 如何利用PCA和SVM建立一个人脸识别模型
如何利用PCA和SVM建立一个人脸识别模型

在本文中,我们将使用主成分分析和支持向量机来建立人脸识别模型。
首先,让我们了解PCA和SVM是什么:
主成分分析:主成分分析(PCA)是一种机器学习算法,广泛应用于探索性数据分析和建立预测模型,它通常用于降维,通过将每个数据点投影到前几个主成分上,以获得低维数据,同时尽可能保留数据的变化。
Matt Brems的文章全面深入地介绍了该算法。现在,让我们用更简单的术语来理解算法:假设我们现在正在收集数据,我们的数据集产生了多个变量、多个特征,所有这些都会在不同方面影响结果。我们可能会选择删除某些特征,但这意味着会丢失信息。因此我们开源使用另一种减少特征数量(减少数据维数)的方法,通过提取重要信息并删除不重要的信息来创建新的特征,这样,我们的信息就不会丢失,但起到减少特征的作用,而我们模型的过拟合几率也会减少。支持向量机支持向量机(SVM)是一种用于两组分类问题的有监督机器学习模型,在为每个类别提供一组带标签的训练数据后,他们能够对新的测试数据进行分类。
支持向量机基于最大化间隔的平面对数据进行分类,决策边界是直的。支持向量机是一种很好的图像分类算法,实验结果表明,支持向量机在经过3-4轮相关优化后,其搜索精度明显高于传统的查询优化方案,这对于图像分割来说也是如此,包括那些使用改进的支持向量机。Marco Peixeiro的文章解释了需要有一个最大间隔超平面来分类数据,开源帮助你更好地理解SVM!人脸识别人脸是由许多像素组成的高维数据。高维数据很难处理,因为不能用二维数据的散点图等简单技术进行可视化。我们要做的是利用PCA对数据的高维进行降维处理,然后将其输入到SVM分类器中对图像进行分类。下面的代码示例取自关于eigenfaces的sklearn文档,我们将一步一步地实现代码,以了解其复杂性和结果。导入相关库和模块首先,我们将导入所需的库和模块,我们将在后文深入讨论我们为什么要导入它们。import pylab as pl
import numpy as np
from matplotlib import pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.datasets import fetch_lfw_people
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
from sklearn.decomposition import PCA as RandomizedPCA
from sklearn.svm import SVC
将数据加载到Numpy数组中接下来,我们将数据下载到磁盘中,并使用fetch_lfw_people将其作为NumPy数组加载到sklearn.datasetslfw_people = fetch_lfw_people(min_faces_per_person=70, resize=0.4)
lfw数据集包括一个用于研究无约束人脸识别问题的人脸图像数据库,它从网络收集的13000多张照片中包含了超过13000张照片,每个人脸都贴上了照片,1680个人脸在数据集中有两张或两张以上不同的照片。图像采用灰度值(像素值=0-255)。
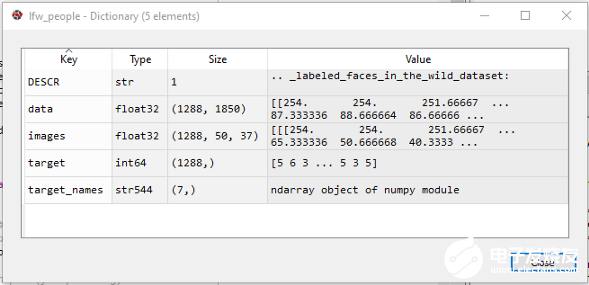
图像Numpy数组接下来,我们将寻找图像数组图片的形状。我们使用NumPy shape属性,该属性返回一个元组,每个索引都有对应元素的数量。
n_samples, h, w = lfw_people.images.shape
np.random.seed(42)
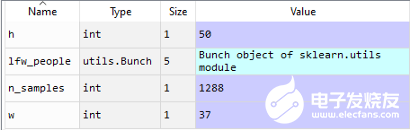
从变量explorer可以看到,我们有1288个样本(图片),高度为50px,宽度为37px(50x37=1850个特征)Numpy数组我们使用lfw_people 的data数组,直接存储在X中,我们将在以后的处理中使用这些数据。X = lfw_people.data
n_features = X.shape[1]
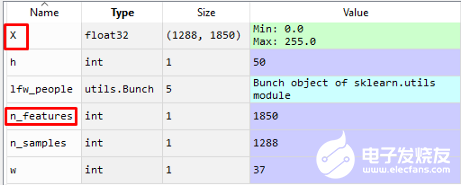
X中的数据有1288个样本,每个样本有1850个特征。label接下来,我们将定义label,这些label是图片所属人的id。y = lfw_people.target
target_names = lfw_people.target_names
n_classes = target_names.shape[0]
这里,y代表目标,它是每个图片的标签。标签由target_names变量进一步定义,该变量由7个要识别的人的姓名组成。
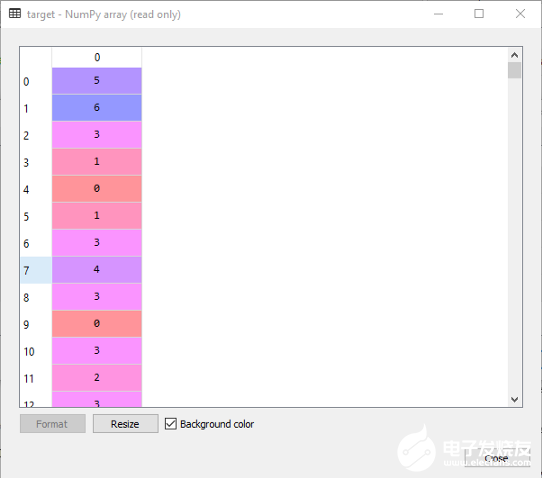
target是一个1288x1的NumPy数组,它包含1288张图片对应名称的0–6值,因此,如果id=0的目标值为5,则表示该人脸为“Hugo Chavez”,如target_names中所示:
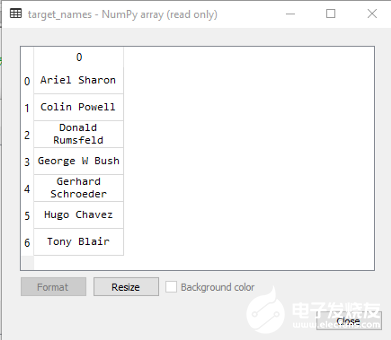
因此,y是数字形式的目标,target_names是名称中的任何目标/标签,n_classes是存储类数量的变量,在我们的例子中,我们有7个:Ariel SharonColin PowellDonald RumsfeldGeorge W BushGerhard SchröderHugo ChavezTony Blair
让我们打印出变量:print("Total dataset size:")
print("n_samples: %d", n_samples)
print("n_features: %d", n_features)
print("n_classes: %d", n_classes)
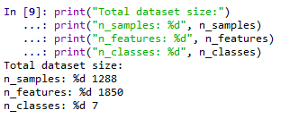
所以,我们有1288个样本(图片),每个样本总共有1850个特征(50px37px)和7个类(人)。划分训练集和测试集接下来,我们使用sklearn.model_selection将数据(X-特征和y-标签)分为训练数据和测试数据,其中25%用于测试,其余75%用于训练模型。X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)
以下是变量X-train、X_test、y_train和y_test:


基于PCA的降维方法现在,我们从 sklearn.decomposition中选择PCA 以训练模型。我们已经在第一段代码中导入了PCA在我们的例子中,我们在训练集X_train中总共有966个特征,我们使用PCA(维数缩减)将它们减少到50个:n_components = 50
pca = RandomizedPCA(n_components=n_components, whiten=True).fit(X_train)
这个过程需要不到一秒钟的时间,这可以通过使用时间函数进行验证(让我们暂时跳过它)。现在我们将重塑PCA组件并定义特征脸,这是在人脸识别的计算机视觉问题中使用的一组特征向量的名称:eigenfaces = pca.components_.reshape((n_components, h, w))
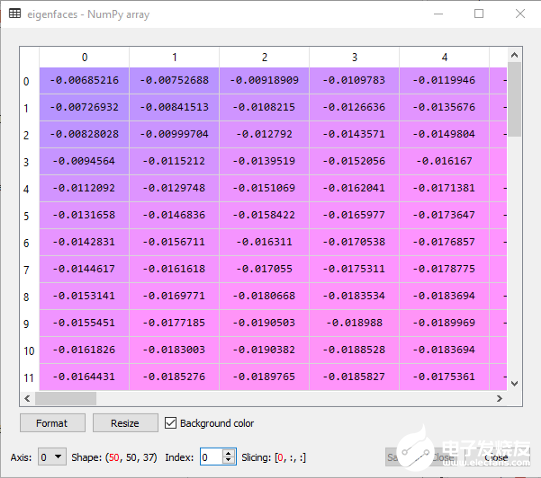
如截图所示,特征脸是一个50×50×37的Numpy数组,50对应于特征的数量。接下来,我们使用PCA在X_train 和X_test 上的transform 函数来降低维数。X_train_pca = pca.transform(X_train)
X_test_pca = pca.transform(X_test)

从上面的截图可以看出,通过PCA算法,X_train和X_test的维数都被降低了,每一个都将特征从1850个减少到50个(正如我们在算法中定义的那样)。训练SVM分类器一旦我们完成了降维,就开始分类了。首先,我们将训练SVM分类模型。我们使用GridSearchCV,这是一个库函数,它是一种调整超参数的方法,它将系统地为网格中指定的算法参数的每个组合建立和评估模型,并在最佳估计量,参数在参数网格中给出:print("Fitting the classifier to the training set")
param_grid = {
'C': [1e3, 5e3, 1e4, 5e4, 1e5],
'gamma': [0.0001, 0.0005, 0.001, 0.005, 0.01, 0.1],
}
clf = GridSearchCV(SVC(kernel='rbf', class_weight='balanced'), param_grid)
clf = clf.fit(X_train_pca, y_train)
print("Best estimator found by grid search:")
print(clf.best_estimator_)

我们数据的最佳分类器是SVC,参数如下:SVC(C=1000, class_weight = ‘balanced’, gamma=0.01)预测现在让我们在测试数据上预测这些人的名字,我们使用从GridSearchCV中找到的分类器,它已经在训练数据拟合。print("Predicting the people names on the testing set")
y_pred = clf.predict(X_test_pca)
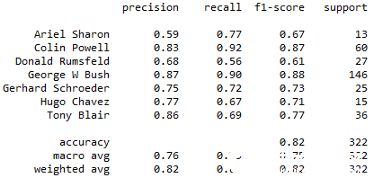
分类报告和混淆矩阵一旦预测完成,让我们打印分类报告,它显示了模型的精度、召回率、F1分数和支持分数,这使我们对分类器的行为有了更深入的直觉。print(classification_report(y_test, y_pred, target_names=target_names))
让我们打印混淆矩阵:print(confusion_matrix(y_test, y_pred, labels=range(n_classes)))

混淆矩阵打印真正例、假正例和假反例的值,并提供分类器的概述。绘图最后,我们将绘制人物肖像和特征脸!我们将定义两个函数:title在测试集的一部分绘制预测结果,plot_gallery通过绘制它们来评估预测:def title(y_pred, y_test, target_names, i):
pred_name = target_names[y_pred[i]].rsplit(' ', 1)[-1]
true_name = target_names[y_test[i]].rsplit(' ', 1)[-1]
return 'predicted: %strue: %s' % (pred_name, true_name)
def plot_gallery(images, titles, h, w, n_row=3, n_col=4):
"""绘制肖像库的帮助函数"""
plt.figure(figsize=(1.8 * n_col, 2.4 * n_row))
plt.subplots_adjust(bottom=0, left=.01, right=.99, top=.90, hspace=.35)
for i in range(n_row * n_col):
plt.subplot(n_row, n_col, i + 1)
plt.imshow(images[i].reshape((h, w)), cmap=plt.cm.gray)
plt.title(titles[i], size=12)
plt.xticks(())
plt.yticks(())
现在让我们在测试集的一部分绘制预测结果:prediction_titles = [title(y_pred, y_test, target_names, i)
for i in range(y_pred.shape[0])]
plot_gallery(X_test, prediction_titles, h, w)
现在让我们绘制特征面。我们使用在上面代码块中定义的eigenfaces变量。eigenface_titles = ["eigenface %d" % i for i in range(eigenfaces.shape[0])]
plot_gallery(eigenfaces, eigenface_titles, h, w)
plt.show()
最后,我们来绘制PCA+SVM模型用于人脸识别的精度:from sklearn.metrics import accuracy_score
score = accuracy_score(y_test, y_pred)
print(score)
我们的准确分数是0.81!虽然这并不是一个完美的分数,还有很大的改进空间,但PCA和SVM的人脸识别为我们提供了进一步强大算法的起点!结论本文利用PCA和SVM建立了一个人脸识别模型。主成分分析算法被用来减少数据的维数,然后利用支持向量机进行分类,通过超参数调整寻找最佳估计量。我们对这些肖像进行了分类,准确度得分为0.81。
责任编辑:gt
-
人脸识别
+关注
关注
77文章
4132浏览量
88761 -
机器学习
+关注
关注
67文章
8565浏览量
137226
发布评论请先 登录
【瑞萨AI挑战赛】阶段一:基于RA8P1的人脸识别模型转换和部署
人脸识别身份核验终端厂家怎么挑?记住这四个黄金法则

【上海晶珩睿莓 1 单板计算机】人脸识别
如何挑选人脸识别终端?人脸识别一体机品牌排行榜


【EASY EAI Orin Nano开发板试用体验】EASY-EAI-Toolkit人脸识别
基于LockAI视觉识别模块:C++人脸识别
基于LockAI视觉识别模块:C++人脸识别

【EASY EAI Orin Nano开发板试用体验】人脸识别体验

选择户外场景的人脸识别门禁一体机,需要具备哪些条件?


无需接线!1个底板可测试海凌科5款人脸识别模块

搭乘交通工具使用刷脸核验一体机有必要吗?

人脸识别门禁终端的一般故障排查方法




评论