 ARM Mali GPU 深度解读
ARM Mali GPU 深度解读

ARM Mali GPU 深度解读
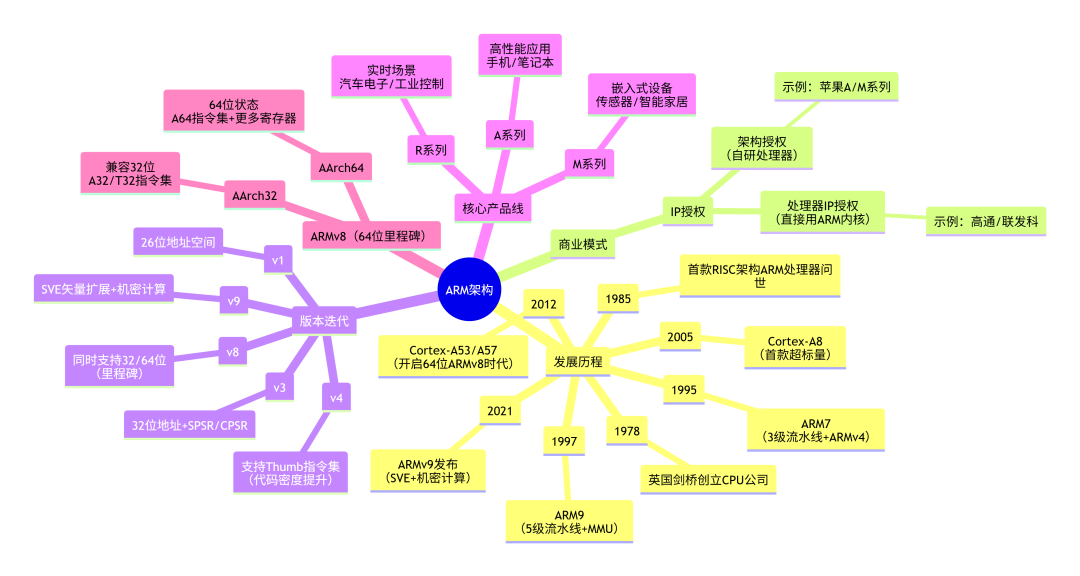
ARM Mali 是 Arm 公司面向移动设备、嵌入式系统和基础设施市场设计的图形处理器(GPU)IP 核,凭借其异构计算架构、能效优化和生态协同,成为全球移动设备 GPU 市场的核心力量。以下从技术演进、架构特性、产品布局及生态战略等维度展开分析:
一、架构演进:从 Utgard 到 Valhall
Mali GPU 的架构迭代以 北欧神话元素命名,技术特性与性能提升同步推进:
Utgard 架构(2007-2012):
- 代表型号:Mali-200、Mali-400 MP
- 特性:基于 分离式顶点与片段着色器,仅支持 OpenGL ES 2.0 及以下标准,适用于早期智能手机和嵌入式设备。例如 Mali-400 MP 支持 4 核扩展,像素填充率达 275M/秒(65nm 工艺)。
- 局限:能效比低,多核扩展能力有限,无法满足复杂 3D 渲染需求。
Midgard 架构(2013-2018):
- 代表型号:Mali-T760、Mali-T880
-
突破:
- 统一着色器架构:支持 OpenGL ES 3.0/3.1 和 OpenCL 1.2,实现 GPU 通用计算(GPGPU)。
- 多核扩展:单芯片最高支持 16 核(如 Mali-T760MP16),三角形输出率提升至 30M/秒,并首次引入 DirectX 11 支持(如 Mali-T760)。
- 应用:三星 Exynos 8890(T880)、联发科 Helio P10(T860)等中高端芯片。
Bifrost 架构(2016-2020):
- 代表型号:Mali-G71、G72、G76
- 创新:
Valhall 架构(2019-至今):
- 代表型号:Mali-G77、G78、G710
- 技术飞跃:
- 旗舰应用:华为麒麟 960(G71)、联发科天玑 2000(G710)。
二、核心特性:性能与能效的平衡
Mali GPU 的技术优势体现在 异构计算 与 标准化支持:
图形渲染能力:
- Tile-Based Rendering:分块渲染减少内存带宽消耗,支持 8K 实时渲染与光线追踪(如 Mali-G710 集成 ASR 超分技术)。
- API 兼容性:覆盖 OpenGL ES 3.2、Vulkan 1.3、OpenCL 2.0 及 DirectX 12,适配多平台开发需求。
AI 与通用计算:
- NPU 协同:Ethos-U NPU 与 GPU 共享内存,支持 Transformer 等大模型推理(如 Mali-G710 提供 8 TOPS 算力)。
- 低精度优化:BF16/INT8 量化加速,单位功耗下 MLPerf 性能提升 8 倍。
能效创新:
- 动态调频(DVFS):每核独立电源管理,功耗较 x86 GPU 降低 40%(如 Mali-G710 无风扇设计覆盖 80% 轻薄本市场)。
- Chiplet 封装:基于 Arm CSA 标准支持多晶粒互连,提升扩展灵活性(如 Socionext 2nm 工艺芯粒方案)。
三、产品线布局:全场景覆盖
Mali GPU 按性能划分为四大系列,适配不同市场需求:
高端旗舰(V/Valhall 系列):
- Mali-G710:16 核设计,支持 4K 120Hz 显示与 AI 超分,应用于旗舰手机(如三星 Galaxy S25)和 AI PC。
- Mali-G78:24 核配置,3DMark Wild Life 跑分超 8500 分,媲美苹果 M1 GPU。
中端主流(Bifrost 系列):
- Mali-G57:8 核设计,主打千元机市场(如 Redmi Note 系列),支持 Vulkan 1.1 和 OpenCL 1.2。
- Mali-G68:6 核精简版,适配平板和车载娱乐系统。
入门级(Midgard 系列):
- Mali-T720:单核架构,用于智能电视和低端物联网设备(如小米电视 6A)。
定制化方案:
- Mali Nano:针对教育终端和工控设备推出子平台,支持 300 美元以下设备本地化 AI 功能。
四、生态战略:软硬协同与开发者支持
ARM 通过 工具链优化 和 生态联盟 巩固市场地位:
开发工具链:
- KleidiAI:集成 TensorFlow Lite、PyTorch,模型部署时间缩短 50%(如阿里倚天 710 部署 Llama3 效率提升 1.9 倍)。
- Mali 调试套件:支持 OpenGL ES 仿真器和 Vulkan 性能分析,覆盖 2200 万开发者。
合作伙伴网络:
- 芯片厂商:联发科(天玑系列)、三星(Exynos)、华为(麒麟)均采用 Mali 公版架构。
- 云服务商:腾讯云、AWS 推出基于 Mali 的 GPU 实例(如 Graviton3 推理能效提升 60%)。
标准化认证:
五、挑战与未来方向
尽管 Mali 占据安卓 GPU 市场 30% 份额,但仍面临竞争与技术挑战:
市场压力:
- x86 生态壁垒:PC 领域 AMD/Intel 加速布局混合架构,2025 年 Arm PC 份额仅 13%。
- 竞品追赶:高通 Adreno 740 光追性能反超,苹果 M2 GPU 能效优势显著。
技术突破方向:
- 光线追踪普及:Valhall 架构需进一步优化实时光追效率,追赶 NVIDIA DLSS 3.0。
- 端云协同计算:通过 CoreLink CI-700 互连技术实现“端-边-云”一体化(如腾讯云 Mali 边缘节点)。
长期愿景:
- ARM 目标 2030 年赋能 50 亿台智能设备,成为 AIoT 与 6G 网络的算力底座。
总结
ARM Mali 通过持续架构迭代(Utgard → Valhall)和生态整合,已成为移动 GPU 领域的核心力量。其技术特性与 异构计算、能效优化 的深度结合,使其在智能手机、AI PC 及边缘计算场景中展现出强大竞争力。未来,随着 Chiplet 技术和光线追踪的进一步成熟,Mali 或将在高性能计算市场开辟新战场,推动“端侧智能普惠化”进程。
-
ARM
+关注
关注
135文章
9619浏览量
394681 -
gpu
+关注
关注
28文章
5339浏览量
136282
发布评论请先 登录
联发科正式推出天玑7500:首款Arm C1主流芯片
GB 44240深度解读(三)|| 热扩散试验为什么90%企业第一次都失败?

人工智能-Python深度学习进阶与应用技术:工程师高培解读

NVIDIA RTX PRO 5000 Blackwell GPU的深度评测

深度解析 ARM 架构:从剑桥车库到未来计算
Arm Lumex平台赋能新一代旗舰智能手机体验升级
Arm助力MediaTek天玑9500重塑旗舰体验

Arm神经技术是业界首创在 Arm GPU 上增添专用神经加速器的技术,移动设备上实现PC级别的AI图形性能
aicube的n卡gpu索引该如何添加?
别让 GPU 故障拖后腿,捷智算GPU维修室来救场!

【「算力芯片 | 高性能 CPU/GPU/NPU 微架构分析」阅读体验】+NVlink技术从应用到原理
直播 | GB/T 45086与ISO11451标准深度解读研讨会笔记请查收!

瑞萨365 深度解读



评论