 微软院士:Speech DDK技能太强了,语音识别超专业翻译人士水平
微软院士:Speech DDK技能太强了,语音识别超专业翻译人士水平

【导读】2016年152层残差网络图像识别精准率96%,2017年语音识别基准测试误差率5.1%,2018年1月文本理解测试精准率88.5%,3月机器翻译研究系统精准率达到69.9%,12月语音合成测试版在Azure正式上线,并首次达到超过专业翻译人士的水平,微软人工智能(AI)再次刷新世界纪录。
12月18日,在IoT In Action峰会上,微软全球资深院士首席语音科学家黄学东博士介绍智能语音和语言上的最新进展。首款媲美专业发音人的实时在线语音合成系统预览版在Azure上正式运营服务。
黄学东博士表示,微软在云服务上提供了世界级的语音合成服务,所有的互联网内容提供商都可以享受这个世界级的技术。它不仅解决了过去20年机器语音识别错误率居高不下的难题,更是人工智能语音和语言上的一次历史性突破——采用先进深度网络学习,简化了传统语音合成的架构。
从以上图片可以看出,左边紫色系统架构下,微软通过端到端的深度学习优化,为大家提供前所未有的、最自然的语音合成系统。
“基于神经网络的语音合成系统”是业界第一个实时的在语音上上线的人工智能服务。黄学东博士指出,大家可以享受更好的语音合成质量、更快的引擎性能、更广的全球服务部署。所有的内容提供商,不管是有没有音频、你的内容都可以转换成自然的声音表达,不管是在开车还是在睡觉,都可以享受高质量的交互。
同时,微软联合全球合作伙伴一起推出强大的语音麦克风阵列开发系统(Speech Devices SDK简称Speech DDK),它可以在25m之外都可以转写你的声音,DDK不仅可供用户免费使用,还可以整合到任何硬件设备中去,通过微软云服务为用户提供最先进的、世界一流的语音交互服务。
DDK让智能音箱“说话”。这是一款眼观六路的智能音箱系统,为企业级的会议转写提供前所未有的智能服务。
可以看到,它不仅仅是业界第一台多人原场会议转录系统,而且是业界第一台“睁开双眼”的智能音箱。
随着语音识别技术不断取得进步。放眼未来,各国间的语言沟通障碍不再有任何问题,人类离人工智能真正的目标又将推进一小步。
-
微软
+关注
关注
4文章
6753浏览量
108085 -
神经网络
+关注
关注
42文章
4842浏览量
108184 -
语音识别
+关注
关注
39文章
1825浏览量
116240 -
人工智能
+关注
关注
1820文章
50335浏览量
266976 -
语音合成
+关注
关注
2文章
94浏览量
16830
发布评论请先 登录
语音识别ic芯片分类工作原理,语音识别芯片分类

485AI语音识别模块:多路语音控制,实现安防设备语音联动
语音识别芯片介绍,语音识别芯片工作原理解析

语音识别芯片有哪些(语音识别芯片AT680系列)
什么是离线语音识别芯片(离线语音识别芯片有哪些优点)
语音识别系统的技术核心:从声音到文字的智能转换
声智科技出席2025年北京市多语种AI语音翻译大赛
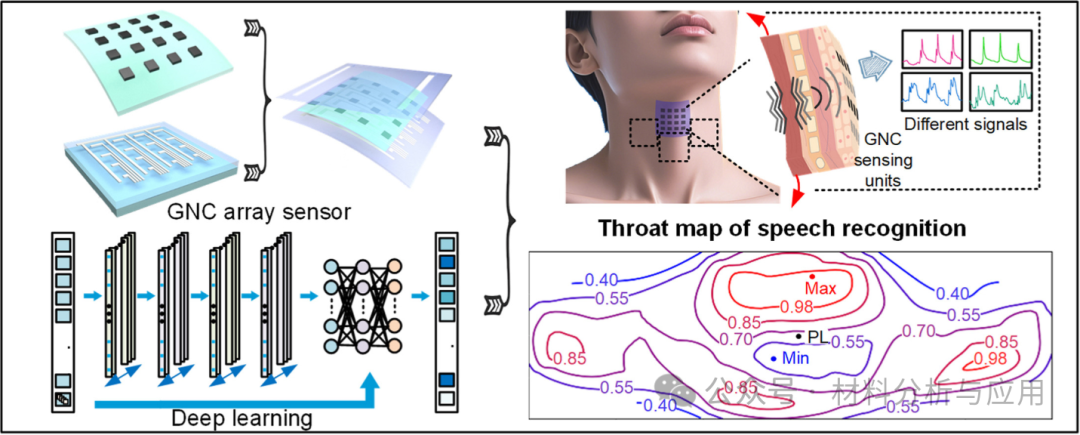
深圳大学:构建“喉部地图”法,柔性超灵敏碳阵列传感器,用于语音识别

广和通发布自研端侧语音识别大模型FiboASR
EASY EAl Orin Nano(RK3576) whisper语音识别训练部署教程

EASY EAl Orin Nano(RK3576) whisper语音识别训练部署教程



评论