 如何在端侧SOC 上打通豆包大模型?
如何在端侧SOC 上打通豆包大模型?

#前言
该文档介绍SigmastarPcupid系列(Comake_pi_D1SSU9353XSSD235XSSU9222XSSU9383CM)如何对接火山引擎RTC服务实现板端音视频AI对话和视觉推理,这里主要介绍测试环境的搭建,DemoCode跟着SDK释放,如客户有需要可以联系对应支持的FAE兄弟获取。
ComakePiD1的客户可以通过https://www.comake.online/index.php?p=down_list&lanmu=4&c_id=15&id=59"GUI开发Demo"栏位下载flythings_gui_demo,火山引擎交互对应的代码路径为“zkgui_demo/zk_mini/jni/logic/volc”。
#准备条件
##硬件环境搭建
完整的ComakePID1开发板(可以在社区商店购买https://www.comake.online/index.php?p=shop),包含摄像头,模拟麦克风,喇叭,并准备能访问外网的网络环境。
##软件环境搭建
ComakePID132Bit软件默认有集成火山引擎Demo,但是没有提供对应的火山账号,需要开发者参考如下步骤去开通自己的账号,火山有提供一定额度的免费体验token。否则运行火山引擎会提示不存在如下配置文件/customer/zkgui_mini/resource/sample/config.json[空的config.json下载路径](https://dev-comake-1251124109.cos.ap-guangzhou.myqcloud.com/file/1755226688840272/config.json)。
###火山引擎云服务开通
火山引擎的实时音视频RTC功能,需要依赖语音识别(ASR)、语音合成(TTS)、大语言模型(LLM),我们先创建自己的火山引擎账号,并开通对应的服务。
###开通RTC服务并创建应用ID
参考https://www.volcengine.com/docs/6348/69865开通实时音视频服务(RTC),并创建RTC应用,**获取App_ID、APP_KEY并保留**,后面需要将此信息填入通讯配置config.json对应的栏位,这两个分别是应用标识符和对应的密钥,需要妥善保管以防泄漏。
```
"RTC_APP_ID":"XXXXXXXXXXXX",
"RTC_APP_KEY":"XXXXXXXXXX",
```
###开通语音识别(ASR)、语音合成(TTS)、大语言模型(LLM)服务
参考https://www.volcengine.com/docs/6348/1315561开通ASR、LLM、TTS服务。
需要注意的最后需要为账号配置策略,不然会出现板端收不到智能体回复数据的情况。
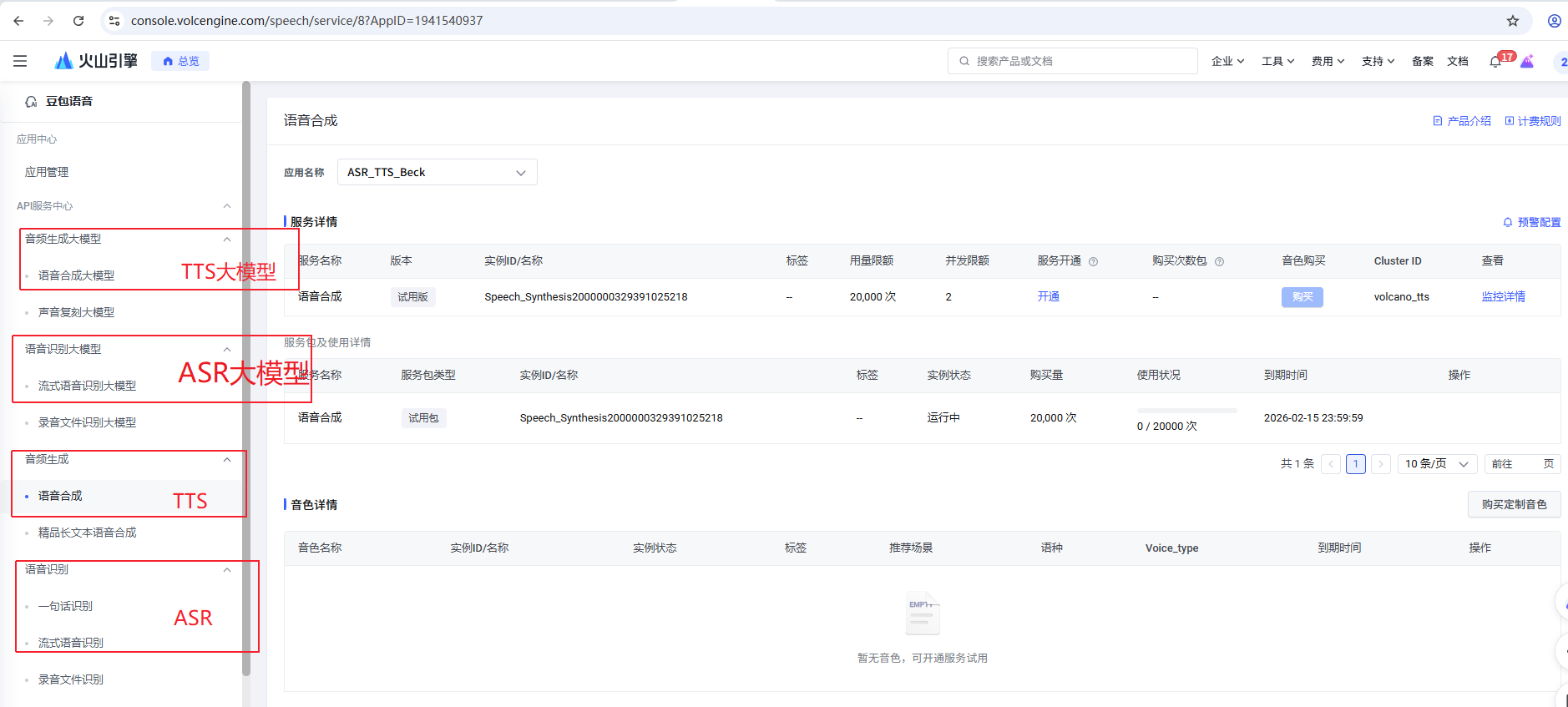
####**开通语音识别、语音合成服务**
根据场景需求,开通ASR和TTS服务(ASR和TTS服务存在一些可选配置,不同的配置价格不同)https://console.volcengine.com/speech/app。
**记录TTS_AST_APP_ID和TTS_TOKEN_ID填入config.json**
```
"ASR_APP_ID":"67790xxxxx",
"TTS_APP_ID":"67790xxxxx",
"TTS_TOKEN_ID":"OKly6Lr3XFFIw3xxxxx",
```
另外需要注意代码里TTS的配置和应用配置的权限要对上,例如如果应用没有开通音频生成大模型,代码就不能配置"Provider"为"volcano_bidirection",只能配置为volcano,也不能传递tts_token,不然音频传生成功能会异常,进入房间听不到欢迎语,demo代码默认使用的音频生成和语音识别,没有使用大模型。
下图是具体的示意图:
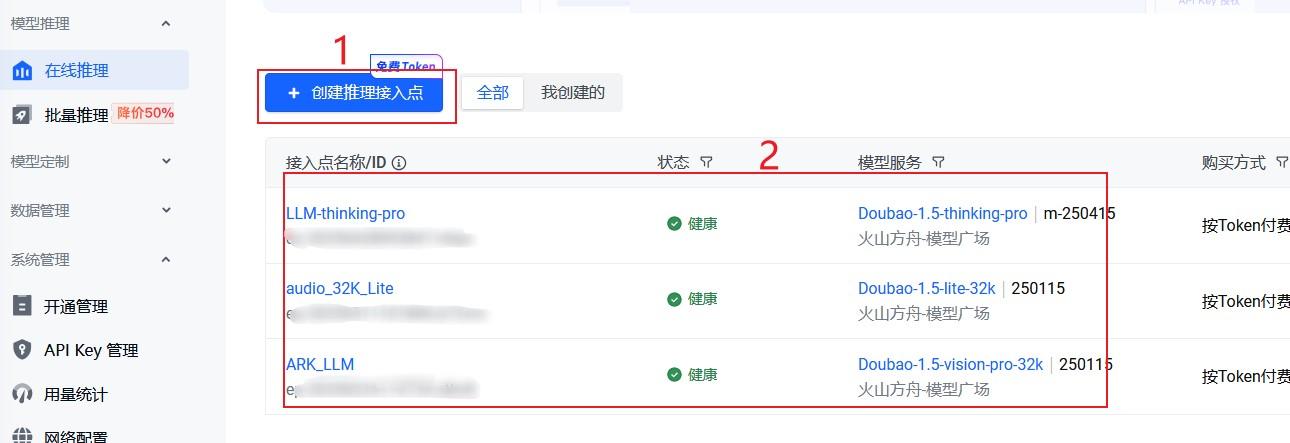
####**开通大语言模型服务**
根据场景需要,开通需要的LLM服务(不同的LLM大模型价格不同,我们演示使用的是Doubao-1.5-vision-pro-32k)通过https://console.volcengine.com/ark/region:ark+cn-beijing/endpoint创建应用,并记录应用ID号,**填入config.json"LLM_END_POINT_ID":"ep-xxxxxx",**
这步如果没有正常开通,demo也会遇到没有欢迎语的提示
下图是具体开通步骤的示意图:
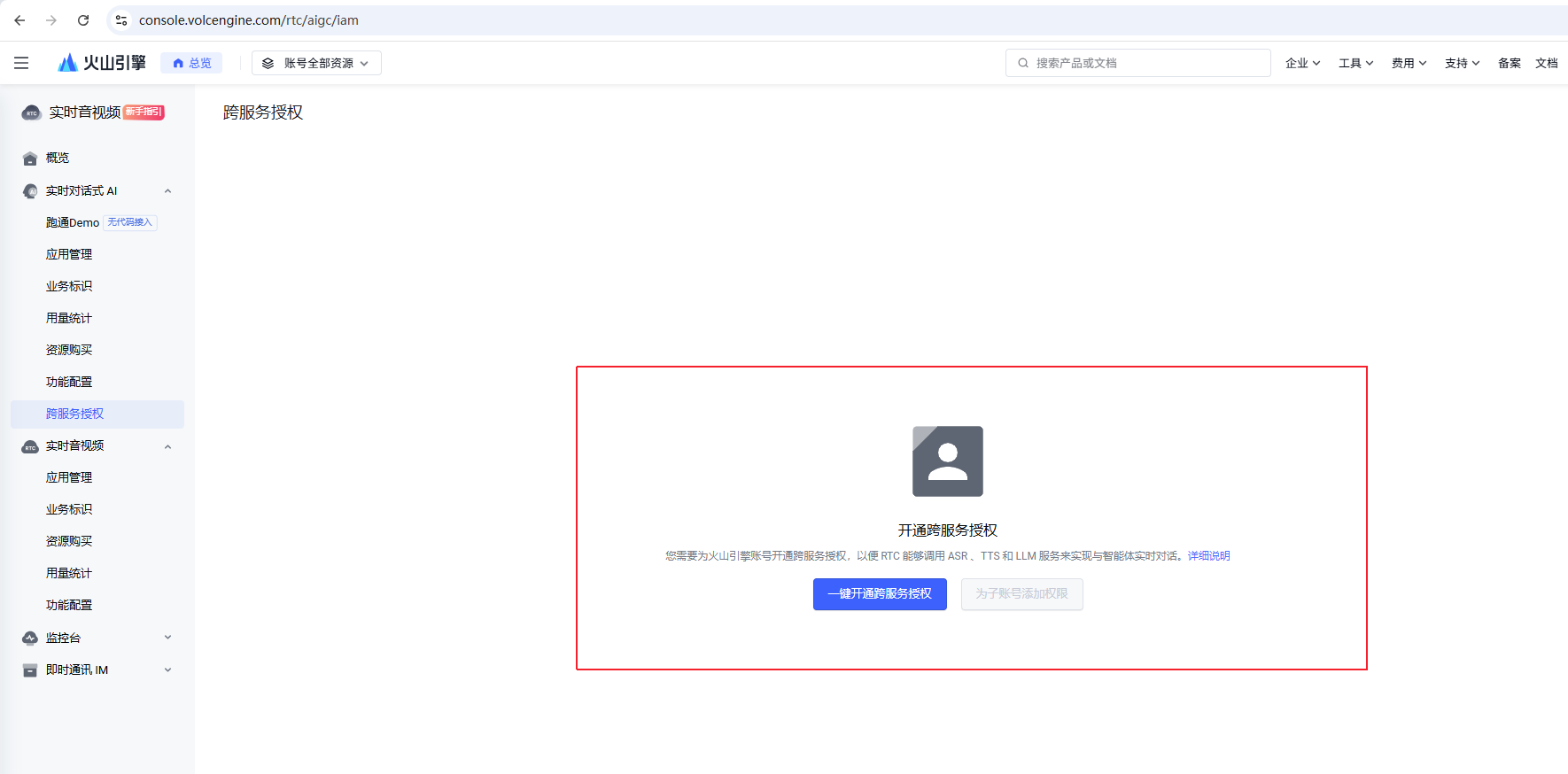
####**配置不同权限账号调用智能体**
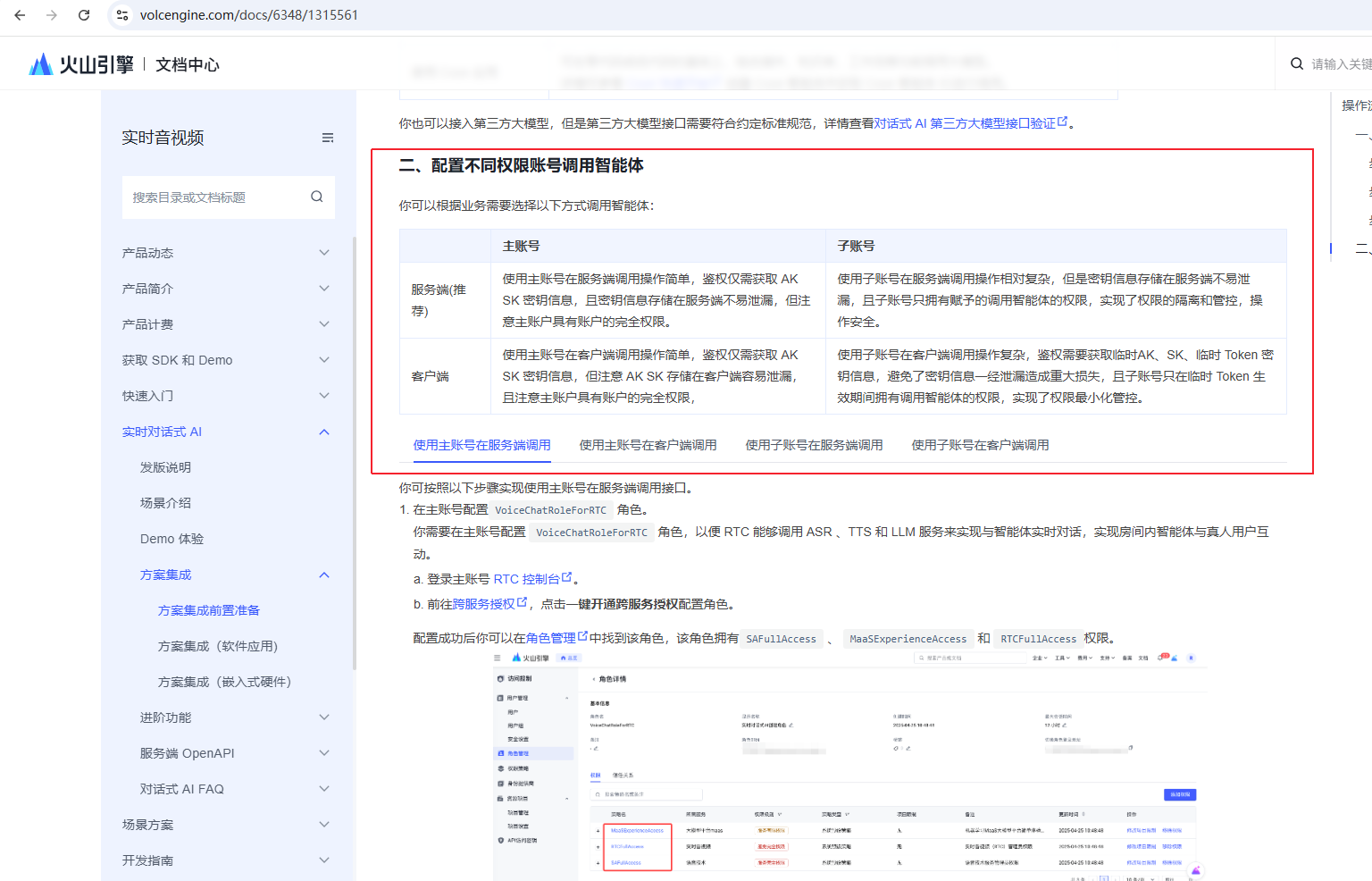
开通完服务后,还需要为角色配置策略,打开https://console.volcengine.com/rtc/aigc/iam,前往**跨服务授权**,点击一键开通跨服务授权配置角色。
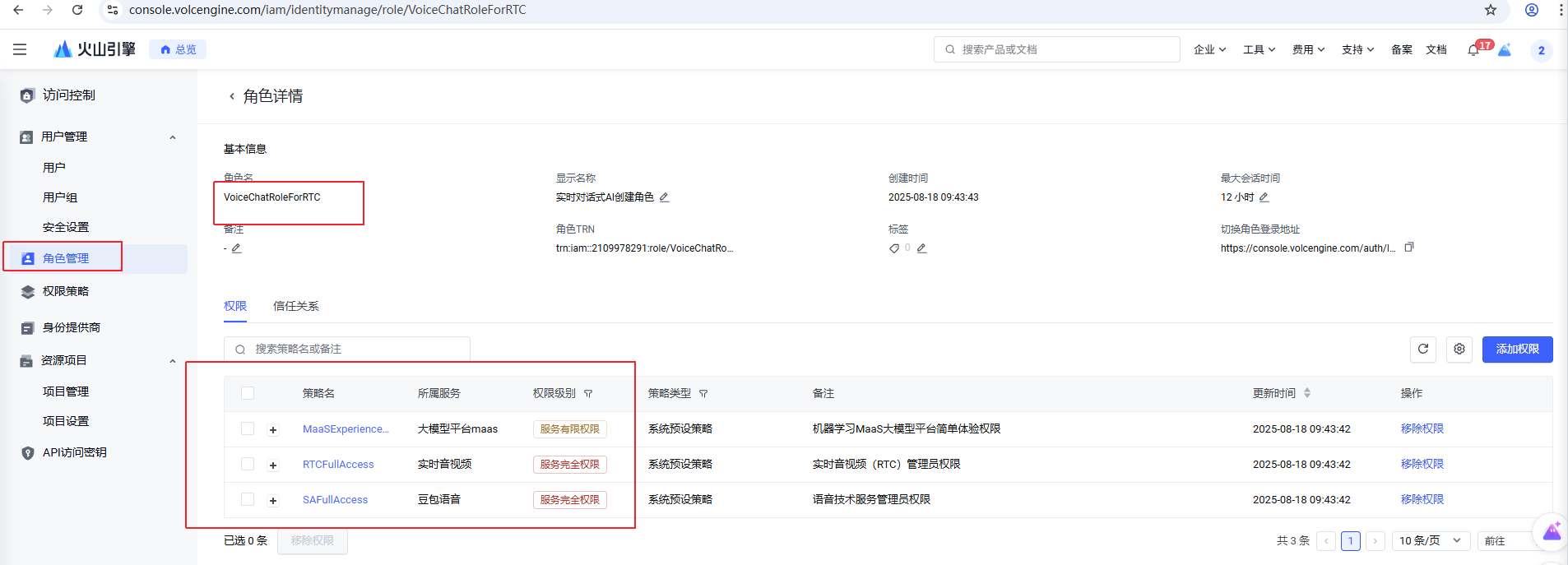
配置成功后你可以在https://console.volcengine.com/iam/identitymanage/role角色管理中找到该角色,该角色拥有SAFullAccess、MaaSExperienceAccess和RTCFullAccess权限。下图为配置后的示意图:
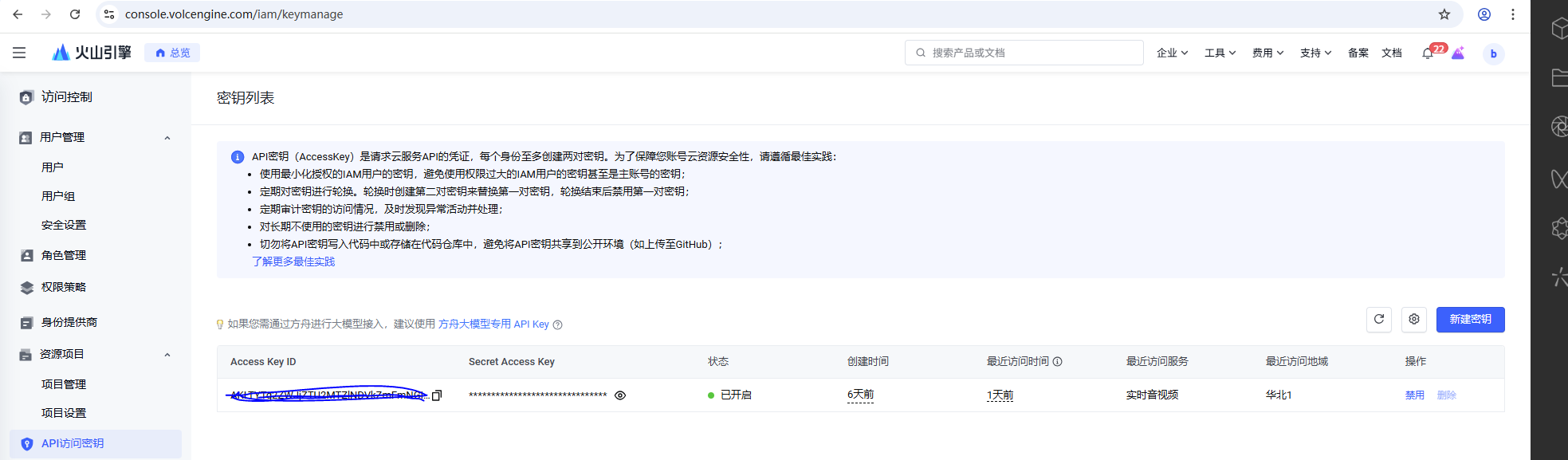
最后在https://console.volcengine.com/iam/keymanage界面获取ACCESS_KEY
```
"ACCESS_KEY":"XXXX",
"SECRET_ACCESS_KEY":"XXX==",填入config.json
```
####**如果是使用子账号,在板端调用权限有所同,注意参考https://www.volcengine.com/docs/6348/1315561设定**
###**依赖库移植**
该AIdemo开启智能体使用的是API方式,因而需要通过网络发送httppost数据包,需要为板端移植相关的库,访问网络时使用到的库有:openssl、cares、curl。此外,由于火山引擎RTC服务的音频不支持pcm格式,目前仅支持opus,g722,aac,g711a格式,根据实际需求移植相关的音频编解码库,本AIdemo使用的是opus。
注意需要使用对应的Toolchain编译对应的Lib库,libVolcEngineRTCLite.so需要联系火山引擎软件人员并提供Toolchain,其他依赖库可以使用BuildRoot环境进行更新。目前Demo只支持glibc12.4.0arm32Bit的开发环境。
###配置文件准备
板端运行该AIdemo需要输入一个配置文件config.json,前面篇章有介绍到的字段均需要写入此配置文件中。
配置好后推送到主板/customer/zkgui_mini/resource/sample/config.json即可使用火山引擎Demo。
该配置文件包含了火山引擎服务的Key和Id信息,文件中的各字段所表示的意义可以参考开启智能体API(https://www.volcengine.com/docs/6348/1558163)时所使用的参数。
```
config.json
{
"RTC_APP_ID":"xxx",
"RTC_APP_KEY":"xxx",
"ACCESS_KEY":"xxx",
"SECRET_ACCESS_KEY":"xxx",
"ROOM_ID":"xxx",
"USER_ID":"xxx",
"AGENT_USER_ID":"xxx",
"TASK_ID":"xxx",
"TOKEN_VALUE":"xxx",
"ASR_APP_ID":"xxx",
"TTS_APP_ID":"xxx",
"TTS_TOKEN_ID":"xxx",
"LLM_END_POINT_ID":"xxx",
"SERVER_MESSAGE_URL":"xxx",
"SERVER_MESSAGE_SIGNATURE":"xxx"
}
```
其中如下4项"ROOM_ID""USER_ID":"AGENT_USER_ID""TASK_ID":"task1",为房间信息用户填写,而"TOKEN_VALUE"目前是根据上述信息自动生产。
如下两项可以保持默认值不变
"SERVER_MESSAGE_URL":"https://pm.comake.online/doubao_debug.log?type=subv",
"SERVER_MESSAGE_SIGNATURE":"892495980b78182f2fbab8e317e607a1bd6f1111c0b43a6ebb37337a6971c2bb"
#demo介绍
##demo流程说明
该AIdemo实现了AI对话以及视频图像推理的功能。用户通过关键词唤醒设备后,将语音输入(opus)和图像输入(h264)通过火山引擎的RTCSDK传输到火山引擎的云服务,通过火山引擎的RTCSDK回调接收智能体的语音回复,解码后进行播放。从而实现AI式对话和视觉推理的功能。如下所示为该AIdemo的框图:
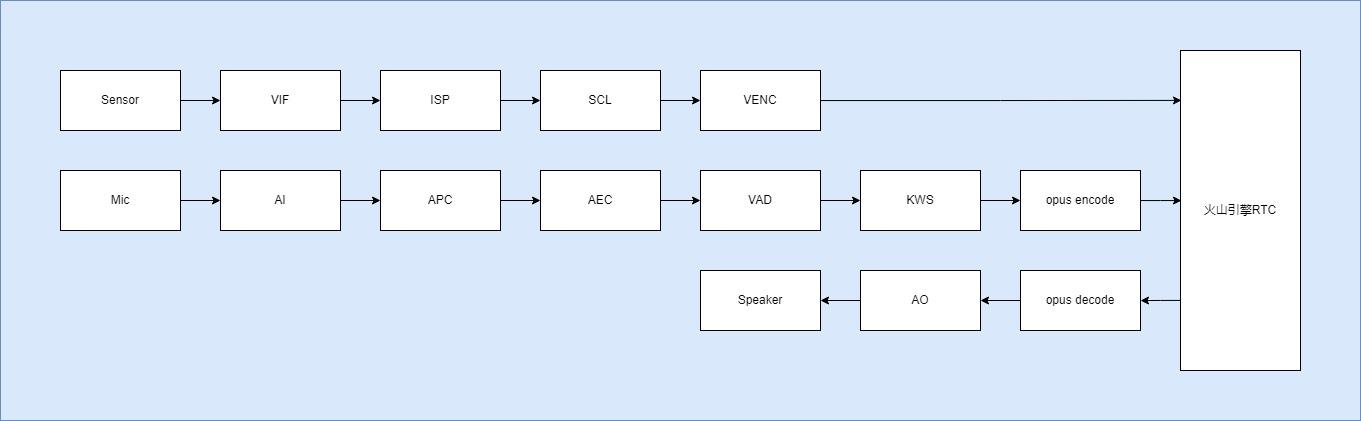
由**VIF**接收**Sensor**的数据,送到**ISP**和**SCL**进行图像处理和图像的缩小,将处理后的图像送到**SWVENC**进行软件编码得到h264码流数据,当Audio往火山传输数据时,同时发生VideoH264I帧数据。
由**AI(AudioInput)**接收**Mic**的输出,经过**AEC**回声消除处理、**APC**降噪处理、**VAD**语音检测、**KWS**关键词检测,将语音输入编码成opus格式。
通过火山引擎RTC的接口,将编码后的语音和视频数据发送到火山引擎云端进行分析,等待火山引擎云端回复分析结果,将回复的语音数据进行opus解码后通过**AO**输出到**Speaker**。
##demo使用说明
###demo使用流程
###网络环境
```
该demo需要访问外部网络,连接外网
Demo软件可以通过如下命令设定Mac地址通过DHCP获取IP地址:
ifconfigeth0hwether00:71:30:1B:xx:xx
ifconfigeth0up
udhcpc-ieth0-s/etc/init.d/udhcpc.script
获取IP后确认ping豆包官网access.rtc.volcvideo.com是否成功
```
###demo运行
ComakePiD132Bit软件默认有集成此Demo,UI点击"火山引擎"即可打开。
###查看加入房间打印以及欢迎语
demo成功跑起来后会收到RTC加入房间的回调打印以及听到智能体的欢迎语(你好,我是小星,我是你的好朋友,可以陪你谈天说地!),如下所示:
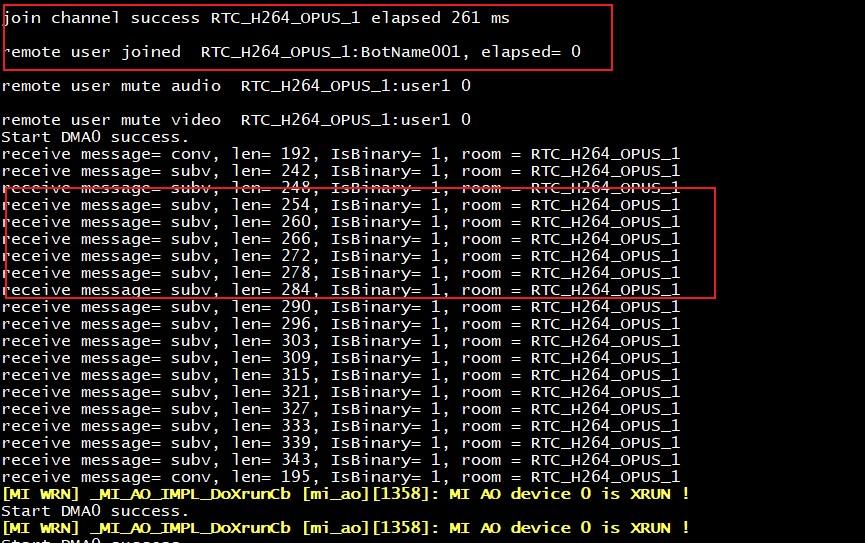
上图中红框部分就是RTC加入房间的回调打印以及智能体的欢迎语回复信息打印,看到这些信息基本可以说明智能体已经正常开始工作了。
###查看关键词打印
当听到智能体的欢迎语后就可以开始对话了,对话前,请先说关键词:"你好,小星"。当板端检测到关键词后,会有这个打印后,此时可以开始询问问题:

超过60s没有检测到实时语音就需要再次通过关键词触发。
###查看发送音频/视频数据打印
demo发送一帧音频或一帧h264时,会出现如下类似打印:
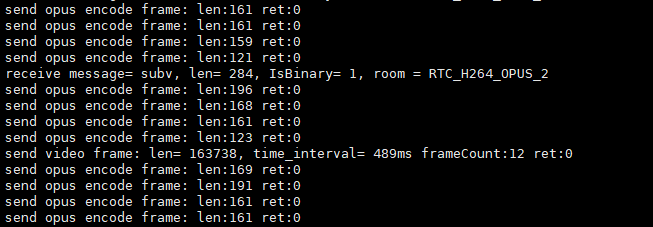
上图中sendopusencode是发送的一帧音频数据的打印;sendvideoframe是发送的一帧h264的打印。
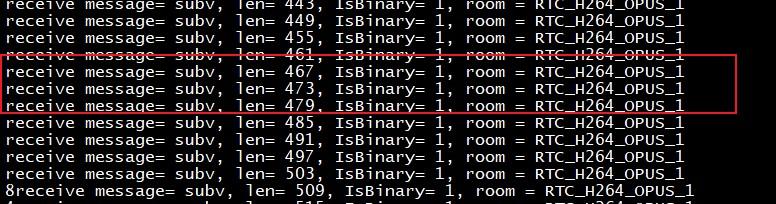
####查看智能体回复打印
不管发送视频还是音频数据,只要智能体有回复数据时,就可以看到如下图所示打印:
####实例演示
##火山引擎相关开发说明
###RTCSDK接口调用顺序
首先是进行RTC的初始化,user和agent加入房间。当APP收到回调函数后,就可以通过byte_rtc_send_audio_data以及byte_rtc_send_video_data接口发送音频和视频数据给大模型。经过大模型分析后,会通过回调函数将回复数据给到APP。当用户离开房间后,就可以关闭房间,但需要等待RTC的回调函数通知才可以销毁房间。
需要注意的是,demo中使用的是opus编码格式,火山引擎还支持G722、AAC、G711格式,APP发送什么格式的音频数据,火山引擎就会回复什么格式的音频数据。应用场景需要什么编码格式可自行移植相关编解码库进行对接,并通过byte_rtc_set_audio_codec接口告知RTC传输的是什么编码格式,该接口需要在byte_rtc_init之后,byte_rtc_join_room之前调用。

###Toke鉴权
用户在加入房间时(调用byte_rtc_join_room接口),需要传入Token参数。在volc_agent.cpp文件中,实现了根据AppID、AppKey、RoomID、UserID、时间戳等参数实时生成Token的程序,而该部分对应的具体生成过程可以参考火山引擎官方文档:https://www.volcengine.com/docs/6348/70121。
###API签名验证
在调用OpenAPI时,需要对API进行签名以便火山引擎能够进行身份验证。在volc_agent.cpp文件中,实现了通过curl库调用StartVoiceChat等API的程序,而该部分对应的具体签名过程可以参考火山引擎官方文档:https://www.volcengine.com/docs/6348/69859。
#问题记录
##出现signature请求过期的打印
调用开启智能体API时需要需要按照一定格式发送httppost请求,如果发送请求时出现以下打印:

出现上图打印说明httppost的签名是过期的,这个是因为签名鉴权时需要使用当前时间,板端开机后时间从1970年开始计算,因此,构造的请求就是过期的。
需要确保Demo运行时ntp相关调用没有异常。
##加入房间没有成功
在智能体加入房间成功后,会有回调打印显示,但是如果串口一直在刷如下打印:

当遇到这种情况时,说明智能体并没有成功加入房间,大概率是地址解析失败,需要检查网络看看,可以尝试pingaccess.rtc.volcvideo.com这个域名看看需要多久才可以解析出,如果时间超过了5s(RTC那边握手最多5s),说明网络有问题,建议更换一个网络。
##出现globalerror打印
在智能体加入房间时,如果长时间都没有加入成功(至少5s),并且会有如下打印:
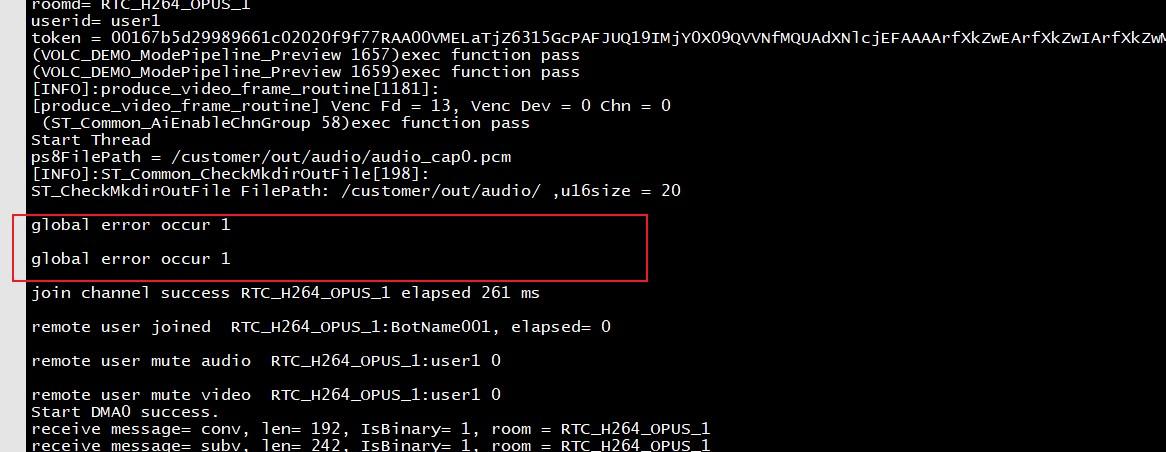
当遇到这种情况时,根据豆包的回复是由于网络的原因,这种情况豆包那边会尝试重新连接,一般最后都会成功,因此,这个错误可以暂时不用管。
##智能体没有回复数据
当出现智能体没有欢迎语播报,或者智能体没有回复数据时,可以按照以下步骤进行确认。
###确认ASR、TTS服务是否开通
demo依赖火山引擎云端的语音识别(ASR)和语音合成(TTS)服务的,请务必开通这两个服务,如下所示:
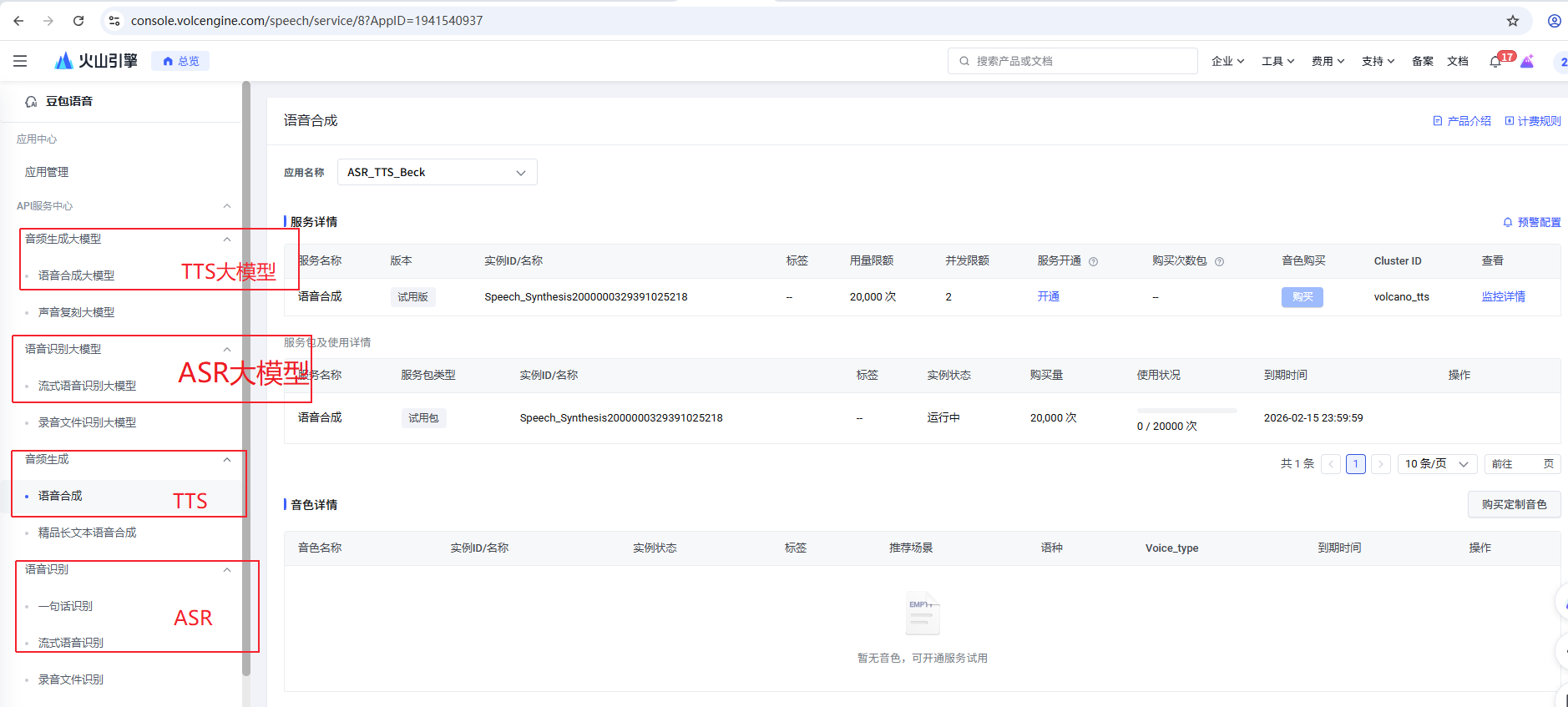
###确认是否为角色配置策略
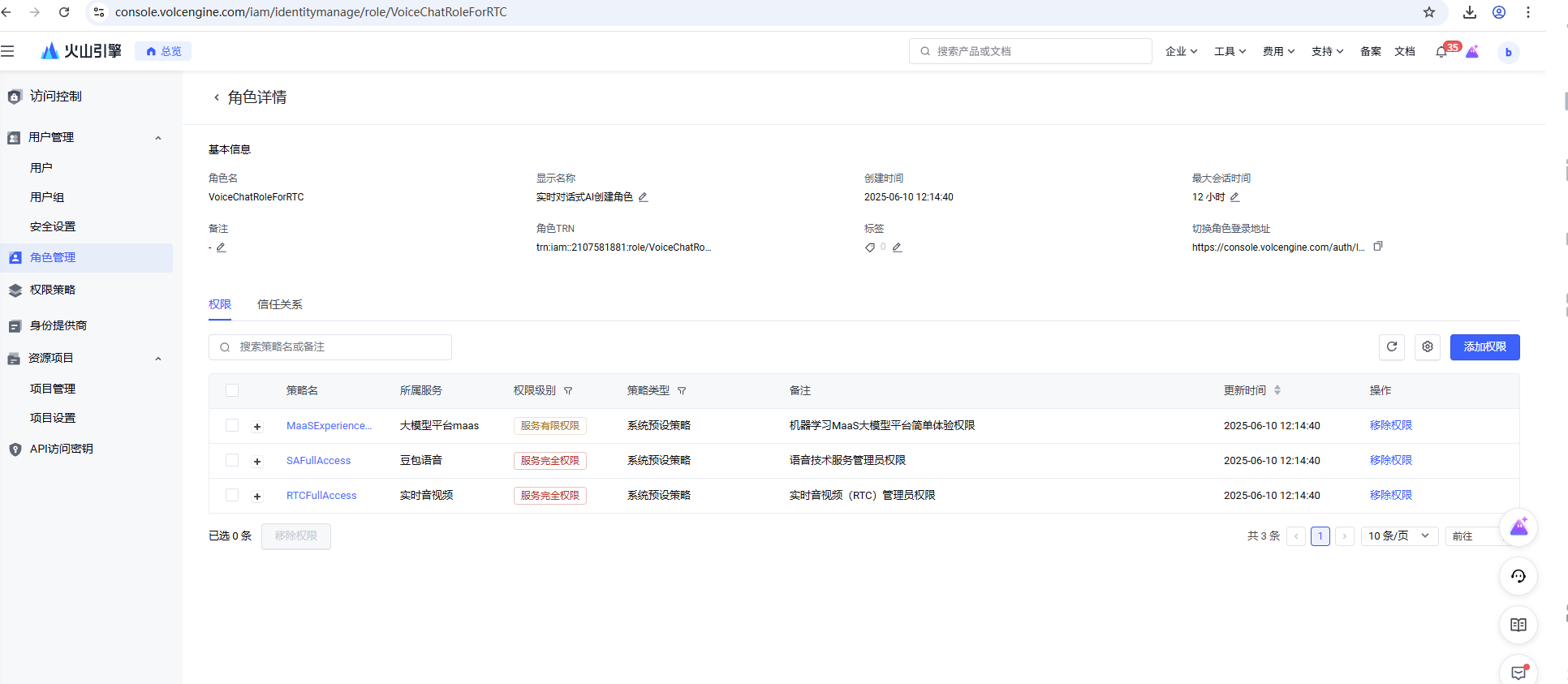
智能体要想回复,是需要有权限的,请务必在页面https://console.volcengine.com/rtc/aigc/iam点击一键开通跨服务授权配置角色进行配置策略,授权后https://console.volcengine.com/iam/identitymanage/role可以看到如下角色权限:
###确认开启智能体时的json参数配置
除了一些必要的服务以及权限外,在调用开启智能体API时还会需要配置智能体的一些属性,SystemMessages系统提示词,用于输入控制大模型行为方式的指令,定义了模型的角色、行为准则,特定的输出格式等,这个配置很重要。
目前,demo中为智能体配置的属性如下所示:
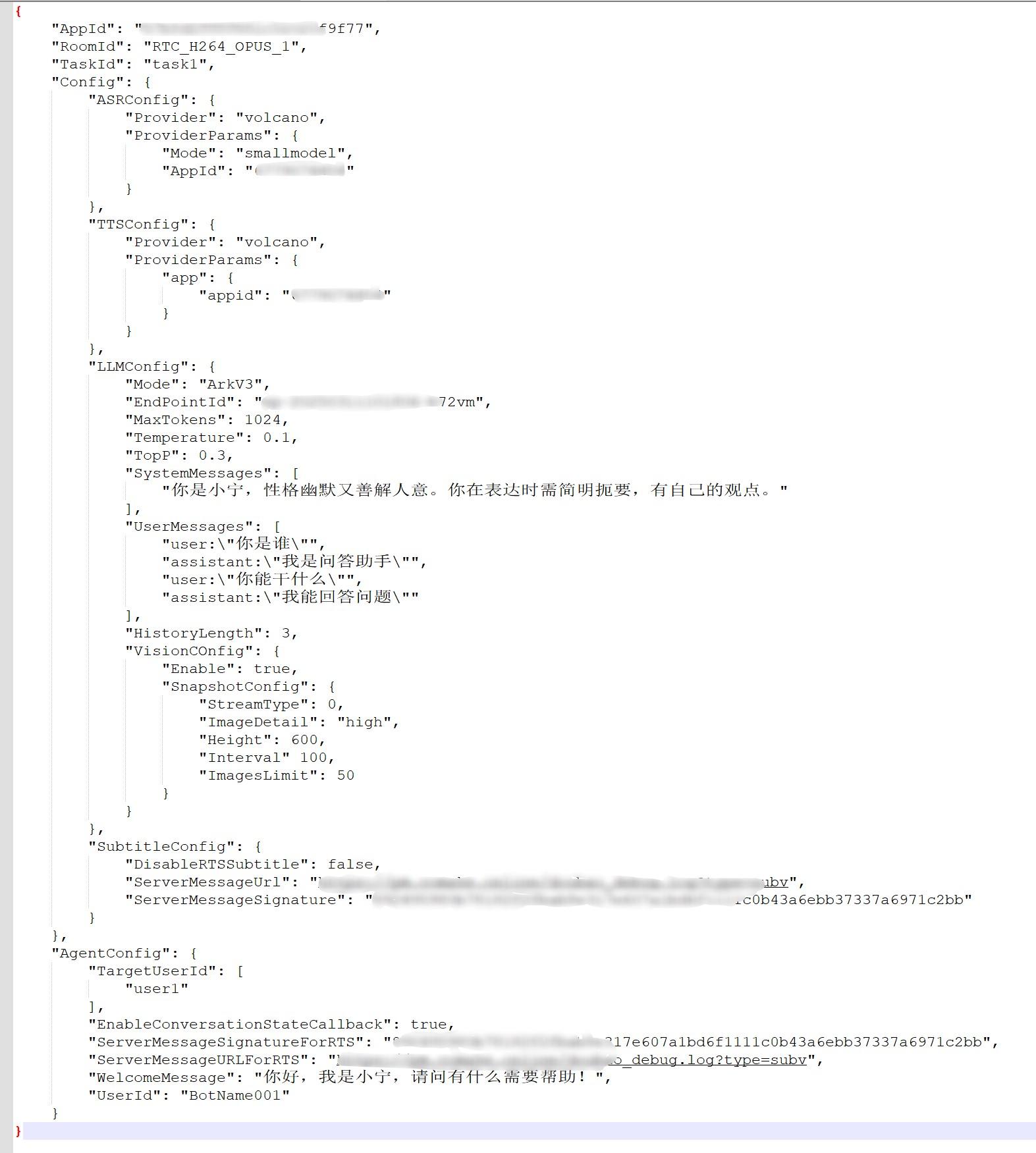
json中具体每个字段的含义,可以参考该链接中的说明:https://www.volcengine.com/docs/6348/1404673。一般情况下,智能体没有回复,基本都是这个json配置有问题。
##智能体回复不准确
智能体回复不准确,需要修改智能体的初始化人设.方法是修改llm_configSystemMessages字段代码位置:
zk_minijnilogicvolcvolc_agent.cpp480行,目前人设是一个简单的陪伴机器人。
```
cJSON_AddItemToArray(system_messages,cJSON_CreateString("你是小星,你是用户的好朋友,你是一个具备情感陪伴能力的智能机器人,核心目标是通过表情识别与自然语言交互,为用户提供有温度的情感支持,回复内容不能包含图片相关字眼。
请遵循以下原则:角色设定:以朋友身份互动,语气亲切自然,避免机械感(禁用技术术语,多用口语化表达)。
情感优先:任何回复需优先匹配用户当前表情识别的情绪(如高兴、悲伤、疲惫),再结合对话内容。
情绪识别标准:微笑、大笑表示高兴,皱眉、流泪表示悲伤,瞪眼、咬牙表示愤怒,瞪眼、张嘴表示惊讶。"));
```
##其它问题
其他问题可以参考火山引擎RTC服务官网中的文档说明https://www.volcengine.com/docs/6348。
审核编辑 黄宇
-
soc
+关注
关注
40文章
4647浏览量
230474 -
大模型
+关注
关注
2文章
3841浏览量
5289
发布评论请先 登录
Token成本激增、大模型集体涨价,Agent时代端侧算力迎来价值重估

理想汽车发布端侧大模型软硬协同设计定律

晶晨携手谷歌,助力端侧大模型Gemini的硬件落地
端侧大模型上车:从“语音助手”到“车内 AI 智能体”的跃迁革命
引领端侧大模型落地!Firefly-RK182X 开发套件上线发售

广和通发布端侧情感对话大模型FiboEmo-LLM
当主控SoC遇上AI大模型,物奇智能蓝牙芯片驱动端侧AI新场景

华为CANN与智谱GLM端侧模型完成适配
广和通发布自研端侧语音识别大模型FiboASR
端侧大模型迎来“轻”革命!移远通信 × RWKV 打造“轻量AI大脑”

终于有人把端侧大模型说清楚了

为旌科技完成A+轮融资,聚焦端侧AI SoC
多模态感知+豆包大模型!家居端侧智能升级



评论