好的,语音识别(Automatic Speech Recognition, ASR)系统是一个复杂的系统工程,通常包含以下主要组成部分:
-
前端处理 (Front-End Processing / Feature Extraction)
- 输入: 原始音频信号(麦克风采集的模拟声音,经过模数转换变成数字信号)。
- 主要任务: 对原始音频信号进行初步处理,提取对识别有用的、鲁棒的特征(特征向量序列),同时降低后续处理的计算复杂度。
- 关键模块:
- 预处理:
- 降噪/语音增强: 过滤或抑制背景噪声、回声等干扰(例如:谱减法、维纳滤波、深度学习方法)。
- 预加重: 提升高频分量,补偿发声时高频能量衰减。
- 分帧与加窗: 将连续的语音信号分割成短时(通常10-30毫秒)、有重叠(通常重叠一半)的小段(帧),并对每一帧应用窗函数(如汉明窗、汉宁窗)来减少帧边缘的不连续性。
- 特征提取: 计算每帧信号的声学特征。最核心的步骤。
- 梅尔频率倒谱系数: 是最经典和广泛使用的特征。它模拟人耳对频率的感知特性(梅尔刻度),通过对语音帧的傅里叶变换、梅尔滤波器组滤波、取对数、再进行离散余弦变换得到能较好表征声道特性的特征。
- 滤波组能量: MFCC的前一步。
- 线性预测系数: 另一种常用特征。
- 近年来: 深度学习模型有时直接从原始音频或低阶特征(如FBank)学习特征,降低了对手工设计特征(如MFCC)的依赖。
- 预处理:
-
声学模型 (Acoustic Model)
- 输入: 前端处理得到的特征向量序列(代表声音在时间上的变化)。
- 主要任务: 建立声音特征与音素(语音中最小的可区分单位,如“p”、“b”、“a”)或子词单元(如声韵母)之间的概率映射关系。它学习不同音素在特征空间中的概率分布。
- 核心技术:
- 隐马尔可夫模型: 早期核心模型,用于建模状态的序列转移(如音素内状态的转移:起始、稳定、结束)和状态发出的观测值(特征向量)的概率分布。每个音素通常由一个HMM表示。
- 高斯混合模型: 常与HMM结合使用,用于对HMM状态下发出的特征向量的概率分布进行建模。
- 深度神经网络: 现代声学模型的主流技术。
- DNN-HMM混合系统: DNN替代GMM,用于估计给定特征向量下属于每个HMM状态的后验概率(P(state | feature)),这比GMM建模的似然概率(P(feature | state))更鲁棒。
- 端到端模型:
- 连接时序分类: 一种无需显式帧级对齐的训练目标。
- 注意力机制: 直接学习特征序列与词序列之间的对齐和映射关系。
- 常用网络结构: 循环神经网络(RNN,如LSTM、GRU)、卷积神经网络(CNN)、Transformer(因其强大的序列建模能力而迅速成为主流)。
- 输出: 每一帧声音属于各个音素或子词单元的概率。
-
语言模型 (Language Model)
- 输入: 词汇表(或子词单元表)。
- 主要任务: 建模词序列(或子词序列)出现的合理性概率。例如,“我今天很开心”比“苹果我今天开心”具有更高的概率和更合理的语言结构。
- 关键作用: 帮助系统在声学特征存在歧义时(比如同音字/词),基于语言的统计规律和上下文,选择语义上更可能出现的词语序列。极大地提高了识别的准确性和流畅度。
- 核心技术:
- N-gram模型: 基于前面N-1个词来预测当前词的概率。计算简单,但难以建模长距离依赖。
- 神经语言模型: 现代主流技术。
- 基于 RNN / LSTM / GRU 的模型: 能有效建模长距离上下文依赖。
- Transformer-based 模型: (如BERT、GPT系列)因其无与伦比的上下文表示能力,在大规模预训练后作为语言模型效果卓越(通常微调使用)。
- 其它: 基于文法的模型(应用受限)。
- 输出: 词序列的联合概率P(w1, w2, ..., wm)。
-
发音词典 (Pronunciation Lexicon)
- 输入: 词汇表。
- 主要任务: 建立词到其组成音素(或子词单元)序列的映射关系。
- 格式: 一个大的查询表(或映射函数)。例如:
- 我:
wo3(注:这里wo3代表拼音音节序列对应的音素序列) - 今天:
jin1 tian1 - 开心:
kai1 xin1
- 我:
- 关键作用: 连接声学模型和语言模型的桥梁。 它将语言模型预测的词序列与声学模型建模的音素序列联系起来。
-
解码器 (Decoder)
- 输入:
- 前端特征序列(或声学模型输出的概率分布序列)。
- 声学模型(提供帧级别的音素概率)。
- 语言模型(提供词序列概率)。
- 发音词典(提供词与音素的对应关系)。
- 主要任务: 在整个可能的候选词序列空间中,搜索并选择得分最高的那条路径。得分结合了声学模型输出(这个声音像某个音素的概率)和语言模型输出(这些词这样组合是否合理自然)。这是一个动态规划搜索问题。
- 核心技术:
- 动态规划:
- 时间同步的束搜索: 最常用。它结合了隐马尔可夫模型的状态转移和加权有限状态机(通常结合了声学模型HMM拓扑、词典、语言模型信息)的概念,在时间帧上同步地搜索,并通过剪枝(Beam Search)保留概率最高的N条候选路径(称为“束宽”),避免搜索空间爆炸。
- 启发式搜索:
- 堆解码: 按路径得分排序搜索。
- *A 搜索:** 结合启发函数加速搜索。
- 动态规划:
- 输出: 识别出的最佳(或N个最佳)词序列。
- 输入:
-
端点检测与语音活动检测
- 输入: 原始音频流。
- 主要任务: 检测音频流中语音段落的起点和终点,区分语音段(包含需要识别的语音)和非语音段(沉默、背景噪声)。
- 重要性: 在实时识别系统中至关重要。它能忽略无效的非语音部分,节省计算资源,并且有助于提高准确性(避免语言模型对无效静音建模)。
- 技术: 通常基于能量、过零率、频域特征或机器学习/深度学习模型(如二分类:语音/非语音)。
-
后端处理/集成 (Back-End Processing / System Integration)
- 将上述核心组件集成在一起,形成完整的识别流程。
- 可能包括:
- 置信度评分: 评估识别结果的可靠性。
- 结果后处理: 如数字规整(把“幺两三”转成“123”)、标点预测、大小写处理、领域自适应(如医疗、法律术语)。
- 纠错: 基于语言模型或特定规则进行一定纠错。
- 输出格式化: 转换为最终所需的格式(文本流、带时间戳的字幕等)。
- 系统资源管理: 确保低延迟、高吞吐量(尤其对于实时系统)。
总结: 一个典型的ASR系统工作流程是: 原始音频 -> (预处理/VAD) -> 前端特征提取 -> 声学模型 -> (发音词典 + 语言模型) -> 解码器搜索最优词序列 -> 后端处理 -> 输出识别文本。
现代端到端模型尝试简化或合并这些组件(特别是声学模型、发音词典、解码器),利用一个统一的神经网络直接从音频特征序列预测词序列(或其概率),但其内部仍然隐式或显式地建模了类似的功能。
怎么设计基于嵌入式系统的语音口令识别系统?
随着计算机技术和信息技术的迅速发展,语音口令识别已经成为了人机交互的一个重要方式之一。语音口令识别系统将根据人发出的声音、音节或短语给出响应,如通过语音口令控制一些执行机构、控制家用电器的运行或做出
![]() 60user104
2019-09-03 08:27:23
60user104
2019-09-03 08:27:23
嵌入式语音识别系统中的电路设计是如何的
现在社会发展的这么快,什么高科技都涌现出来,什么智能机器人啦,智能手机等,有很多在这里就不一一列举了,在这里我们要说的就是语音识别系统了,现在嵌入式产品如此的多,就像一些智能空调啦,我们可以对着他说
![]() 王小琳子
2021-12-20 07:52:03
王小琳子
2021-12-20 07:52:03
语音识别系统功能_语音识别系统的应用
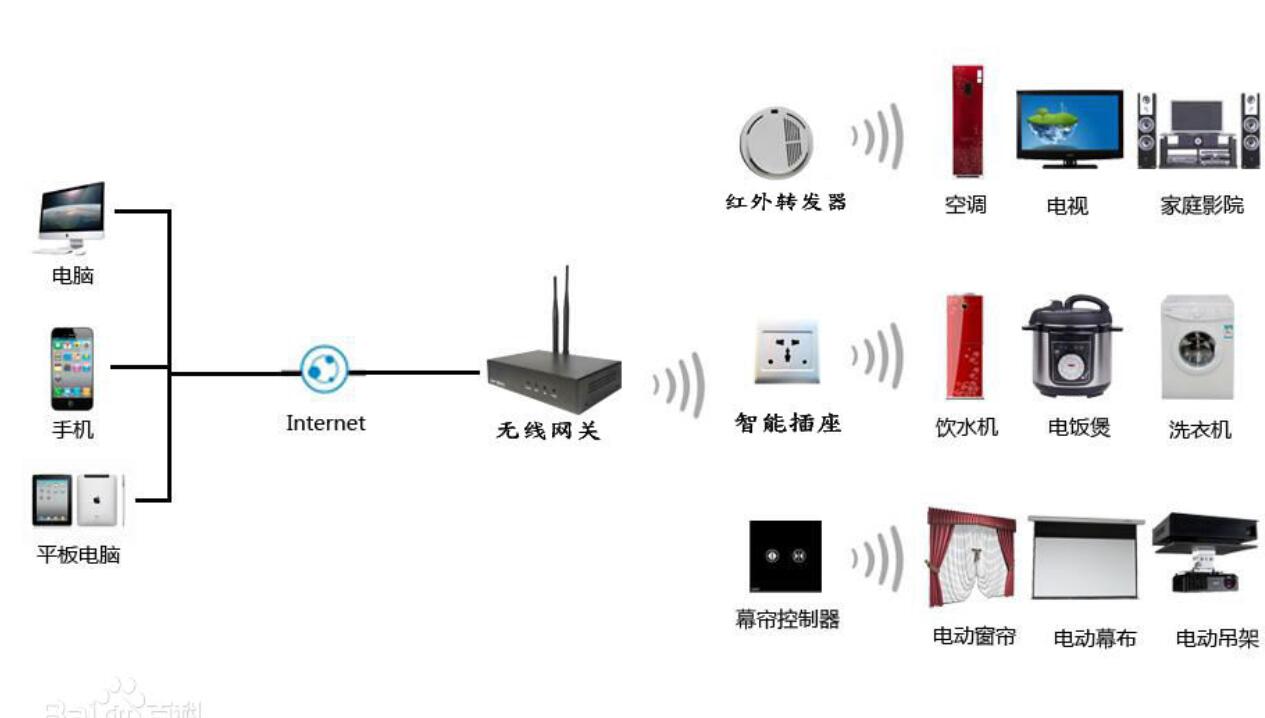
对比语音识别技术的两个发展方向,由于基于不同的运算平台,因此具有不同的特点。大词汇量连续语音识别系统一般都是基于PC机平台,而语音识别专用芯片的中心运算处理器则只是一片低功耗、低价位的智能芯片
2019-10-01 09:21:00
怎样去设计基于嵌入式Linux的语音识别系统
该设计运用三星公司的S3C2440,结合ICRoute公司的高性能语音识别芯片LD3320,进行了语音识别系统的硬件和软件设计。在嵌入式Linux操作系统下,运用多进程机制完成了对语音识别芯片
![]() 小华同学
2021-11-04 09:03:09
小华同学
2021-11-04 09:03:09
车载语音识别系统语音数据采集标注案例
车载语音识别系统是指利用机器学习算法实现的一种自然语言处理技术,载语音识别系统通过辨别声音的语调、语速和音量,将所听到的语音转化成可读取的语言数字,从而达到实现车辆控制、语音导航等多个汽车控制功能
2024-06-19 15:49:42
车载语音识别系统语音数据采集标注案例

车载语音识别系统是指利用机器学习算法实现的一种自然语言处理技术,载语音识别系统通过辨别声音的语调、语速和音量,将所听到的语音转化成可读取的语言数字,从而达到实现车辆控制、语音导航等多个汽车控制功能
2024-06-19 15:52:04
医疗智能语音识别系统的研发与应用
结合语音识别技术构建医疗智能语音识别系统,达到减轻医护人员日常工作负担,减少重复性劳动,提高诊疗质量的目的。基于语音识别的关键技术和海量的医疗数据,开发电子病历与检查报告智能语音录入、移动护理智能语音录入、非接触式智能语音数据交互系统。
2019-10-21 16:46:27
基于STM32嵌入式的孤立词语音识别系统设计
语音识别是机器通过识别和理解过程把人类的语音信号转变为相应文本或命令的技术,其根本目的是研究出一种具有听觉功能的机器。本设计研究孤立词语音识别系统及其在STM32嵌入式平台上的实现。识别流程是:预
![]() jghgfdssas
2021-08-06 08:32:00
jghgfdssas
2021-08-06 08:32:00
嵌入式语音识别系统是什么
嵌入式语音识别系统分为封闭域识别和开放域识别,封闭域识别范围围绕指定的字/词语集合,也就是说在开发系统的时候会设定好应识别的字或词语,对范围外的词语语音系统不会识别。
2019-06-12 11:38:09
基于JuliUS语音识别引擎实现机器人孤立词语音识别系统的设计
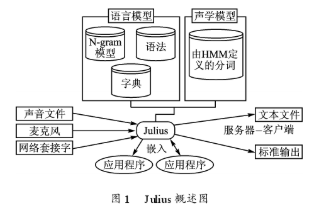
语音识别系统是一种模式识别系统,系统首先对语音信号进行分析,得到语音的特征参数,然后对这些参数进行处理,形成标准的模板。这个过程称为训练或学习。当有测试语音进入系统时,系统将对这些语音信号进行处理,然后进行参考模板的匹配,得出结果。此时便完成了语音识别的过程。
2020-04-06 17:13:00
一种基于嵌入式系统的语音口令识别系统的设计

随着计算机技术和信息技术的迅速发展,语音口令识别已经成为了人机交互的一个重要方式之一。语音口令识别系统将根据人发出的声音、音节或短语给出响应,如通过语音口令控制一些执行机构、控制家用电器的运行或做出
2019-04-23 15:52:53
基于AVR单片机的语音识别系统设计
基于AVR单片机的语音识别系统设计,系统以AVR单片机为控制核心,实现对人的语音的识别控制。系统采用的主控芯片为Atreel公司的ATMEGAl28,语音识别功能采用ICR oute公司的单芯片
![]() 一只耳朵怪
2021-01-13 15:54:14
一只耳朵怪
2021-01-13 15:54:14
怎样去搭建一个基于kaldi的在线语音识别系统
(GMM+HMM+NGRAM)概述)。一段时间后老板就布置了具体任务:在我们公司自己的ARM芯片上基于kaldi搭建一个在线语音识别系统,三个人花三个月左右的时间完成。由于我们都是语音识别领域的小白,要求...
![]() felixbury
2021-07-29 08:59:19
felixbury
2021-07-29 08:59:19
关于语音识别模块的组成
随着科技的进步,时代的进步,语音识别技术也是日新月累,在快速的发展着。语音识别技术又被叫做语音识别系统,简单点说,就是一个拥有一定识别能力的语音芯片组块,语音识别模块被常常用于各个行业之中,一般
2021-03-18 14:15:11
设备漏油检测识别系统漏油自动识别系统 燧机科技

2024-09-21 11:32:51
汽车Vin码识别系统,就用OCR识别技术
案例,全程技术支持,集成简单、快捷。产品组成----------汽车VIN码识别系统的优势——识别率高、识别速度快识别率高达99%,识别速度小于1秒------------——汽车VIN码识别系统覆盖
![]() 杨英杰ocr
2019-06-28 13:40:19
杨英杰ocr
2019-06-28 13:40:19
 工商网监
工商网监





 工商网监
工商网监