 NVIDIA软件可选服务支持数据中心集群管理
NVIDIA软件可选服务支持数据中心集群管理

这项可选服务将帮助数据中心运营商监测整个 AI GPU 集群运行状况,从而最大限度地延长正常运行时间。
随着 AI 基础设施的规模和复杂性不断增加,数据中心运营商需要持续了解性能、温度和功耗等因素。这些洞察使数据中心运营商能够主动监测和调整大规模分布式系统中的数据中心配置,从而确保这些系统以最高效率和可靠性运行。
NVIDIA 正在开发用于可视化和监测 NVIDIA GPU 集群的软件解决方案,为云合作伙伴和企业提供洞察仪表板,帮助他们提高整个计算基础设施的 GPU 正常运行时间。
该服务由客户选择、自行安装和控制,用于监测 GPU 使用情况、配置和错误。它将包含一个开源客户端软件智能体,这是 NVIDIA 持续支持开放、透明软件的一部分,旨在帮助客户最大限度的发挥其 GPU 系统的性能。
通过这项服务,数据中心运营商将能够:
追踪功耗峰值,在不超出能耗预算的前提下最大化单位功耗性能。
监测整个集群的利用率、内存带宽和互连运行状况。
及早发现热点和气流问题,以避免过热降频和组件过早老化。
确认软件配置和设置一致,以确保结果可复现以及运行可靠。
发现错误和异常情况,及早发现故障部件。
这些功能可以帮助企业和云提供商可视化其 GPU 集群、解决系统瓶颈并优化生产力,从而提高投资回报。
此可选服务提供实时监测,让每个 GPU 系统与外部云服务通信和共享 GPU 指标。NVIDIA GPU 没有硬件跟踪技术、终止开关和后门。
开源智能体为数据中心所有者提供洞察
该服务将配备客户端软件智能体,客户可以安装该智能体,将节点级 GPU 遥测数据流式传输到托管在NVIDIA NGC的门户网站上。客户可以在仪表板中可视化其 GPU 集群利用率,既可以全局查看,也可以按计算区域 (在同一物理或云位置注册的节点组) 查看。
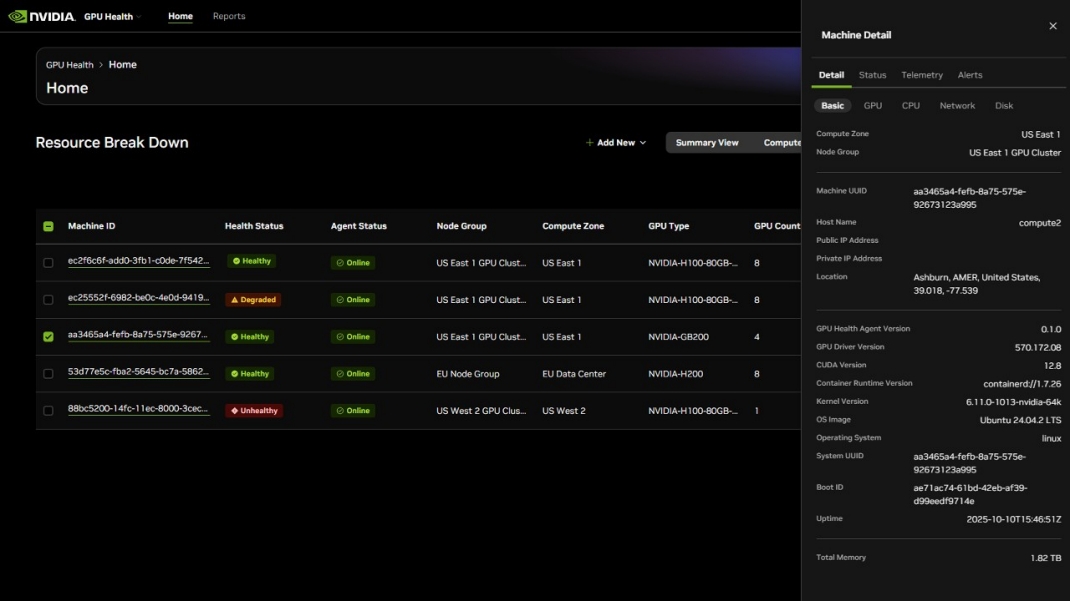
仪表盘可展示客户全球 GPU 集群的整体状态洞察。
该客户端工具智能体也计划开源,以提供透明度和可审计性。它将提供一个实际示例,展示客户如何将 NVIDIA 工具整合到他们自己的 GPU 基础设施监测解决方案中,无论是用于关键计算集群,还是整个 GPU 集群。
该软件能够帮助企业了解其 GPU 库存情况,但无法修改 GPU 配置或底层运行机制。它提供的是只读遥测数据,并由客户自行管理及自定义。
该服务还支持客户生成详细介绍 GPU 集群信息的报告。
随着 AI 应用的数量和复杂性不断增加,现代 AI 基础设施管理也在不断发展以适应这一趋势。AI 正在重塑各行各业以及各种应用,因此确保 AI 数据中心保持最佳状态运行至关重要。这项软件服务正是为此而生。
-
NVIDIA
+关注
关注
14文章
5729浏览量
110303 -
gpu
+关注
关注
28文章
5329浏览量
136228 -
数据中心
+关注
关注
18文章
5853浏览量
75255
原文标题:NVIDIA 软件可选服务支持数据中心集群管理
文章出处:【微信号:NVIDIA_China,微信公众号:NVIDIA英伟达】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
借助NVIDIA产品扩展AI就绪型数据中心


跳线架在数据中心的应用与优化策略
青智ZW3432B1数据中心电源管理系统监控方案

提高数据中心效率:探索PDU的作用
KubePi:开源Kubernetes可视化管理面板,让集群管理如此简单

构建高可靠的数据中心零配置带外管理体系




评论