 谷歌大脑的“世界模型”简述与启发
谷歌大脑的“世界模型”简述与启发

摘要:我们的视觉看到什么,部分取决于大脑预测未来会看到什么。
我们的视觉看到什么,部分取决于大脑预测未来会看到什么,例如下图中,如果你预计要看到突出的球体,那也许你就会看到,如果让机器也具有了这样的能力,会带来什么了?
18年谷歌大脑提出“世界模型”(World Models)可以在复杂的环境中通过自我学习产生相应的策略,例如玩赛车游戏。
下面是世界模型的整体架构:

整个模型分为3个组件:视觉组件(V),记忆组件(M),控制组件(C)。视觉组件V用来压缩图片信息到一个隐变量z上(其实只是一个VAE编码解码器):
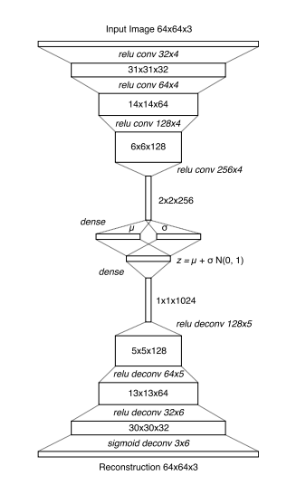
记忆组件M的输入是一帧帧的游戏图片(论文中的一帧图像似乎叫一个rollout),输出是预测下一帧图像的可能分布,其实就是比一般LSTM更高级一些的MDN-RNN:
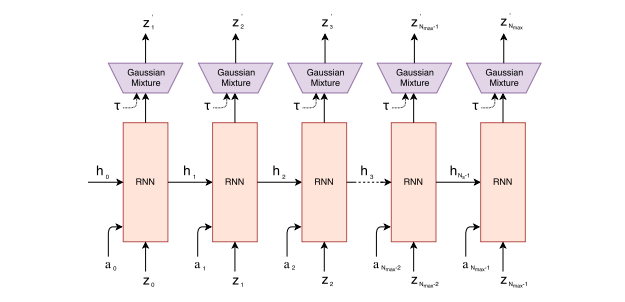
最后控制组件C的目标,就是把前面视觉组件V和记忆组件M的输出一起作为输入,并输出这个时刻智能体agent应该做出的动作(action)。
在所谓的“世界模型”,其中的组件模型几乎没有是谷歌大脑自己创新研制的。但世界模型会很大提高强化学习训练稳定性和成绩 从而使其与其他强化学习相比有一些明显优势,如下表所示;

世界模型有如下的3个特点
1. 模型拼接得足够巧妙,这个巧妙的拼接模型做到所谓的世界想象能力,就是模型在学习时,自身对环境假想一个模拟的环境,甚至可以在没有环境训练的情况下,自己想象一个环境去训练。其实就是我们人类镜像神经元的功能。

2. 抓住了一些“强视觉”游戏的“痛点”。记忆组件M中的RNN是生成序列的能手,所以根据之前游戏图像再“想象”一些图像帧应该不成问题(RNN生成一些隐变量z,再根据隐变量z,由视觉组件VAE的decode生成的图像帧即可)。所以对于“强视觉”的游戏,把RNN的记忆能力用在视觉预测和控制上是个好主意 。
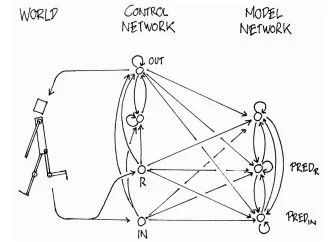
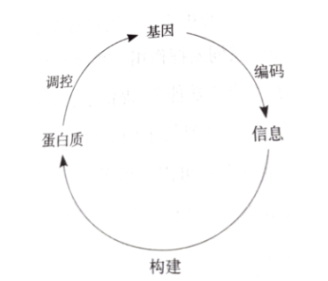
3不同于我们常见的“不可生”智能算法,例如遗传算法和进化策略只是强调了基因的“变异”与在解空间中进行搜索,神经网络只是固定网络结构;而生物界的基因却可以指导蛋白质构成并且“生长”。如果基因可以构造自身个体,外部环境和个体情况也可以反过来影响基因,而我们的模型都太固定呆板了,模型结构不能随内部隐变量改进,当然最佳的设计形式也许谁也不知道。而世界模型做到了让在内部”幻想“的环境中产生的策略转移到外部世界中。
最后简单看一下世界模型的训练过程:
world models代码基于chainer计算框架,步骤如下:
1. 准备数据集,随机玩游戏生成训练帧(rollouts意思应该就是多少帧):
python random_rollouts.py--gameCarRacing-v0 --num_rollouts10000
2. 训练视觉组件V,即前面提到的VAE:
python vision.py--gameCarRacing-v0 --z_dim32--epoch1
3. 训练记忆组件M,即前面提到的RNN:
python model.py--gameCarRacing-v0 --z_dim32--hidden_dim256--mixtures5--epoch20
4. 训练控制组件C,即前面提到的CMA-ES算法(其实就是支持更复杂输入和更新的ES):
python controller.py--gameCarRacing-v0 --lambda_64--mu0.25--trials16--target_cumulative_reward900--z_dim32--hidden_dim256--mixtures5--temperature1.0--weights_type1[--cluster_mode]
5. 测试训练结果:
python test.py--gameCarRacing-v0 --z_dim32--hidden_dim256--mixtures5--temperature1.0--weights_type1--rollouts100[--record]
-
谷歌
+关注
关注
27文章
6245浏览量
110269 -
机器
+关注
关注
0文章
796浏览量
41774 -
智能体
+关注
关注
1文章
390浏览量
11521
原文标题:谷歌大脑的“世界模型”简述与启发
文章出处:【微信号:AItists,微信公众号:人工智能学家】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
Gemini AI 再进化:谷歌联合XREAL发布Project Aura, 打开“看见世界”的新能力

利用NVIDIA Cosmos开放世界基础模型加速物理AI开发
谷歌AlphaEarth和维智时空AI大模型的核心差异
谷歌AlphaEarth和维智时空AI大模型的技术路径
谷歌DeepMind重磅发布Genie 3,首次实现世界模型实时交互
自动驾驶中常提的世界模型是个啥?
世界模型:多模态融合+因果推理,解锁AI认知边界
谷歌 Gemini 2.0 Flash 系列 AI 模型上新
英伟达推出基石世界模型Cosmos,解决智驾与机器人具身智能训练数据问题
华为、理想、特斯拉、商汤的世界模型是做什么用的

英伟达发布Cosmos世界基础模型
NVIDIA Cosmos世界基础模型平台发布
借助谷歌Gemini和Imagen模型生成高质量图像






 工商网监
工商网监
评论