 基于神经网络的图片风格转移
基于神经网络的图片风格转移

前言
将A图片的风格转移到B图片上,指的是将A图片的抽象艺术风格(如线条、色彩等等)和B图片的内容框架合成为一幅图。自然地,A图片称为风格图,而B图片就称为内容图。就像这样:

左侧图作为风格, 右侧图作为内容,中间合成图。 (上图是我用Gatys迭代法得到的结果)。
最近做了一段时间风格转移的文献调研,故写此小结以顺思路。图片风格转移在传统图像处理中有不少研究,本文只涉及基于神经网络的方法。个人总结到目前主要有以下4个技术阶段:
迭代合成法。合成图片质量高,且可以进行任意风格转移,但速度慢;
前馈网格法。合成速度快,但一个网络只能进行一种风格转移(风格单一),且合成图片质量一般;
使用IN层替换BN层,提升了合成图片的质量,加速了网络训练,但网络的风格还是单一或局限于几种;
使用IN层μμ和σσ匹配的网络前馈法,最终实现任意风格的快速转移。
本文将对这四个阶段进行回顾,之后再涉及另一种风格转移方法:基于GAN的图片集合风格转移。 最后,回顾技术,展望下未来的发展方向。
Stage1:iterative image style transfer (IST)
文章:
Image style transfer using convolutional neural networks,Gatys etc.
一句话总结:这篇文章为风格转移提供了量化标度,提出使用 Gram矩阵来量化图片的风格。并提出了基于VGG网络的迭代式图片合成方法。图片生成质量较高。
将一幅图片的风格转移到另一幅画上,首先要解决的问题自然是如何提取风格?*(也有不需要量化风格的,下面Extra章会讲到)*Gatys 在这篇文章中提出用feature map的Gram矩阵来量化一幅图片的风格。具体来说 ,一幅图片结过网络后,在第k层有M个feature map
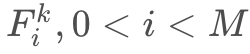
,每个feature map的维度为H×W, 那么第kk层的Gram矩阵值为:
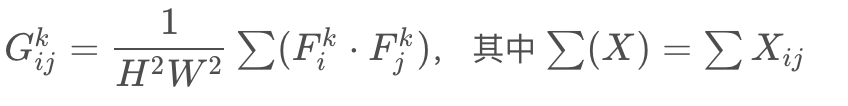
即第k层的Gram矩阵维度为M x M的矩阵, 其坐标(i,j)(i,j)处的元素值为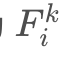 与
与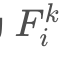 点乘后元素求和再归一化得来。可以笼统认为Gram矩阵是同层的feature map之间的相似关系。
点乘后元素求和再归一化得来。可以笼统认为Gram矩阵是同层的feature map之间的相似关系。
这个量化方法到底能多大程度上提取风格呢? 一种验证的途径是根据一张图xGram矩阵G,如果能重建出具有风格x的图片,则说明G对风格提取有一定作用(但不是充要条件,最终还是要看用来最后的合成过程中是否能指导图像的生成),这种重建图像的方法其实也是Gatys最后用于生成合成图片的方法。不管怎么样,先实验起来吧。
验证实验是基于VGG网络进行的,VGG网络在图片分类任务中已经取得了公认的成果,所以一般认为其各个输出层的feature map应该是较好地提取了图像的语义。VGG网络的过程可以抽象表示为函数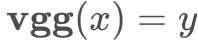 ,x为输入,yy为输出,xx可以是所有层的输出,也可以是其子集。将yy进一步根据上面的定义运算得到Gram矩阵的Vgg_G表示。Gatys提出了以迭代方式梯度下降的方法根据VGG网络输出重建图片的方法,即:如果需要两幅图相同,需要两幅图经过VGG网络后的输出也相同。以vggvgg为例,步骤如下:
,x为输入,yy为输出,xx可以是所有层的输出,也可以是其子集。将yy进一步根据上面的定义运算得到Gram矩阵的Vgg_G表示。Gatys提出了以迭代方式梯度下降的方法根据VGG网络输出重建图片的方法,即:如果需要两幅图相同,需要两幅图经过VGG网络后的输出也相同。以vggvgg为例,步骤如下:
KaTeX parse error: Expected '}', got '_' at position 12: \textbf{vgg_̲G}
先以随机值生成图像x′x,它经过网络输出为 y′。目标图片为xx, 经过风格的输出为yy。待重建的目标图片x与x′的距离以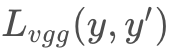 来表示。那么以
来表示。那么以

x′=x′−η∗∂y′∂Lvgg(y,y′)
的方式对x′x进行更新,其实就是以vgg函数作为指引逼近目标x的过程,最终稳定后得到的就是重建的图像。注意在迭代过程中网络函数vggvgg不变,即VGG网络的模型参数保持不变。
进行更新,其实就是以vggvgg
Gatys分别使用了vgg和vggG对图片进行了重建。分别使用VGG网络的第1到第5层的输出指引重建,结果如下,上面星空图是使用vggGvggG进行实验, 下面建筑图使用vggvgg进行重建:vgg
和vggGvggG
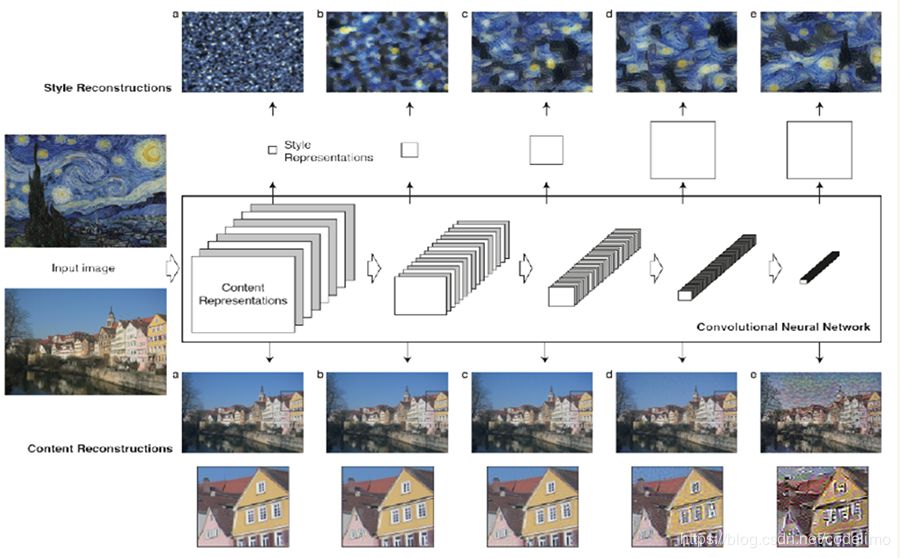
可以看出,在下面一排用vgg进行重建的实验组中,重建的图像风格相似,但内容框架已经完全错乱了,所以确实可以理解为它更侧重于保留风格而不注重框架。
我个人猜想Gram矩阵的想法是实验驱动的。虽然不一定是对风格最好的量化(毕竟风格是很主观的东西,也很难有最优答案),但Gatys提出的量度还是开创性且可用的。
有了上面的实验,自然就会有这样一个想法:如果既使用vggG将x′风格约束到一幅图A,同时又使用vggvgg将x′内容框架约束到另一幅图B,那重建出来的不就是“合成了” A与B吗? 下面的图就是描述的这个过程:
将x
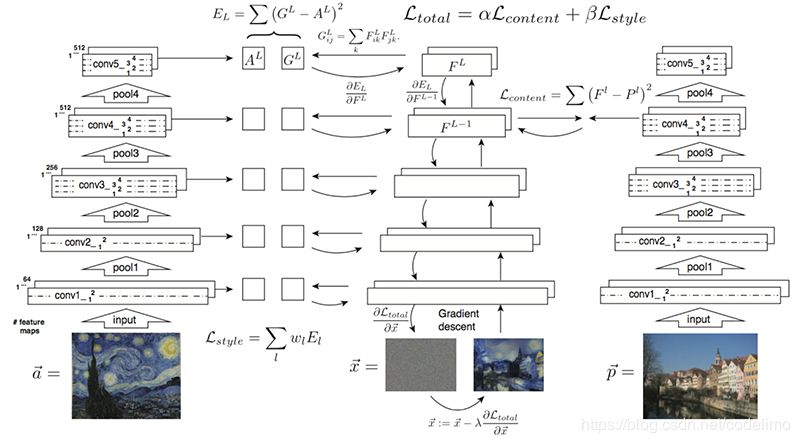
上图乍看挺复杂,其实思想很简单。就是把vgg或者vggG的距离整合,可以看到图中衡量距离的loss是将content与 style按比例系数αα和ββ整合到一起了,所以这两个系数也会决定最终的生成图片是更接近风格图片还是更接近内容图片。另外Gayts还发现由于这里的变量只有一个x′上面的梯度下降迭代可以用L-BFGS迭代来替换以更快地找到最优点。vggvggx′
或者vggGvggGGatys的工作提出了量化图像风格的方法,并迭代地逼近一幅满意的结果图。这种方法的优点是生成的图质量好,缺点是速度慢,每次要合成时都要迭代运算多次。
对于Gram矩阵能引导风格转移的内在机理,Yanghao Li等人进行了研究,在下面Stage4.2中会叙及。
Stage2: fast IST
如上述,Gatys的方法生成图片质量高,但在速度上不尽人意。我们知道一般神经网络都是先训练好,之后使用时只进行一次前馈推理即可,即 feed-forward one pass,而推理的速度是很快的,所以很自然地,神经网络的研究者们马上对这种方案的可行性进行了研究,并得到了令人满意的结果 。以Johnson的文章作为代表进行总结。
文章:
Johnson, etc. Perceptual Losses for Real-Time Style Transfer and Super-Resolution
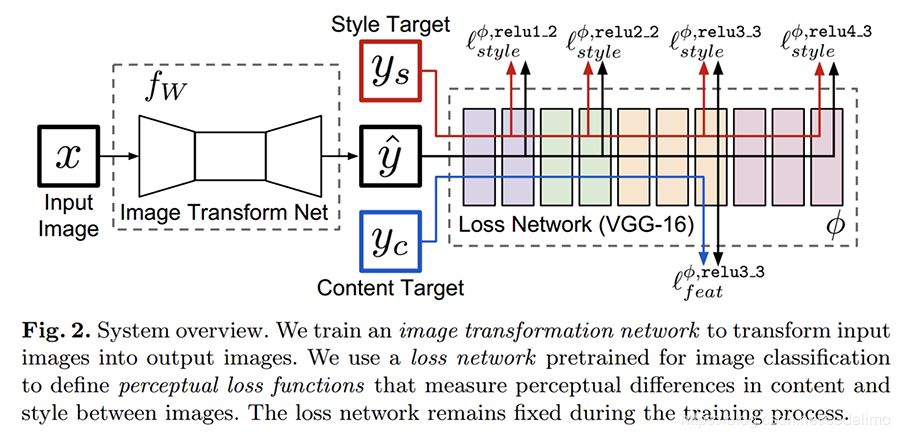
上图是来自原文的截图。 首先,他们将使用VGG 输出作为衡量距离的loss起了个正式名字,叫perceptual loss。其实在Gatys的方法中用的正是这种loss,只不过没有起名字。但后来的研究者就称这种loss叫perceptual loss。
这篇文章要完成的任务很明确,给定一幅图输入图x,网络一次前馈就能给出具有 风格的x。比较重要的一点是,这里网络的
风格的x。比较重要的一点是,这里网络的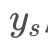 是固定的,也就是说,一旦网络训练好,无论输入x是什么,输出的所有图片都会被施以同一种风格变换。
是固定的,也就是说,一旦网络训练好,无论输入x是什么,输出的所有图片都会被施以同一种风格变换。
从架构图上看以看到,训练时输入图x经过一个变换网络得到一个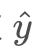 这里的变换网络是一个ResNet,变换网络的结构在这里并不重要,所以这里没有画出。后面通过两个loss来约束
这里的变换网络是一个ResNet,变换网络的结构在这里并不重要,所以这里没有画出。后面通过两个loss来约束
 之间通过vgg后的loss,这里要说下为什么会有
之间通过vgg后的loss,这里要说下为什么会有 的名字。在原文中,上面的架构图其实可以作两个用途,一个是风格转移,一个是单帧图片超分辨。用作风格转移的时,训练时
的名字。在原文中,上面的架构图其实可以作两个用途,一个是风格转移,一个是单帧图片超分辨。用作风格转移的时,训练时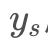 是x的高分辨图label,且此时
是x的高分辨图label,且此时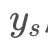
所以,在大量的x训练后,变换网络将学习到如何将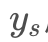 x
x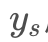
训练后,变换网络将学习到如何将y

总结一下这一阶段的研究,就是使用前馈的方式大大提升了风格转换的速度,但是引入了一个妥协:一个网络只能变换一种风格。很自然的问题,为什么不设计成xx和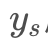 ys都是可变的, 直接前馈输出具有
ys都是可变的, 直接前馈输出具有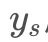 风格的 xx 的网络? 我觉得这种想法一定有人尝试过,但是这样的作法要求网络拟合的东西太多(不同的内容,不同的风格本质是对应的数据分布都不一样,所以要求网络在不同的数据分布上都得到好结果,也许这根本就不符合神经网络的理论模型),导致网络无法训练成功。但下面 Stage4 会讲到将x和
风格的 xx 的网络? 我觉得这种想法一定有人尝试过,但是这样的作法要求网络拟合的东西太多(不同的内容,不同的风格本质是对应的数据分布都不一样,所以要求网络在不同的数据分布上都得到好结果,也许这根本就不符合神经网络的理论模型),导致网络无法训练成功。但下面 Stage4 会讲到将x和 都可变的这一目标最终被完成了,得益于加入了一些人工的先验知识。
都可变的这一目标最终被完成了,得益于加入了一些人工的先验知识。
Stage3: fast, high quality IST
Stage2的工作将风格转移的迭代工作方式变为了前馈生成式,速度得到极大改善。但这种方法与Gatys迭代法产生的结果图的质量上有较大差距,毕竟Gatys方法可以按照loss函数实时逼近需求,而前馈网络一旦训练好则不可避免存在泛化能力的限制问题。所以如何在速度与质量较好地平衡? D.Ulyanov在这方面作了重要的推动(Stage2中也有他的重要工作,是基于GAN的思想)。他将传统前馈网络中的BatchNoramlization替换为InstanceNormalization,得到了高于Stage2的风格转移效果。
文章:
1.Instance Normalization: The missing ingredient for fast stylization
2.Improved Texture Networks: Maximizing Quality and Diversity in Feed-forward Stylization and Texture Synthesis
3.1 Instance Normalization (IN)
为了兼顾效率与准确度,batch训练是比较常用的一种训练方法,即一次从训练集空间中选择多个训练样本进行训练。Batch Normalization (BN)是Google的研究人员提出的一种神经网络训练技巧,它引入被证实可以有效抑制梯度消失,达到更好的训练效果,至少在分类网络中效果较明显。它的有效性在《Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift》中有详细实验。BatchNormalization是将一层网络的输出值重新分布,使其不至于过于集中,而且可以抑制由于网络随机初始值所造成的数值数量级的差别。它的算法为:

上图截取自Google研究人员发表的文章。其中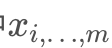 是batch中的样本在同一channel(或dimension的)的集合。注意最后数据在重分布后再施加一个线性拉伸和位移的操作,其参数是可训练的(γ与$\beta $)。所以BN是按batch、按channel为单位做归一化的数据重分布操作。 与BN相比,IN的算法数学表达基本一致,唯一不同的是,IN的操作单位是按样本、按channel为单位的。下图形象表示了BN与IN的区别:
是batch中的样本在同一channel(或dimension的)的集合。注意最后数据在重分布后再施加一个线性拉伸和位移的操作,其参数是可训练的(γ与$\beta $)。所以BN是按batch、按channel为单位做归一化的数据重分布操作。 与BN相比,IN的算法数学表达基本一致,唯一不同的是,IN的操作单位是按样本、按channel为单位的。下图形象表示了BN与IN的区别:

图中C为Channel, N为Batch, HW为高宽。
3.2 fast, high quality IST
为什么要提出IN ? Ulyanov没有说明提出的思想过程。以下是个人理解。在Stage1中,衡量一幅图风格的Gram矩阵表征一个样本在同一网络层不同 feature map之间的相似性,而BN是会在样本与样本之间串扰,和风格属性的独立性不兼容。而BN在分类网络中效果较好是因为它在不同样本间提取了不变的共性的东西,过滤了无关内容导致的分类变化,但这种思想对风格转移并不是太适用。IN归一化时只考虑自身的样本分布,可能对风格转移有提升作用。 Ulyanov利用Stage2中Johnson的工作中的网络结构进行了实验(即仅将原始网络中的BN替换为IN),并证实了这一点:

第一列是内容图,最后一列是风格图。 StyleNet是指Johnson的网络结构,由于其使用的归一化是BN,所以这里为了区分用StyleNet BN来指示, StyleNet IN是指保持其它结构不变,仅将BN换作IN的网络结构。 第四列是Gatys迭代法的结果(一般将其结果作为风格转移的最优结果来看待)。 可以看到IN的加入确实对风格转移网络的训练结果产生的明显正向的影响。
总结: 这个阶段将BN改为了IN,提升了风格转移的图片质量。但此阶段的网络依然是只能在特定的风格上进行转换,多个风格转换需要训练多个网络。 这里将IN单列为一个阶段是因为后面发现IN的内涵其实是丰富的,对风格转移作用巨大。
Stage4: fast, high quality, various IST
IN替换掉BN使得风格转换的质量提升,实验结论简单但其内在原理待人挖掘。这个阶段的工作对IN的作用进行了细致的研究。另外4.2的工作对Gatys方法的原理进行了探索,也得到好很有意义的结果。这些工作的互相启发最终达到了可以实现任意风格转移的网络。
4.1 Conditional Instance Normalization(CIN)
文章:
A learned representation for artistic style (Vincent Dumoulin, etc)
单一风格的风格转移网络虽然可以完成风格转移的任务,但占用空间大,N种风格需要准备N套全量网络参数。Dumoulin认为这种架构浪费了一些信息的内在联系。比如很多印象派画家的笔法其实是相似的,只是选色有区别。所以他认为各种风格之间是有一定的共享计算维度的。继续深入研究,他们发现了一个让人惊讶的现象: 仅仅通过IN层中 参数就足以对不同的风格建模! Domoulin没有介绍发现的过程,结论是直接给出的。
参数就足以对不同的风格建模! Domoulin没有介绍发现的过程,结论是直接给出的。
这个发现意味着:可以训练一个对多种风格进行转移的网络,网络结构中除IN层之外的参数皆为共享,而在IN层操作中只需根据目标风格选择其对应的 ,这种方法形象地被称作conditional instance normalization(CIN)。如下图:
,这种方法形象地被称作conditional instance normalization(CIN)。如下图:
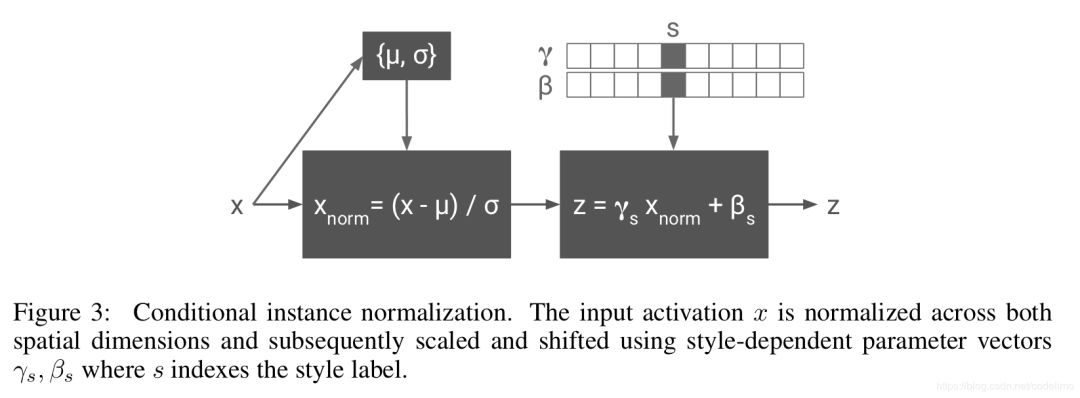
根据CIN的思想,很容易进行网络训练。Domoulin也利用上文Johnson的网络结构作相应的微小改动即进行了训练:1)预定N种风格图片,在训练时随机从内容图片与风格图片中选取作为训练输入; 2)网络的每个IN层有N套 γ 和$ \beta$ 训练参数,根据选择的风格只对相应的γ β进行训练更新,其它的γ β保持不变。
一个可以容纳N种风格的网络,假设其IN层操作的输入有C个通道,需要γ β数组个数为2NC个,这个数据量比起Stage2中训练NN套网络要小得多,大大节约了空间。使用CIN的风格转移效果如何呢? Domoulin在论文中的结论是与进行单一风格转移的网络效果相近。结果如下图:

上图是Domoulin从一个能够进行32种风格转换的网络中选出的5种展示。可见确实进行了风格转移,且效果明显。 还是应该提一下,与Stage2不同的是,上图中的图像都是一个网络产生的,对于不同的风格转移任务,仅仅从训练好的γβ组中选择相应的组作用到IN层即可。γ
ββ
4.2 variance and mean determines the style
文章:
Demystifying Neural Style Transfer, Yanghao Li, etc.
Li这篇文章的主旨是将风格转移任务看作是分布匹配(distribution alignment)任务,这是领域自适应过程(domain adaptation)的核心,所以领域自适应的知识可以拿过来分析风格转移问题。由此出发,文章同时对Gatys方法的原理也进行了研究。Li 经过推导发现将Gram矩阵匹配作为网络训练的目标等价于最小化“最大均值偏差” ( Maximum Mean Discrepancy, MMD)。 MMD在领域自适应中被用于衡量两个数据分布的距离,而风格本质就是一幅图的数据分布特点,所以也可以衡量风格的相似性,故Gram矩阵是有效的。这让我们从另一个维度看到了Gram矩阵的能力的原因所在。
文章另一个重要的点,也是与本小结密切相关的,是提出了用另一种风格度量来指导风格转移(文章一共给了4种指导风格转移的衡量方法,这里我们只关注其中的BN层分布匹配方法)。上面讲到,文章的基本出发点是将风格转移以领域自适应的方法作对比。文章认为风格转移就是域匹配,BN层的数据分布,即以$\mu $与σ表示的分布,就包有着“域”的信息,所以匹配此两者也可能匹配风格。于是Li做了实验,即:将Gatys方法中以Gram矩阵为匹配目标的 改为以μ和σ为匹配目标:
改为以μ和σ为匹配目标:

很显然,这样的loss将会迭代出一幅与风格图的每一层μ和σ都相近的合成图。下面是根据这种匹配规则的实验结果,确实也可以进行风格转移。
和σσ

但本文的重点在于研究风格转移任务的本质,而没有做一个任意风格转移的网络。其方法还是迭代的,在速率上自然也不是实时的。
4.3 arbitrary IST in one net
文章:
Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization, Xun Huang, etc.
受4.1和4.2的启发,Huang等人最终做了一个任意风格、前向实时转移的网络。
4.2的工作可以确认网络层的数据分布特征就是与风格密切相关,但Huang还是继续做了一些实验工作。在Stage3中,IN替换掉BN能提高风格转移的效果,Ulyanov给出的解释为IN层对不同的内容图片的对比度变化有鲁棒性。为了验证这种说法,Huang将应用IN到网络后的一些网训练细节数据做了实验。实验在Stage3文章2的网络结构上进行。结果比较图中 (a)的训练集是原始训练集;(b)的训练集是将原始训练集图片做了对比度统一预处理; © 是将原始训练集利用风格转移方法先进行了风格统一预处理(但不是统一到目标风格上),再进行训练。

可以看到,IN实际是比BN更快地降低风格loss,从而达到更好的训练效果,这种优势在(a)和(b)中都较明显,所以 Ulyanov的解释并不全对(由于对比度已经统一化,按照Ulyanov的解释此时应该没有明显收益)。 而更有趣的是,在风格统一化的图片集上,IN与BN对style loss的贡献差别变得很小。这可以理解为风格已经统一化后的训练数据已经在数据分布上没有太多可学习的东西,所以IN与BN效果差别不大。
既然已经发现一幅的风格与它经过卷积层后的数据分布(μ和σ)强相关,如何将这种信息利用起来得到一个可以转移任意风格的网络?首先,Huang提出了一种自适应重分布的nomalization方法(Adaptive Normalization,, 简称AdaIN):
与σσ
假设一幅内容图与风格图经过网络某层的输出为x和y,对应分布特征分别为为(μ(x),σ(x))(μ(x),σ(x)),(μ(y),σ(y))(μ(y),σ(y))。 则AdaIN的做法是:x
和yy

即:将内容图输出x重分布到风格图输出y的均值和方差上去。
这意味着什么?4.1和4.2中的工作已经提到,对μ和σ的变换就会导致风格的变换。AdaIN操作等价于直接将风格信息加到了内容图片的输出上去。但是这些风格信息与内容图纹理信息如何有机地结合恢复成最终的合成图?这还是未知的。为解决该问题,Huang给出了如下网络架构进行任意风格转移:
和μμ
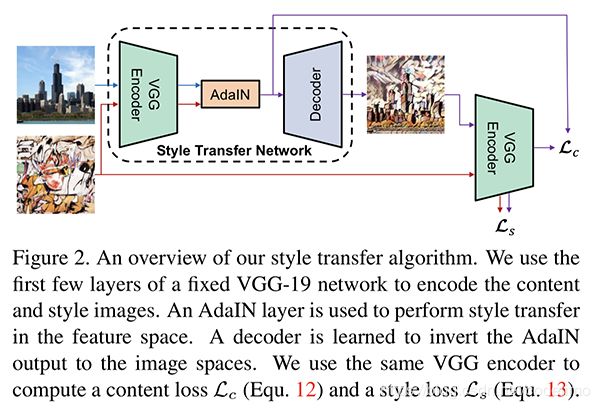
这里将VGG网络当作编码器使用。将内容图与风格图先经过VGG网络编码到feature map空间,接着将风格图的feature map的分布特点按照AdaIN的方法施加到内容图feature上去,得到一个兼有风格与内容的feature map。 之后该feature map经过解码器恢复成一张图。解码器正是为了解决如果有机结合风格信息与内容信息,所以是需要被训练的。网络最后,VGG再次被用作编码器是为了进行纹理和风格的loss计算。
下面就欣赏下该方案的效果吧:

图中同列同内容,同行同风格。
终于,一个网络,前向一次就可以搞定任意风格转移!
Extra: Set to Set style transfer
文章:
Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks, Junyan Zhu, etc.
这篇文章主要的思想其实是提出了一种新的GAN的工作方式,使用cycle-consistent约束避免普通GAN网络的模式单一化问题,下面称cycle-gan。
一般GAN网络的流程是源样本集X结过的生成器G生成假的目标集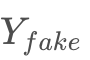 ,之后接一个判别器DD 用于鉴别真假目标集 YY和
,之后接一个判别器DD 用于鉴别真假目标集 YY和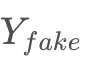 经过生成器与判别器多轮博弈训练,达到理想平衡的结果是GG生成的
经过生成器与判别器多轮博弈训练,达到理想平衡的结果是GG生成的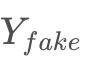 可以以假乱真。但这样的网络结构有模式单一化的风险,即任何来自XX的样本都生成相同的
可以以假乱真。但这样的网络结构有模式单一化的风险,即任何来自XX的样本都生成相同的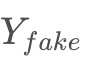
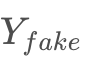 x∈X,生成的
x∈X,生成的
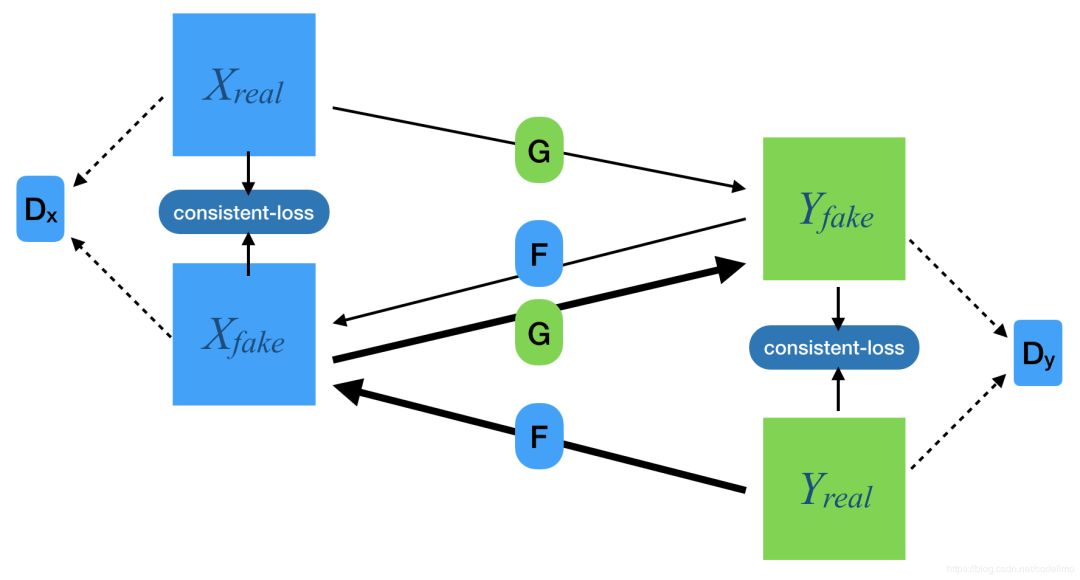
图中,G和F是生成器,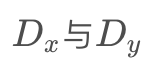 是判别器。可以看到,在cycle-gan中,有两个生成器、两个判别器。它们相互作用保证生成的图片以假乱真,且保证生成样本的多样性。架构中有两个转换循环:
是判别器。可以看到,在cycle-gan中,有两个生成器、两个判别器。它们相互作用保证生成的图片以假乱真,且保证生成样本的多样性。架构中有两个转换循环:
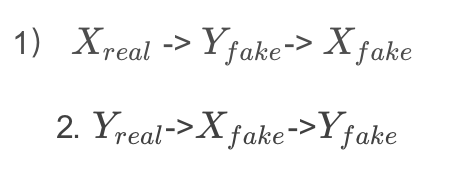
为了保证多样性,架构中加入了consistent-loss(如mse loss),比如一个样本x∈X,经过循环1后返回得到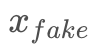 ,应该有 x==
,应该有 x==
cycle-gan能够达到的效果是将一个集合X中的样本变换后达到与另外一个集合Y 真假难辨的程度。所以它自然可以风格转移(但其用途远不止风格转移),比如我们将一些普通照片放在XX,将梵高的作品集放入YY中,则最终达到的效果是XX经过变换后的 YY集合, 这样
YY集合, 这样 μσ匹配法,cycle-gan的过程比较黑盒。X,
μσ匹配法,cycle-gan的过程比较黑盒。X,
Conclusion
本文回顾了从最笨重的Gram矩阵匹配迭代生成到任意风格前馈式风格的发展,这中间有一些偶然的发现使得任意风格前馈合成变为可能,有些许巧合但也有一定的理论解释。风格转移从最初的Gram矩阵指引到normalization层的μ和σ匹配,深刻了人们对图片中什么是“风格”什么是“内容”的认知。但是局限于深度学习的“可解释性”,我们对“风格”转移基本还是实验主义的。 神经网络的输出也一直被称为“feature”, 这是一个很抽象朦胧的名字。如何将一幅图的风格独立出来,也绝不会止于Gram矩阵和μμσσ的相似性,当我们对feature层的含义有更深层了解的时候,就会有更准确的对风格的刻化。
-
神经网络
+关注
关注
42文章
4842浏览量
108186
原文标题:一文读懂基于神经网络的图片风格转移
文章出处:【微信号:rgznai100,微信公众号:rgznai100】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
神经网络教程(李亚非)
卷积神经网络如何使用
【案例分享】ART神经网络与SOM神经网络
如何构建神经网络?
基于BP神经网络的PID控制
神经网络移植到STM32的方法
卷积神经网络模型发展及应用
图片风格转换算法简单介绍
神经网络如何识别图片的内容?



评论