 分块延迟渲染架构能否在桌面领域立足?
分块延迟渲染架构能否在桌面领域立足?

Imagination的PowerVR GPU架构始终是高效能的代名词。我们的IP技术在移动设备、消费电子及其他嵌入式领域奠定了声誉,这些领域的SoC设计方案往往需要优先考虑电池续航与芯片面积。
然而在桌面市场,显卡所需的GPU IP要求则大不相同:
高性能:主流显卡需达到20 TFLOPS算力与300GPixel/s渲染能力方能立足;高端游戏显卡的性能标准更为严苛
先进特性:超分辨率等AI增强功能渐成标配,GPU更成为生成式AI革命的关键推动力
软件兼容:必须通过硬件级DirectX支持流畅运行Windows平台游戏
能效控制:即便在桌面领域,能效同样至关重要,用户期待低散热、静音运行的设备。
近年来,Imagination通过增加主GPU核心内处理单元数量,结合领先的多核扩展技术,已助力桌面领域客户实现主流级性能目标。
我们常被问及:在长期被即时渲染架构(IMR)主导的桌面领域,分块延迟渲染架构(TBDR)是否真的能胜任?
答案是肯定的。事实上这两种架构风格的差异并不如想象中巨大。接下来我们将深入解析其实现原理。
回归基础:传统3D渲染的简化数据流
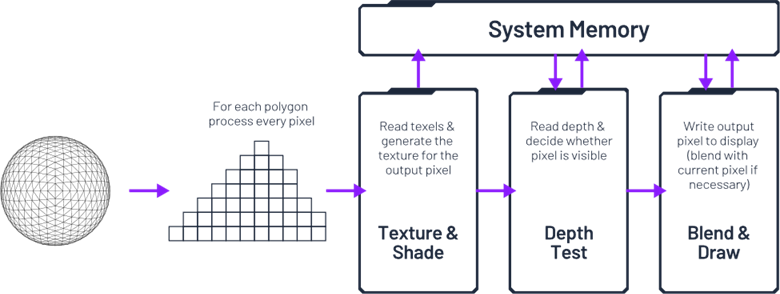
在3D图形处理中,每个提交给渲染器的对象都会在下一个对象被处理之前立即完成变换、光栅化和着色。这正是“即时模式渲染(immediate mode rendering)”这一名称的由来。
当然,在3D场景中,远离摄像机的物体可能(完全或部分)被前景物体遮挡。如果在"纹理与着色"步骤之后才执行深度测试,那些已经处理过的像素片段很可能被更靠近摄像机的三角形/像素片段所"覆盖重绘"。这会导致着色器执行不必要的计算工作,同时引发大量冗余(且高功耗)的数据传输。所有颜色和深度数据都存储在系统内存中,处理颜色混合和深度缓冲区更新时频繁的读取/修改/写入操作,将产生巨大的内存带宽开销,或者需要配备超大容量的L2/L3缓存。
在芯片面积和功耗限制较少的设备上,这种程度的资源浪费尚可接受,但对智能手机等资源受限的环境却并不适用。这正是Imagination分块延迟渲染技术展现价值的领域。
第一节:桌面系统中的分块渲染
认识Imagination的分块渲染技术
基于分块延迟渲染(TBDR)架构中的分块处理发生在渲染管线早期,具体位于几何处理阶段。该阶段通过处理顶点数据,将整个场景划分为若干称为"图块"的独立区域。这种分块机制使得芯片内缓存可以替代高成本的系统内存往返数据传输。分块技术还能优化工作负载分配——由于每个图块相互独立,可在不同核心或着色单元间并行处理。与传统即时渲染(IMR)架构按三角形处理的方式不同,这种方式可实现性能的线性扩展。另一关键优势在于:每个图块的数据量极小,使得整个处理流程可完全在芯片内完成,每个图块仅需执行单次写回操作。
Imagination GPU专属分块优化技术
Imagination拥有三项降低内存带宽、实现极致功耗控制的核心分块技术:
Imagination GPU将三角形精确归类至对应图块,确保计算资源仅用于必要区域。多数厂商采用边界框(bounding boxes)方案,因数据过量提取可能导致工作量翻倍——而采用分层图块划分的GPU情况甚至更糟。
2.精准剔除(Perfect Culling)
我们拥有多项早期剔除技术专利,涵盖微对象剔除、深度剔除等创新领域,以及传统离屏剔除和背向三角形剔除等成熟方案。
3.几何压缩(Geometry Compression)
我们的GPU是唯一采用硬件级几何压缩技术的产品。该技术能在顶点数据(包括位置坐标、法线向量、纹理坐标等)存储或传输前进行压缩,通过减小顶点缓冲区尺寸来降低内存带宽需求。GPU在顶点处理过程中实时执行数据压缩,从而实现内部缓存的高效利用,减少外部内存访问频次。
这些技术共同保障了即使在桌面级设备上,GPU也能在提供游戏及生产力应用所需性能的同时,保持卓越能效与低噪音运行。
那么分块渲染虽高效,其与桌面软件的兼容性如何?主流桌面API(OpenGL与DirectX)及游戏引擎均已支持分块渲染。基于分块延迟渲染的管线前端(在分块处理阶段之前)与经典即时渲染架构并无差异。值得注意的是,现代即时渲染架构也已发展出自身的分块方案:例如英伟达GPU配备分块缓存(tiled caching)技术,AMD GPU则提供"绘制流分档光栅化器"(Draw Stream Binning Rasterizer)。
Imagination GPU与AMD/英伟达方案的核心区别在于:即时渲染架构通过片上缓存(而非系统内存)实现其"分块"处理。但这并非桌面客户的障碍——我们的GPU可配置为将分块数据与几何数据存储于片上内存(SRAM),从而降低延迟并减少外部DDR带宽占用。未默认采用此设计是因它会增加芯片面积,这对嵌入式细分市场的成本敏感型合作伙伴难以接受。
本质上,分块渲染器与即时渲染器已呈现技术融合:即时渲染器通过引入分块机制提升能效与处理效率。因此,关于分块渲染器软件兼容性的挑战已不复存在,相关历史论断实属过时且具有误导性。
Imagination 桌面级 GPU优化方案
面向嵌入式市场的经典Imagination GPU专注于面积效率,因为在嵌入式市场,GPU的芯片面积预算通常有限,也无法负担支持几何图块划分所需的更大片上缓存。这与桌面市场不同,桌面市场普遍拥有巨大的缓存,例如AMD的Infinity Cache最高可达128MB。
在桌面市场使用Imagination GPU IP的客户可以进行以下调整,以适应桌面环境:
允许将参数/图块缓冲区映射到任意内存区域(而不仅限于系统内存)。
将缓冲区限制为特定的、较小的尺寸。
启用"智能参数管理"(SPM)功能,允许硬件刷新部分图块渲染数据以释放片上参数存储空间,代价是会降低隐藏面消除效率(例如已刷新的工作负载后续可能被其他物体遮挡)。
如有需要,可将数据溢出到系统内存。
第2节:桌面端的延迟渲染
了解Imagination的延迟渲染
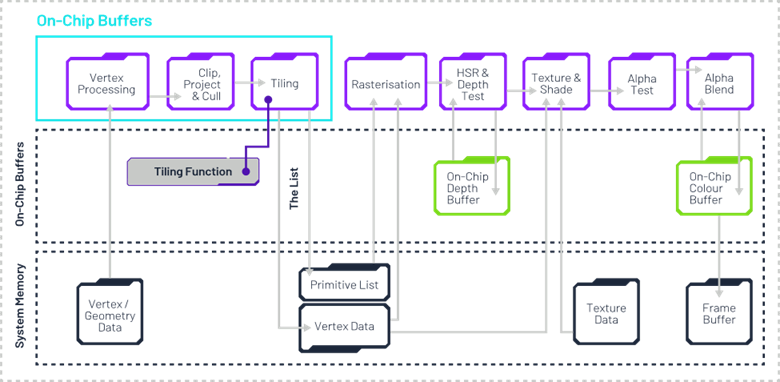
如前所述,即时渲染模式在处理场景对象时,会立即进行变换、光栅化和着色,而不会预先判断哪些对象在屏幕上是可见的。
除了分块技术,Imagination GPU还采用延迟渲染方案。该技术在片段处理阶段初期引入深度测试,主动检测并剔除被遮挡的三角形。完成此步骤后,渲染管线才会执行纹理贴图与着色计算。这种"按需渲染"的技术路径有效降低了计算负载、内存带宽及功耗消耗。
其运作流程如下:
提取每个图块,仅根据位置数据对变换后的几何体进行光栅化
隐藏面消除(HSR)阶段通过片上缓冲区判定可见片段
片段处理阶段负责获取属性与纹理数据
像素处理阶段运行像素着色器代码,实施逐像素光照等着色技术,所有混合操作均在片上图块内存完成,避免片外读写
通过将片上缓冲区数据写入内存,逐块完成最终3D帧渲染
延迟渲染与桌面软件的兼容性如何?
延迟渲染对软件完全透明,且完全符合现代API规范。采用延迟渲染方案不会造成任何功能限制,其影响仅体现在GPU内部操作层面。
究其本质,延迟渲染实质上是乱序深度计算的一种实现形式。英伟达与AMD采用的Early-Z技术正是同类方案,其他厂商类似的解决方案还包括前向像素消除(Forward Pixel Kill)、片段预渲染(Fragment Pre-Pass)等。因此乱序深度测试具有广泛兼容性,完全不会与桌面API产生冲突。
结语:效率与性能的完美结合
正如本文所见,即时渲染模式与基于分块的延迟渲染GPU的主要区别在于可见性测试的时机、颜色/深度数据的存储位置以及对L2缓存的要求。在设计初衷上,基于分块的延迟渲染GPU更侧重于提升系统效率,减少芯片内部的数据移动。
但两种渲染架构的差异并不如许多人设想的那般悬殊。现代即时渲染器已吸纳分块渲染与早期深度测试等技术来优化工作负载分配与处理效率。与此同时,Imagination的GPU IP具备充分灵活性,桌面市场客户可根据实际需求进行针对性调整。
这些架构层面的相通之处,使得高性能分块延迟渲染GPU成为现代桌面系统的理想选择。无论是游戏娱乐、内容创作还是AI增强应用,Imagination GPU都为传统即时渲染架构提供了面向未来的替代方案。
了解更多关于适用于桌面领域的Imagination GPU系列产品信息,请访问Imagination官方网站。
英文链接:https://blog.imaginationtech.com/does-tile-based-deferred-rendering-have-a-place-in-desktop
声明:本文为原创文章,转载需注明作者、出处及原文链接。
-
gpu
+关注
关注
28文章
5283浏览量
136094 -
渲染
+关注
关注
0文章
80浏览量
11405 -
imagination
+关注
关注
1文章
624浏览量
63502
发布评论请先 登录
2026国产工控机十大品牌盘点 自主架构成选型硬指标

松盛光电桌面式高精密激光锡球焊接系统的应用领域
昆仑天工Skywork与Google Cloud深度合作发布桌面级Agent
进迭时空 Bianbu LXQt | 全新流畅轻桌面!

探索RISC-V在机器人领域的潜力
逐点半导体分布式渲染解决方案助力真我GT8系列电竞独显芯片R1性能跃升
详解ROMA中复杂图表的渲染实现
延迟脉冲信号发生器在激光触发领域的应用
从 CPU 到 GPU,渲染技术如何重塑游戏、影视与设计?

知乎开源“智能预渲染框架” 几行代码实现鸿蒙应用页面“秒开”
在TR组件优化与存算一体架构中构建技术话语权
通道渲染:释放渲染的全部潜能!通道渲染的作用、类型、技巧
无限穿墙技术西安品茶工作室南郊北郊教学简约网络延迟
“立足STCO集成系统设计” 芯和半导体在DAC上发布EDA2025软件集

GPU架构深度解析



评论