 使用NVIDIA NVLink Fusion技术提升AI推理性能
使用NVIDIA NVLink Fusion技术提升AI推理性能

AI 模型复杂性的指数级增长驱动参数规模从数百万迅速扩展到数万亿,对计算资源提出了前所未有的需求,必须依赖大规模 GPU 集群才能满足。混合专家(MoE)架构的广泛应用以及测试时扩展(test-time scaling)在推理阶段的引入,进一步加剧了计算负载。为实现高效的推理部署,AI 系统已发展出大规模并行化策略,包括张量并行、流水线并行和专家并行等技术。这些需求推动了支持内存语义的纵向扩展(Scale-up)计算网络向更大的 GPU 域演进,构建统一的计算与内存资源池,实现高效协同。
本文详细阐述了NVIDIA NVLink Fusion如何借助高效可扩展的 NVIDIA NVLink scale-up 架构技术,满足日益复杂的 AI 模型不断增长的需求。
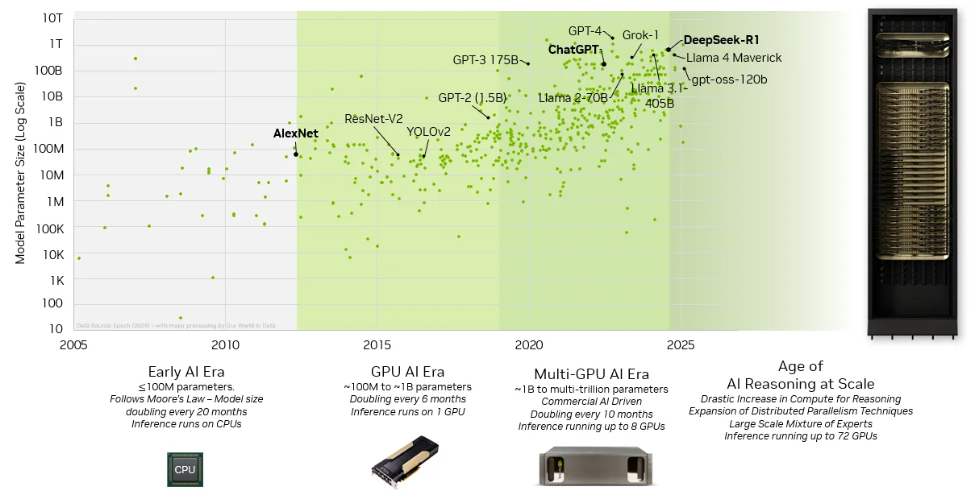
图 1:模型规模与复杂性的提升推动了 scale-up 域的扩展
NVLink 如何持续演进以满足不断增长的 scale-up 需求
NVIDIA 于 2016 年首次推出 NVLink,旨在克服 PCIe 在高性能计算和人工智能工作负载中的局限性。该技术实现了更快的 GPU 间通信,并构建了统一的内存空间。
2018年,NVIDIA 推出了 NVLink Switch 技术,实现了在 8 个 GPU 的网络拓扑中每对 GPU 之间高达 300 GB/s 的 all-to-all 带宽,为多 GPU 计算时代的 scale-up 网络奠定了基础。随后,在第三代 NVLink Switch 中引入了 NVIDIA 可扩展分层聚合与归约协议(SHARP)技术,进一步提升了性能,有效优化了带宽性能并降低了集合操作的延迟。
随着 2024 年第五代 NVLink 的发布,进一步增强的 NVLink Switch 支持 72 个 GPU 实现全互联通信,通信速率达 1800 GB/s,聚合总带宽高达 130 TB/s,较第一代产品提升了 800 倍。
尽管 NVIDIA 已大规模部署 NVLink 近十年,但仍在不断突破技术极限,对未来三代的 NVLink 产品,会保持每年推出一代的节奏。这一迭代策略推动了持续的技术进步,有效满足了 AI 模型在复杂性和计算需求方面的指数级增长。
NVLink 的性能取决于硬件和通信库,尤其是 NVIDIA 集群通信库(NCCL)。
NCCL 作为一个开源库,专为加速单节点和多节点拓扑中 GPU 之间的通信而设计,能够实现接近理论带宽的 GPU 到 GPU 通信性能。它无缝支持横向和纵向扩展,具备自动拓扑感知与优化能力。NCCL 已集成到所有主流深度学习框架中,历经 10 年的开发与 10 年的生产环境部署,技术成熟且广泛应用。

图 2:NCCL 支持纵向扩展和横向扩展,在所有主流框架中均受支持
最大化 AI 工厂收入
NVIDIA 在 NVLink 硬件和软件库方面积累了丰富的经验,配合大规模的计算域,能够有效满足当前 AI 推理计算的需求。其中,72-GPU 机架架构在多种应用场景中实现了卓越的推理性能,发挥了关键作用。在评估大语言模型(LLM)推理性能时,前沿帕累托(Frontier Pareto)曲线清晰地展现了每瓦吞吐量与延迟之间的权衡关系。
AI 工厂的生产和收入目标是最大化曲线下的面积。影响该曲线动态的因素众多,包括原始算力、内存容量与吞吐量,以及 scale-up 技术,通过高速通信优化实现张量并行、流水线并行和专家并行等技术。
在检查各类 scale-up 配置的性能时,我们发现存在显著差异,即使是使用相同的 NVLink 速度。
在 4 个 GPU 的 NVLink mesh 拓扑(无交换机)中,由于每对 GPU 之间只能分到有限带宽,曲线会呈现下降趋势。
采用 NVLink Switch 的 8 GPU 网络拓扑能显著提升性能,因为每对 GPU 之间均实现完全带宽。
通过 NVLink Switch 扩展至 72 个 GPU 的域,可最大限度地提升性能和收益。
NVLink Fusion 实现对NVLink scale-up 技术的定制化使用
NVIDIA 推出了 NVLink Fusion,使超大规模数据中心能够采用经过生产验证的 NVLink scale-up 技术。该技术可让定制芯片(包括 CPU 和 XPU)与 NVIDIA 的 NVLink scale-up 网络技术以及机架级扩展架构相集成,从而实现半定制化的 AI 基础设施部署。
NVLink scale-up 技术涵盖 NVLink SERDES、NVLink chiplets、NVLink 交换机以及机架级扩展架构的整体方案。高密度机架级扩展架构包括 NVLink spine、铜缆系统、创新的机械结构、先进的供电与液冷技术,以及供应链就绪的完整生态系统。
NVLink Fusion 为定制 CPU、定制 XPU 或两者的组合配置提供了灵活的解决方案。作为模块化开放计算项目(OCP)MGX 机架架构的一部分,NVLink Fusion 可与任何网卡(NIC)、数据处理器(DPU)或横向扩展交换机集成,使客户能够根据需求灵活构建理想的系统。
对于自定义 XPU 配置,NVLink 通过通用芯粒互连(Universal Chiplet Interconnect Express, UCIe)IP 与接口实现集成。NVIDIA 提供支持 UCIe 的 NVLink 桥接芯片,既能实现极高性能,又便于集成,使客户能够像 NVIDIA 一样充分利用 NVLink 的功能。UCIe 作为一项开放标准,采用该接口进行 NVLink 集成可让客户为其 XPU 灵活选择当前或未来平台的多种方案。
对于自定义 CPU 配置,建议集成 NVIDIA NVLink-C2C IP,以连接 NVIDIA GPU,从而实现最佳性能。采用定制 CPU 与 NVIDIA GPU 的系统可平滑访问 CUDA 平台的数百个 NVIDIA CUDA-X 库,充分发挥加速计算的高性能优势。
由广泛的生产就绪合作伙伴生态系统提供有力支持
NVLink Fusion 拥有一个强大的芯片生态系统,涵盖定制芯片、CPU 以及 IP 技术合作伙伴,不仅确保了广泛的技术支持和快速的设计实现,还持续推动着技术创新。
对于机架产品,用户可受益于我们的系统合作伙伴网络以及数据中心基础设施组件供应商。这些合作伙伴和供应商已实现 NVIDIA Blackwell NVL72 系统的大规模生产。通过整合生态系统与供应链资源,用户能够加快产品上市速度,并显著缩短机架级扩展系统,以及 scale-up 网络的生产部署时间。
提升 AI 推理性能
NVLink 代表了满足 AI 推理时代计算需求的重大飞跃。NVLink Fusion 充分融合了 NVIDIA 在 NVLink scale-up 技术领域长达十年的深厚积累,结合 OCP MGX 机架架构及生态系统开放的生产部署标准,为超大规模数据中心提供了卓越的性能与全面的定制化选项。
-
NVIDIA
+关注
关注
14文章
5732浏览量
110360 -
AI
+关注
关注
91文章
42228浏览量
303247 -
模型
+关注
关注
1文章
3882浏览量
52373
原文标题:借助 NVIDIA NVLink 和 NVLink Fusion 扩展 AI 推理性能和灵活性
文章出处:【微信号:NVIDIA-Enterprise,微信公众号:NVIDIA英伟达企业解决方案】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
英特尔FPGA 助力Microsoft Azure机器学习提供AI推理性能
NVIDIA扩大AI推理性能领先优势,首次在Arm服务器上取得佳绩

NVIDIA打破AI推理性能记录
进一步解读英伟达 Blackwell 架构、NVlink及GB200 超级芯片
NVIDIA 在首个AI推理基准测试中大放异彩
求助,为什么将不同的权重应用于模型会影响推理性能?
如何提高YOLOv4模型的推理性能?
英特尔FPGA为人工智能(AI)提供推理性能
NVIDIA A100 GPU推理性能237倍碾压CPU
NVIDIA发布最新Orin芯片提升边缘AI标杆
Nvidia 通过开源库提升 LLM 推理性能
开箱即用,AISBench测试展示英特尔至强处理器的卓越推理性能





评论