 PowerVR GPU架构的性能优化建议
PowerVR GPU架构的性能优化建议

最近在看移动GPU优化的时候对TiledBased GPU有一些疑惑,特别是常说的Alpha-Blend比Alpha-Test在移动GPU上快的奇特性质,于是找了powerVR相关的文档来阅读,也做个记录。
Imagination的powerVR架构的GPU之前主要是iOS手机系列的GPU供应商,而苹果自从17年宣布要逐步放弃使用imagination的GPU技术转而自主研发GPU开始,powerVR架构就似乎前途未卜。Apple A11处理器开始到最新的iphone XS 使用的A12处理器,都是苹果自研的GPU,相比起之前的powerVR的GPU有巨大的性能提升。虽然苹果转向了自研GPU,但似乎其架构还是继承于PVR,相应的TBDR也是保留的,所以powerVR架构相关的知识对于iOS的GPU开发依旧还是有用的。同时Metal2提供了一些新的feature如Imageblocks,Raster Order Groups等新feature,这部分是Apple对TBDR架构的加强与优化。
主流图形架构
Immediate Mode Renderer(IMR)
Tile Based Renderer(TBR)
Tile Based Deferred Renderer(TBDR)
Unified and Non-unified shader architecture
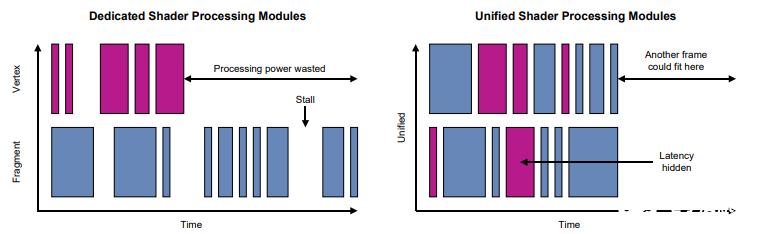
非统一的着色器架构上Vertex Shader要等待Fragment Shader执行完后才能push处理完的顶点数据丢给FS单元。
而统一的着色器架构,处理会减少等待时间,提升性能。PowerVR全部采用的都是Unified Shader Architecture.
Overdraw
由于geometry提交顺序的不同,会有一些fragment会被重复绘制。
为了减少overdraw的情形,图形计算核心会进行Early-Z testing的操作以减少Overdraw。
IMR
每一个渲染对象/drawcall完成了整个渲染管线流程写入frameBuffer才会开始渲染下一个对象/drawcall。在IMR模式下,Early-Z test可以直接将深度测试的几何图元跳过以提升性能,但是Early-Z test依赖渲染绘制对象的提交顺序是从前往后的。
同时每一次渲染完的color与depth数据读取写回到colorbuffer与depth/stencil buffer是都会产生很大的带宽消耗。普通的Read-Modify-Write都是在system memory与GPU之间传输数据,如ZWrite/Write,Blend这些。所以IMR的架构会有一个很大显存cache来优化这部分大量的内存带宽消耗。
TBR
整个光栅化和fragment处理会被分为一个个Tile进行处理,通常为16×16大小的Tile。
TBR的结构添加了on-chip buffers用来储存tiling后的Depth Buffer和Color buffer。原先IMR架构中对主存中color/depth buffer进行Read-Modify-Write的操作变成直接在GPU中的高速内存操作,减少了最影响性能的系统内存传输的开销。
虽然TBR减少了IMR的带宽开销,但是依然没有解决overdraw的问题。
TBDR
PowerVR的渲染架构 Tile Based Deferred Rendering(TBDR)
数据从内存到GPU之间的传输是最大的性能消耗,powerVR架构的TBDR,on-chip buffer都为了该目标而优化。
TBDR 架构关注于在渲染管线中尽可能移除冗余的操作与计算,最小化内存带宽和能耗同时提升管线处理的吞吐量。
TBDR将每个Tiler的渲染过程拆分为两个步骤,一个是Hidden Surface Removal(HSR)和 deferred pixel shading。
TBDR会尽可能地延迟pixel shading的时间,直到所有光栅化后的fragment完成了DepthTest和HSR。对于一个场景中全是不透明几何图元的渲染画面来说。每一个光栅化完的fragment patch会经过HSR和Depth test,在所有triangle完成了raster之后,最后留下来的fragment会留下来执行pixel shading。也就是在这种情况下tile中的每一个像素只执行一次pixel shader。
如果渲染流程中有alpha test/blend/pixel depth write,就会阻断deferred shading,因为这个时候需要执行shading,才能正确进行后续fragment的计算。
Alpha Test需要执行shading 算出当前fragment的alpha,判断该fragment是否被丢弃。
Alpha Blend 需要读取framebuffer中当前像素之前的颜色。
Pixel Depth write会影响到后续fragment的HSR与Depth test。
这三种情况下Pixel Depth Write,因为会影响到后续fragment HSR/Depth,所以这个时候一定要执行该像素的shading,打乱了原先deferred的流程。具体要看GPU实现时时把整个HSR步骤积累的fragment都shading掉还是只把当前fragment shading掉。
而对于AlphaBlend来说,它并不一定要打断deferred shading。
遇到blending的fragment,可以把该fragment像素位置的所有fragment按顺序保留在列表中,等到shading时按顺序计算blend。
但这样就会增加pixel shading的次数。具体的实现还是要参照GPU的实现方式,由于使用TBR,Blend的开销相对比IMR还是降低了很多。
Alpha-Test的情况是和Pixel Depth Write类似,由于Alpha Test失败fragment会被丢弃,如果其开启了DepthWrite,那么就一定要执行shading。因为alpha-test会影响后续fragment的HSR/Z-Test的流程。如果没有开启depth Write,也可以和Blend一样保留后续所有fragment的方式来延迟shading。但是这个时候后续该位置的fragment patch都是不能被移出shading列表的,延迟shading也没有意义了。
关于PowerVR 架构
Vector处理单元
高效计算单元,同时计算3到4个元素。如果一个计算的值小于4个,那么其他的计算会被浪费。只对一个元素进行计算时,效率会降低到25%,造成计算和电能的浪费,可以通过合并vector来优化。
Scalar处理单元
标量计算单元更加灵活,不需要填充其他的位宽数据。每一个硬件tick比起非向量化优化的代码能处理更多有效的数据值。
Verte Processing (Tiler)
Tile Accelerator(TA)计算每个transform后的图元属于哪个tile。
计算完后,per-tile队列会更新。变换后的几何体和tile list会被储存在Parameter Buffer(PB)中。PB被储存在系统内存中。
Per-Tile Rasterization (Render)
Image Sythesis Processor(ISP)获取当前tile的primitive数据,进行HSR,同时进行Z-Test和Stencil Test。ISP只处理ScreenSpace Position,和vertex data。
接下来是Texture and Shading Processor (TSP),处理fragment shaders和visible pixels。当Tile的渲染结束之后,color data会被写回到主存中的framebuffer中。直到所有的tile都完成渲染后,整个frameBuffer就完成了。
PowerVR Shader Engine
massive multi-threaded and multi-tasking approah.
HSR Efficiency
Early-Z testing 需要按从前往后顺序提交opaque对象的draw call,需要进行排序会有额外的overhead。当物体有intersection时,Eearly-Z testing并不能移除所有的overdraw,同时对draw call进行排序可能会造成pipeline 状态改变产生的overhead。
PowerVR 的HSR尽可能减少了fragment shading的数量。
性能优化建议
对drawcall进行排序
对于TBDR架构来说,所有的drawcall 按照 opaque - alpha-tested - blended进行排序会最大程度利用HSR减少overdraw。对于有blend的pixel来说,后续所有相同位置的pixel都需要进行pixel shading,而alpha-test在完成后的像素还是可以继续进行HSR的优化。所以比先blend提交alpha-test可以尽可能减少overdraw。
始终进行Clear操作
在IMR架构中,进行Clear操作需要对fragment buffer每个像素设置一遍值。如果确认画面会被完全重绘覆盖的情况下,不进行Clear操作会有减少这部分的性能开销。而在移动平台的GPU上并不是这样,由于移动平台为了减少内存与GPU间的带宽消耗,frameBuffer是分块存在on-chip memory中的。在整个渲染过程结束后将所有的tiled framebuffer 拷贝到主存中的framebuffer中。如果不进行clear,而在上一帧的buffer上重新绘制,需要在每个tiled frameBuffer开始绘制之前从主存再同步到on-chip的内存中。这一部分会有很大的overhead。
不要在每一帧开始绘制之后更新Buffer
由于GPU绘制采用的是双缓冲绘制,当前帧提交的draw call会在下一帧进行绘制,而当前帧绘制上一帧提交的draw call。如果在帧中间更新buffer,而这个buffer在上一帧提交的drawcall中被使用,有可能当前帧更新的buffer正在GPU中渲染,而此时驱动层将复制一份buffer来进行数据的更新或者等待当前绘制命令完成再进行更新。这两种情况一种会造成驱动层的overhead,而另一种会造成CPU的阻塞。
使用压缩贴图和Mipmapping
使用压缩的贴图格式会减少传输的带宽,从而提升性能。同时由于在TileBased架构下,部分按块压缩的贴图压缩格式可以和FrameBuffer的Tile进行匹配,其结构对于贴图缓存来说更加友好。
尽可能使用Mipmapping,首先使用mipmap,对于较远以及较小的贴图物体会有更好的抗锯齿效果,减少画面的闪烁以提升画面效果。其次使用在采样贴图时,对于不同大小的物体选用其大小相对应层级的贴图到对应的TextureCache能有效减少贴图缓存missing的几率以提升贴图采样的效率。同时由于有不同层级的贴图,会大量减少每次将贴图从内存复制到GPU的带宽消耗,同时使用Mipmap只会增加33%的内存消耗。
-
gpu
+关注
关注
28文章
5272浏览量
136070 -
powervr
+关注
关注
0文章
100浏览量
31570
发布评论请先 登录
内存要取代GPU?HBM之父警告:以英伟达GPU为核心的架构要被颠覆

Visionfive 2 缺少文件img-gpu-powervr-bin-1.17.6210866.tar.gz怎么解决?
NVIDIA RTX PRO 2000 Blackwell GPU性能测试

如何看懂GPU架构?一分钟带你了解GPU参数指标

在Imagination GPU上优化计算任务的十大技巧
ADI建议电源开发优先考虑电源架构的优化
如何在Ray分布式计算框架下集成NVIDIA Nsight Systems进行GPU性能分析
Redis集群部署与性能优化实战
【「算力芯片 | 高性能 CPU/GPU/NPU 微架构分析」阅读体验】+NVlink技术从应用到原理
GPU架构深度解析
ARM Mali GPU 深度解读
又一颗国产GPU芯片成功点亮!6nm制程,自研TrueGPU架构
iTOP-3588S开发板四核心架构GPU内置GPU可以完全兼容0penGLES1.1、2.0和3.2。
提升AI训练性能:GPU资源优化的12个实战技巧



评论