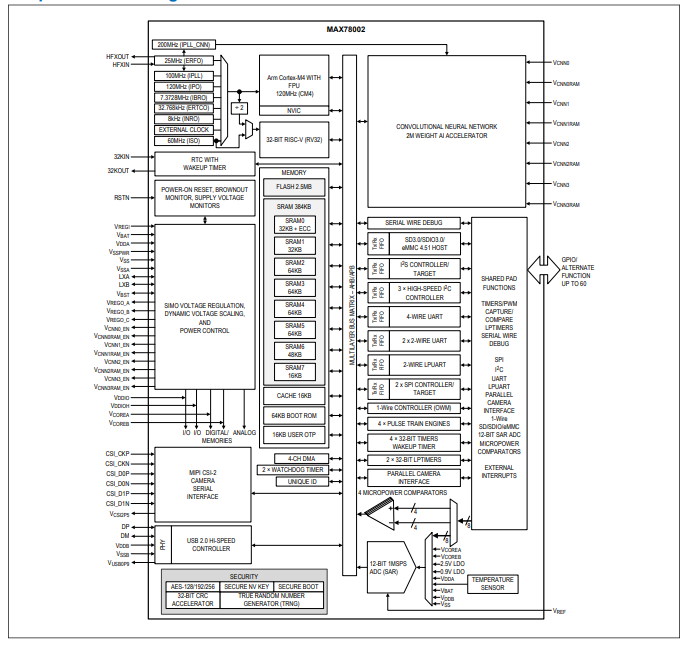
MAX78002带有低功耗卷积神经网络加速器的人工智能微控制器技术手册
TPU处理器的特性和工作原理



评论