 生成对抗网络 vs 图像水印,去除效果理想
生成对抗网络 vs 图像水印,去除效果理想

当前互联网飞速发展,越来越多的公司、组织和个人都选择在网上展示和分享图像。为了保护图像版权,大家都会选择在图像上打上透明或者半透明的水印。随着水印被广泛地使用,针对水印的各种处理技术也在不断发展,如何有效去除图像上的水印引发了越来越多人的研究兴趣。
今天的文章中,我们会介绍一种更为强大的水印去除器。这次我们借助生成对抗网络来实现,进一步提升水印去除器的性能,从而达到更为理想的去除效果。
生成对抗网络的前世今生
生成对抗网络(Generative Adversarial Networks,GAN),是由Ian Goodfellow等人在2014年首次提出。一般来说,生成对抗网络由两部分组成:生成器(Generator)和判别器(Discriminator)。生成器通过接收输入数据,学习训练数据的分布来生成目标数据。判别器通常是一个二分类模型,用来判别生成器生成数据的真假性。
我们可以将生成器和判别器看作互相对抗的双方,生成器的目的是令生成的数据尽可能的真实,让判别器无法区分真假;而判别器的目的是尽可能地识别出生成器生成的数据。在生成对抗网络的训练过程中,上面的对抗场景会持续进行,生成器和判别器的能力都得到了不断提升。训练的过程可以用如下公式表示:
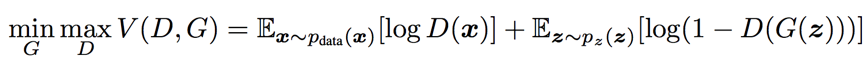
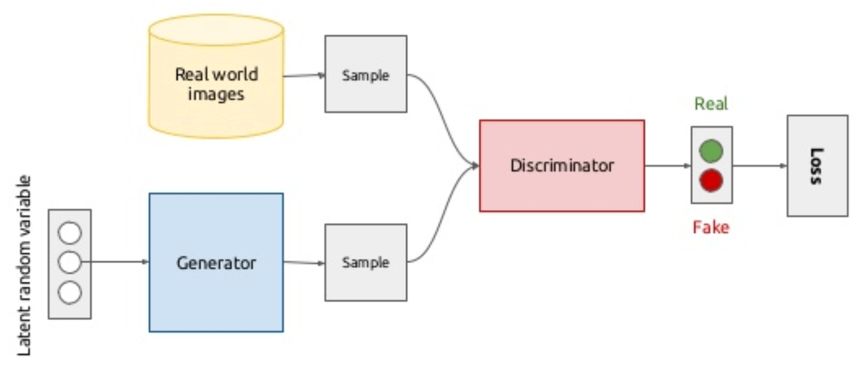
其中G和D分别表示生成器和判别器,x为真实数据,z是生成器的输入数据。最后训练结束我们就可以使用生成器来生成以假乱真的数据。一个直观的生成对抗网络结构如下图所示。
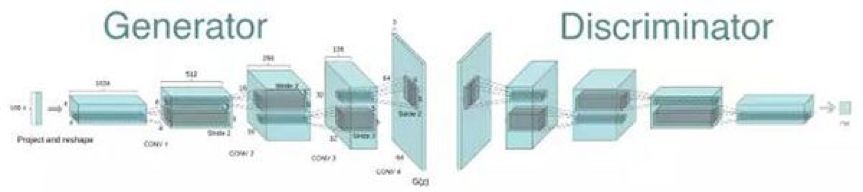
生成对抗网络近些年被大量应用于计算机视觉领域,根据具体应用不同可以分为图像生成和图像转换两种类型的任务。图像生成可以看成是一种学后联想任务,其中的代表是图像自动生成模型(DCGAN),网络结构如下图所示。这类任务只给出我们希望生成的目标图像,此时生成器的输入是服从某一分布的噪声,通过和判别器的对抗训练,将其转换成目标图像的数据分布。
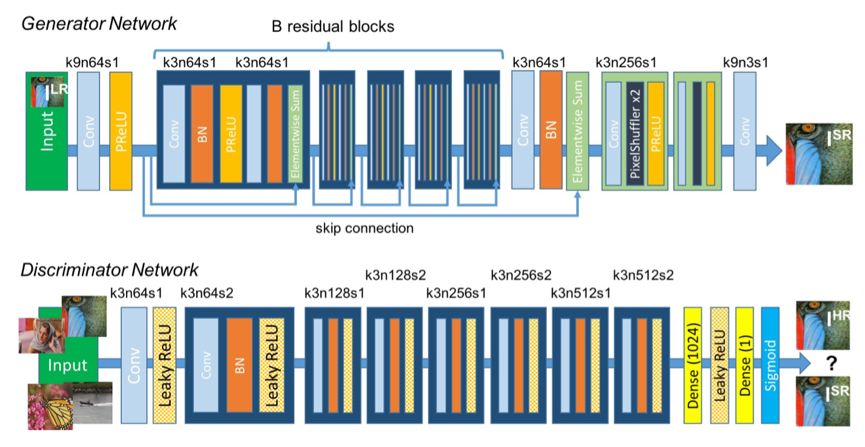
图像转换可以看成是一种目标引导任务,其中的代表是图像超分辨率模型(SRGAN),SRGAN的网络结构如下图所示。这类任务除了给出我们希望生成的目标图像外,还会给出转换前的原始图像,此时生成器的输入变为原始图像,生成器在和判别器的对抗训练过程中还要同时保证生成的图像和目标图像尽可能的相近。
生成对抗网络的发展非常迅速,近些年出现了各式各样GAN的变种,例如在训练上优化的WGAN和LSGAN,通过对输入添加条件限制来引导学习过程的Conditional GAN,图像生成任务中的BigGAN和StyleGAN,图像转换任务中的Pixel2Pixel和CycleGAN等等。期待未来生成对抗网络在计算机视觉领域给我们带来更多的惊喜。
生成对抗网络vs图像水印
上一节中我们介绍了生成对抗网络的核心思想和一些应用,现在我们尝试将生成对抗网络用于图像的水印去除。去水印的目的是将带水印的图像转变为无水印的图像,这本质上也是一种图像转换任务。
因此生成器的输入为带水印的图像,输出为无水印的图像;而判别器用于识别结果到底是原始真实的无水印图像,还是经过生成器生成的无水印图像。通过两者之间不断的对抗训练,生成器生成的无水印图像变得足够“以假乱真”,从而达到理想的去水印效果。
在实际的实践过程中,我们还做了一系列优化改进。下面我们分别介绍生成器和判别器的具体结构以及训练细节。在生成器的选择上,我们继续使用U-net网络结构,U-net通过在输入和输出之间添加跳跃连接,融合了低层级特征和高层级特征。与直接的编解码器结构相比,能够保留更多的图像背景信息,保证去除水印后的图像的真实性。
在判别器方面,我们使用了基于区域判别的全卷积网络。与传统的判别器直接输出整张图像的真假结果不同,我们通过对图像区域级别的判别,可以更好地对图像上的无水印和有水印部分进行区分。
此外,我们采用了Conditional GAN的思想,判别器在对原始真实的无水印图像和生成器生成的无水印图像进行区分的时候会加入带水印图像的条件信息,从而进一步提升生成器和判别器的学习性能。生成器和判别器的具体结构和细节如下图所示。
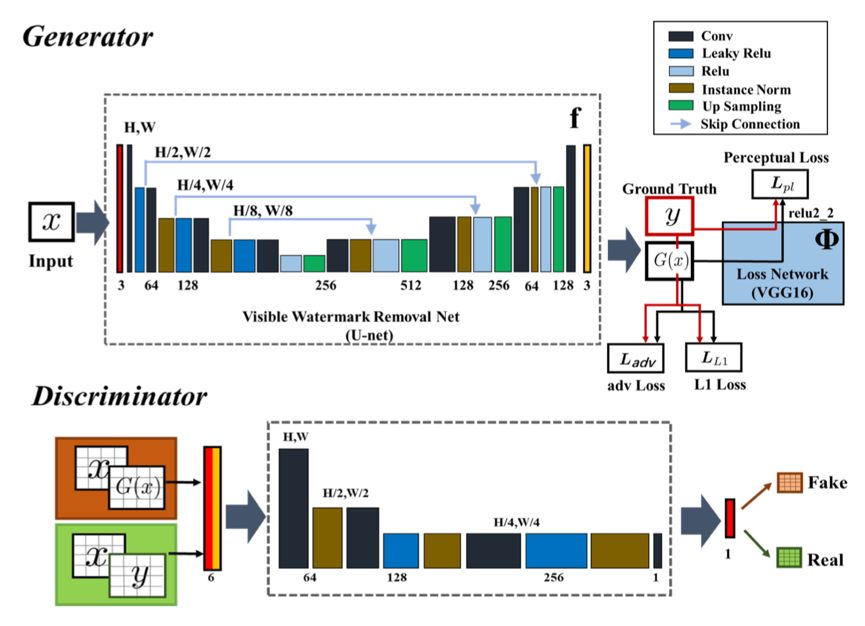
生成器生成的无水印图像除了要令判别器分辨不了真假之外,还需要保证和真实的无水印图像尽可能接近。为此我们组合一范数损失(L1 Loss)和感知损失(Perceptual Loss)作为内容损失,在生成器和判别器对抗的过程中加入训练。最终的损失函数为
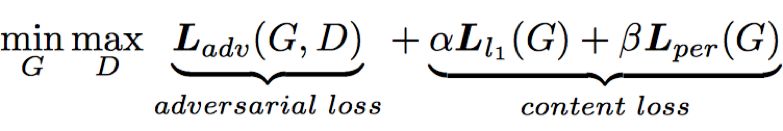
其中的条件对抗损失为
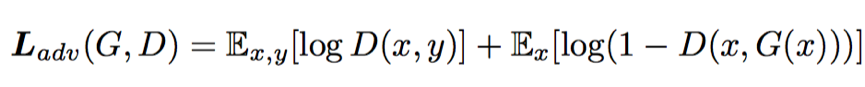
最终我们使用生成器作为水印去除器实现图像上的水印去除。为了对比和单一全卷积网络实现的水印去除器的效果,我们可视化了一些去水印结果,左列是输入的水印区域,中间列是单一全卷积网络得到的无水印区域,右列是生成对抗网络得到的无水印区域。从可视化的结果可以看出,经过对抗训练后的生成器对水印的去除效果更优。
写在最后
图像水印去除问题吸引了越来越多人的研究兴趣,本篇文章介绍了如何利用生成对抗网络来实现水印自动去除。去水印研究的目的是为了验证水印的鲁棒性,更好地提升水印的反去除能力。如何设计一种AI去不掉的水印是一个极具挑战的问题,接下来我们会在这方面做一些尝试,希望能够为版权保护尽一份力。
-
水印
+关注
关注
0文章
26浏览量
11880 -
GaN
+关注
关注
21文章
2396浏览量
85040
原文标题:基于GAN的图像水印去除器,效果堪比PS高手
文章出处:【微信号:rgznai100,微信公众号:rgznai100】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
探索 TDK-Lambda VS-E 系列单输出电源的卓越性能
GS4901B/GS4900B:视频与音频时钟及定时生成的理想之选
AD9547:网络时钟生成与同步的理想之选
探秘ICS841402I:PCIe与sRIO时钟生成的理想之选
CDC337时钟驱动器:高性能时钟分配与生成的理想选择
探索RC2121xA评估板:PCIe时钟生成的理想之选
使用Firebase AI Logic生成图像模型的两种新功能
清洗晶圆去除金属薄膜用什么

使用Simcenter STAR-CCM+进行拓扑优化:生成理想的增材制造设计,尽早满足工程要求

【Sipeed MaixCAM Pro开发板试用体验】基于MaixCAM-Pro的AI生成图像鉴别系统
理想汽车荣获汽车大模型安全证书
硅无光束肖特基二极管 - 成对和四成对 skyworksinc

HarmonyOS AI辅助编程工具(CodeGenie)UI生成
超声波清洗机对于微小毛刺的去除效果如何?




评论