 网络爬虫的基本工作流程
网络爬虫的基本工作流程

网络爬虫的基本工作流程
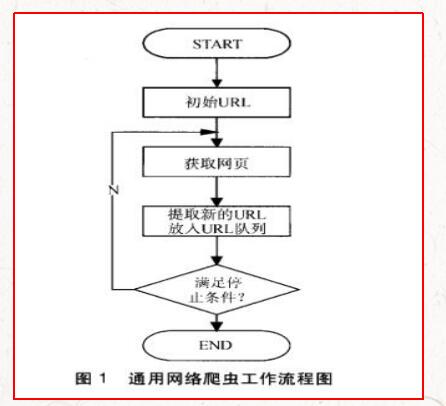
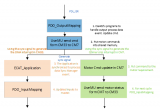
通用网络爬虫根据预先设定的一个或若干初始种子URL开始,以此获得初始网页上的URL列表,在爬行过程中不断从URL队列中获一个的URL,进而访问并下载该页面。页面下载后页面解析器去掉页面上的HTML标记后得到页面内容,将摘要、URL等信息保存到Web数据库中,同时抽取当前页面上新的URL,保存到URL队列,直到满足系统停止条件。其工作流程如图1所示。
主题爬虫工作流程
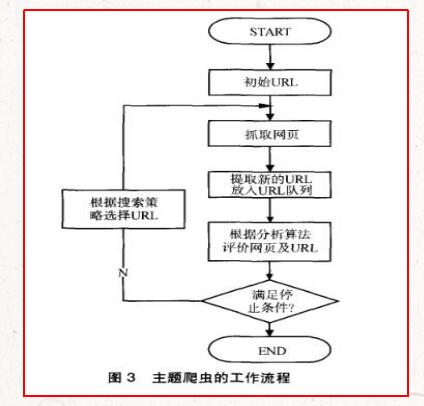
主题爬虫需要根据一定的网页分析算法,过滤掉与主题无关的链接,保留有用的链接并将其放入等待抓取的URL队列。然后,它会根据一定的搜索策略从待抓取的队列中选择下一个要抓取的URL,并重复上述过程,直到满足系统停止条件为止。所有被抓取网页都会被系统存储,经过一定的分析、过滤,然后建立索引,以便用户查询和检索;这一过程所得到的分析结果可以对以后的抓取过程提供反馈和指导。其工作流程如图3所示。
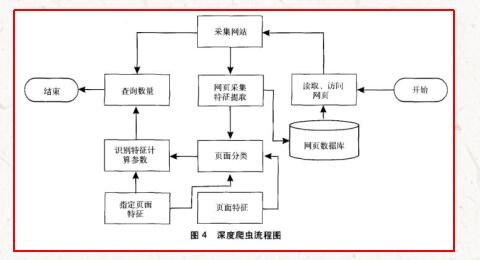
深度网络爬虫工作流程
1994年Dr.jillEllsworth提出DeepWeb(深层页面)的概念,即DeepWeb是指普通搜索引擎难以发现的信息内容的Web页面¨。DeepWeb中的信息量比普通的网页信息量多,而且质量更高。但是普通的搜索引擎由于技术限制而搜集不到这些高质量、高权威的信息。这些信息通常隐藏在深度Web页面的大型动态数据库中,涉及数据集成、中文语义识别等诸多领域。如此庞大的信息资源如果没有合理的、高效的方法去获取,将是巨大的损失。因此,对于深度网爬行技术的研究具有极为重大的现实意义和理论价值。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
网络爬虫
+关注
关注
1文章
52浏览量
9228 -
爬虫
+关注
关注
0文章
87浏览量
8242
发布评论请先 登录
相关推荐
热点推荐
原子吸收光谱仪原理详解:从光源到检测器,一文读懂AAS工作流程
原子吸收光谱仪(AAS)是分析化学中用于定量测定金属元素浓度的核心设备。其基本原理是:基态原子蒸气对同种元素空心阴极灯发射的特征谱线产生吸收,吸收程度与原子浓度成正比。理解AAS的工作流程,有助于更高效地开展重金属检测。

工作流节点说明---工作流节点
平台提供工作流节点,实现工作流嵌套工作流的效果。
节点说明
在一个工作流中,开发者可以将另一个工作流作为其中的一个步骤或节点,实现复杂任务
发表于 03-24 21:05
工作流插件节点节点说明
插件节点用于在工作流中调用插件运行指定工具。
插件是一系列工具的集合,每个工具都是一个可调用的API。插件广场上架的插件或已上架的团队插件支持以节点形式被集成到工作流中,拓展智能体的能力边界
发表于 03-23 16:54
工作流节点说明结束节点
结束节点是工作流的最终节点,用于返回工作流运行后的结果。结束节点支持两种返回方式:返回变量、返回文本。
返回变量
在返回变量模式下,工作流运行结束后会以JSON格式输出所有返回参数,适用于工作
发表于 03-16 16:43
工作流节点说明开始节点
开始节点是工作流的起始节点,用于设定启动工作流需要的输入信息。开始节点只有输入参数,没有输出等其他参数。开始节点中默认有一个输入参数USER_INPUT,一个默认的输入参数FILES_INPUT(非
发表于 03-13 14:52
开发工作流创建工作流
择要使用的节点。
2、将节点按任务流程相连接。
3、配置节点的输入和输出参数
测试并发布工作流
开发者如需在智能体内使用该工作流,必须先完成工作流的上架。
1、单击【试运行】,运行成功
发表于 03-10 10:05
AMS借助Altium Designer简化电子设计工作流程
随着时间的推移,AMS 遇到的问题越来越多。显然,AMS 需要一个设计解决方案,将他们的整个工作流程集成到一个统一的设计环境中。也就在这时,Altium 进入了他们的视野。
是德科技与三星携手英伟达展示端到端AI-RAN验证工作流程
是德科技(NYSE: KEYS )与三星电子宣布,会在巴塞罗那举行的2026年世界移动通信大会(MWC 2026)上,与英伟达联合演示端到端人工智能无线接入网络(AI-RAN)测试与验证工作流程。该
虚幻引擎5在建筑可视化中的应用:趋势、挑战与基于Perforce P4的工作流程
UE5正在重塑建筑可视化:实时交互、AI辅助、BIM联动......技术红利已来,工作流却拖了后腿?这篇干货解析了趋势和痛点,更揭秘了如何用Perforce P4打造高效的UE5工作流。

芯片ATE测试详解:揭秘芯片测试机台的工作流程
ATE(自动测试设备)是芯片出厂前的关键“守门人”,负责筛选合格品。其工作流程分为测试程序生成载入、参数测量与功能测试(含直流、交流参数及功能测试)、分类分档与数据分析三阶段,形成品质闭环。为平衡

# 深度解析:爬虫技术获取淘宝商品详情并封装为API的全流程应用
需求。本文将深入探讨如何借助爬虫技术实现淘宝商品详情的获取,并将其高效封装为API。 一、爬虫技术核心原理与工具 1.1 爬虫运行机制 网络爬虫
强强合作 西门子与日月光合作开发 VIPack 先进封装平台工作流程
平台开发基于 3Dblox 的工作流程。双方目前已经合作完成三项 VIPack 技术的 3Dblox 工作流程验证,包括扇出型基板上芯片封装(FOCoS)、扇出型基板上芯片桥接
ADI Power Studio工作流程与工具概述
、直观的工作流程,利用准确的模型来仿真实际性能,并自动生成关键的物料清单和报告等内容,帮助工程团队更早做出更优决策。
恩智浦i.MX RT1180跨界MCU驱动EtherCAT的工作流程
上周的分享已经介绍了整个参考设计的概况和相关硬件资源。那么,本次会从软件工程角度进行分享。首先来了解EtherCAT Slave工作流程。



评论