 AI计算芯片现状,AI芯片创新与设计工具及生态之间的矛盾
AI计算芯片现状,AI芯片创新与设计工具及生态之间的矛盾

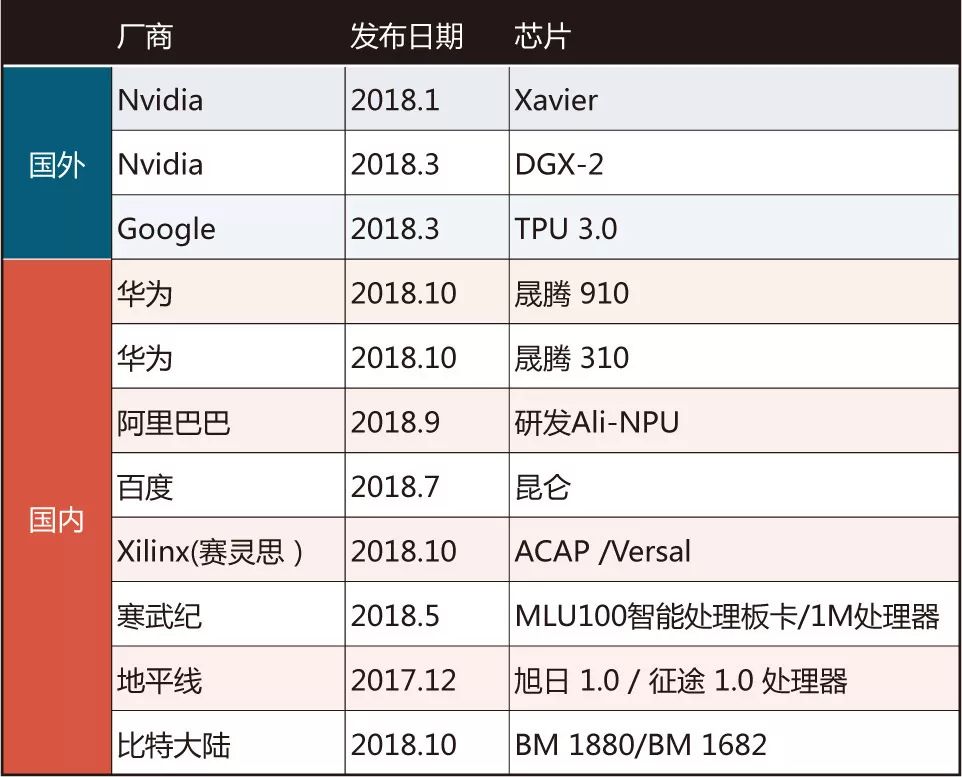
人工智能应用的蓬勃发展对算力提出了非常迫切的要求。由于摩尔定律已经失效, 定制计算将成为主流方向,因而新型的 AI 芯片开始层出不穷,竞争也日趋白热。参与这一竞争的不光是传统的半导体芯片厂商,大型的互联网和终端设备企业依托于自身庞大的应用规模,直接从自身业务需求出发,参与到 AI 芯片的开发行列。这其中以英伟达为代表的 GPU 方案已经形成规模庞大的生态体系,谷歌的 TPU 则形成了互联网定义 AI 芯片的标杆,其余各家依托各自需求和优势,提出了多类解决方案。本文将简要梳理目前各家技术进展状态,结合人工智能应用的发展趋势,对影响 AI 芯片未来发展趋势的主要因素做出一个粗浅探讨。
AI计算芯片现状
目前 AI 芯片领域主要的供应商仍然是英伟达,英伟达保持了极大的投入力度,快速提高 GPU 的核心性能,增加新型功能,保持了在 AI 训练市场的霸主地位,并积极拓展嵌入式产品形态,推出 Xavier 系列。互联网领域,谷歌推出 TPU3.0,峰值性能达到 100pflops,保持了专用加速处理器的领先地位。同时华为、百度、阿里、腾讯依托其庞大应用生态,开始正式入场,相继发布其产品和路线图。此外,FPGA 技术,因其低延迟、计算架构灵活可定制,正在受到越来越多的关注,微软持续推进在其数据中心部署 FPGA,Xilinx 和 Intel 俩家不约而同把 FPGA 未来市场中心放到数据中心市场。Xilinx 更是推出了划时代的 ACAP,第一次将其产品定位到超越 FPGA 的范畴。相较云端高性能 AI 芯片,面向物联网的 AI 专用芯片门槛要低很多,因此也吸引了众多小体量公司参与。
▌NVIDIA:Xavier
2018 年 1 月,英伟达发布了首个自动驾驶处理器——Xavier。这款芯片具有非常复杂的结构,内置六种处理器,超过 90 亿个晶体管,可以处理海量数据。Xavier 的 GMSL(千兆多媒体串行链路)高速 IO 将其与迄今为止最大阵列的激光雷达、雷达和摄像头传感器连接起来。
图:Xavier 的内部结构
▌NVIDIA:DGX-2
2018 年 3 月,NVIDIA 发布首款 2-petaFLOPS 系统——DGX-2。它整合了 16 个完全互联的 GPU,使深度学习性能提升 10 倍。有了 DGX-2 ,模型的复杂性和规模不再受传统架构限制的约束。与传统的 x85 架构相比,DGX-2 训练 ResNet-50 的性能相当于 300 台配备双英特尔至强 Gold CPU 服务器的性能,后者的成本超过 270 美元。
图:DGX-2 的内部结构
▌Google:TPU
自 2016 年首次发布 TPU 以来,Google 持续推进,2017 年发布 TPU 2.0,2018 年 3 月 Google I/O 大会推出 TPU 3.0。其每个 pod 的机架数量是TPU 2.0的两倍;每个机架的云 TPU 数量是原来的两倍。据官方数据,TPU 3.0 的性能可能是 TPU2.0 的八倍,高达 100 petaflops。

图:TPU 1 & 2 & 3 参数对比图
▌华为:晟腾 910 & 晟腾 310
2018 年 10月,华为正式发布两款 AI 芯片:昇腾 910 和昇腾 310。预计下一年第二季度正式上市。华为昇腾 910 采用 7nm 工艺,达芬奇架构,半精度(FP16)可达 256TeraFLOPS,整数精度(INT8)可达 512TeraOPS,自带 128 通道全高清视频解码器 H.264/265,最大功耗350W。华为昇腾 310 采用 12nmFFC 工艺,达芬奇架构,半精度(FP16)可达8TeraFLOPS,整数精度(INT8)可达 16 TeraOPS,自带 16 通道全高清视频解码器H.264/265,最大功耗 8W。
图:华为晟腾性能数据图
▌寒武纪:MLU100
2018 年 5 月,寒武纪推出第一款智能处理板卡——MLU100。搭载了寒武纪 MLU100 芯片,为云端推理提供强大的运算能力支撑。等效理论计算能力高达 128 TOPS,支持 4 通道 64 bit ECCDDR4 内存,并支持多种容量。1M 是第三代机器学习专用芯片,使用 TSMC 7nm 工艺生产,其 8 位运算效能比达 5Tops/watt(每瓦 5 万亿次运算)。寒武纪 1M 处理器延续了前两代 IP 产品(1H/1A)的完备性,可支持 CNN、RNN、SOM 等多种深度学习模型,此次又进一步支持了 SVM、K-NN、K-Means、决策树等经典机器学习算法的加速。这款芯片支持帮助终端设备进行本地训练,可为视觉、语音、自然语言处理等任务提供高效计算平台。
图:MLU 100 参数数据表
▌地平线:旭日 1.0 & 征程 1.0
2017 年 12 月,地平线自主设计研发了中国首款嵌入式人工智能视觉芯片——旭日 1.0 和征程 1.0。旭日 1.0 是面向智能摄像头的处理器,具备在前端实现大规模人脸检测跟踪、视频结构化的处理能力,可广泛用于智能城市、智能商业等场景。征程 1.0是面向自动驾驶的处理器,可同时对行人、机动车、非机动车、车道线交通标识等多类目标进行精准的实时监测和识别,实现 FCW/LDW/JACC 等高级别辅助驾驶功能。
▌比特大陆:BM1880 & BM1682
2018 年 10 月,比特大陆正式发布边缘计算人工智能芯片 BM1880,可提供 1 TOPS@INT8 算力。推出面向深度学习领域的第二代张量计算处理器 BM 1682,峰值性能达 3 TFLOPS FP32。
BM1682 VS BM1680 性能对比
BM1682 的算丰智能服务器SA3、嵌入式 AI 迷你机 SE3、3D 人脸识别智能终端以及基于 BM1880 的开发板、AI 模块、算力棒等产品。BM1682 芯片量产发布,峰值算力达到 3TFlops,功耗为 30W。
▌百度:昆仑芯片
2018 年 7 月,百度AI开发者大会上李彦宏正式宣布研发 AI 芯片——昆仑。这款 AI 芯片适合对 AI、深度学习有需求的厂商、机构等。借助着昆仑 AI 芯片强劲的运算性能,未来有望应用到无人驾驶、图像识别等场景中去。
▌阿里:研发 Ali-NPU、成立平头哥半导体芯片公司
2018 年 4 月,阿里巴巴达摩院宣布正在研发的一款神经网络芯片——Ali-NPU。其主要用途是图像视频分析、机器学习等 AI 推理计算。9 月,在云栖大会上,阿里巴巴正式宣布合并中天微达摩院团队,成立平头哥半导体芯片公司。
▌Xilinx:ACAP、收购深鉴科技
2018 年 3 月,赛灵思宣布推出一款超越 FPGA 功能的新产品——ACAP(自适应计算加速平台)。其核心是新一代的 FPGA 架构。10月,发布最新基于 7nm 工艺的 ACAP 平台的第一款处理器——Versal。其使用多种计算加速技术,可以为任何应用程序提供强大的异构加速。Versal Prime 系列和 Versal AI Core 系列产品也将于 2019 年推出。
2018 年 7 月,赛灵思宣布收购深鉴科技。
赛灵思ACAP框图
AI 芯片发展面临的矛盾、问题、挑战
目前AI芯片发展面临4大矛盾:围绕这些矛盾,需要解决大量相关问题和挑战。
▌大型云服务商与AI芯片提供商的矛盾
技术路线上,面向通用市场的英伟达持续推进 GPU 技术发展,但是大型云服务商也不愿陷入被动,结合自身规模庞大的应用需求,比较容易定义一款适合的 AI 芯片,相应的应用打磨也比较好解决。同时,新的芯片平台都会带来生态系统的分裂。但是对于普通用户,竞争会带来价格上的好处。由于 AI 算力需求飞速提升,短期内 AI 芯片市场还会进一步多样化。
▌中美矛盾
中国依托于庞大市场规模,以及 AI 应用技术的大力投资,非常有机会在 AI 相关领域取得突破。但是受到《瓦森那协议》以及近期中美贸易战等因素影响,中美在集成电路产业层面展开了激烈的竞争。AI 芯片有机会为中国带来破局的机会,因此后期可以预期,国内会有更多的资金投入到 AI 芯片领域。
▌专用与通用间的矛盾
云端市场由于各大巨头高度垄断,会形成多个相对封闭的 AI 芯片方案。而边缘端市场由于高度分散,局部市场难以形成完整的技术生态体系,生态建设会围绕主流核心技术拓展,包括ARM、Risc-V、NVDLA 等。各大掌握核心技术的厂商,也会迎合这一趋势,尽可能占领更大的生态份额,积极开放技术给中小企业开发各类 AI 芯片。
▌AI 芯片创新与设计工具及生态之间的矛盾
以 FPGA 为例,学界和业界仍然没有开创性的方法简化 FPGA 的开发,这是现阶段制约 FPGA 广泛使用的最大障碍。和 CPU 或 GPU 成熟的编程模型和丰富的工具链相比,高性能的 FPGA 设计仍然大部分依靠硬件工程师编写 RTL 模型实现。RTL 语言的抽象度很低,往往是对硬件电路进行直接描述,这样,一方面需要工程师拥有很高的硬件专业知识,另一方面在开发复杂的算法时会有更久的迭代周期。因此,FPGA 标榜的可编程能力与其复杂的编程模型之间,形成了鲜明的矛盾。近五到十年来,高层次综合(High Level Synthesis - HLS)一直是 FPGA 学术界研究的热点,其重点就是希望设计更加高层次的编程模型和工具,利用现有的编程语言比如 C、C++ 等,对 FPGA 进行设计开发。
在工业界,两大 FPGA 公司都选择支持基于 OpenCL 的 FPGA 高层次开发,并分别发布了自己的 API 和 SDK 等开发工具。这在一定程度上降低了 FPGA 的开发难度,使得 C 语言程序员可以尝试在 FPGA 平台上进行算法开发,特别是针对人工智能的相关应用。尽管如此,程序员仍然需要懂得基本的 FPGA 体系结构和设计约束,这样才能写出更加高效的 OpenCL/HLS 模型。因此,尽管有不少尝试 OpenCL/HLS 进行产品开发的公司,但是目前国内实际能够掌握这类设计方法的公司还是非常稀缺。各家专用 AI 芯片厂商,都需要建立自己相对独立的应用开发工具链,这个投入通常比开发芯片本身还要庞大,成熟周期也慢很多。Xilinx 对深鉴的收购有效补充了其在 AI 应用开发方面的工具短板。近期 Intel 开源了 OpenVINO,也是在推动其 AI 及 FPGA 生态。也有少数在 FPGA 领域有长期积累的团队,例如深维科技在为市场提供定制 FPGA 加速方案,可以对应用生态产生有效促进作用。
面对不同的需求,AI计算力最终将会驶向何方?
主要云服务商以及终端提供商都会围绕自家优势产品平台发展 AI 芯片,云端 AI 芯片投入巨大,主流技术快速进化,国内企业需要重视 AI 芯片的隐性投入:设计开发工具、可重用资源和生态伙伴。不过近期不大可能迅速形成整合的局面,竞争会进一步加剧。在端上,基于 DSA/RISC-V 的 AI 芯片更多出现在边缘端 AI+IoT,百花齐放。
三大类技术路线各有优劣,长期并存。
GPU 具有成熟的生态,在 AI 领域具有显著的先发优势,目前保持高速增长态势。
以 Google TPU 为代表的专用 AI 芯片在峰值性能上较 GPU 有一定优势。确定性是 TPU 另一个优势。CPU 和 GPU 需要考虑各种任务上的性能优化,因此会有越来越复杂的机制,带来的副作用就是这些处理器的行为非常难以预测。而使用 TPU 能轻易预测运行一个神经网络并得出模型与推测结果需要多长时间,这样就能让芯片以吞吐量接近峰值的状态运行,同时严格控制延迟。不过,TPU 的性能优势使得它的灵活性较弱,这也是 ASIC 芯片的常见属性。充分针对性优化的架构也可以得到最佳的能效比。但是开发一款高性能专用芯片的投入是非常高昂的,通常周期也需要至少 15 个月。
FPGA 以及新一代 ACAP 芯片,则具备了高度的灵活性,可以根据需求定义计算架构,开发周期远远小于设计一款专用芯片。但是由于可编程资源必不可少的冗余,FPGA 的能效比以及价格通常比专用芯片要差很多。但是 ACAP 的出现,引入了 AI 核的优点,势必会进一步拉近与专用芯片的差距。随着 FPGA 应用生态的逐步成熟,FPGA 的优势也会逐渐为更多用户所了解。
总而言之,AI 芯片的“战国时代”大幕已经拉开,各路“诸侯”争相割据一方,谋求霸业,大家难以独善其身,合纵连横、百家争鸣将成为常态。这也必定会是一个英雄辈出的时代。
-
处理器
+关注
关注
68文章
20333浏览量
255044 -
自动驾驶
+关注
关注
794文章
14990浏览量
181557 -
AI芯片
+关注
关注
17文章
2165浏览量
36869
原文标题:AI芯片的“战国时代”:计算力将会驶向何方?
文章出处:【微信号:rgznai100,微信公众号:rgznai100】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录



评论