 Kafka生产环境应用方案
Kafka生产环境应用方案

Kafka生产环境应用方案:高可用集群部署与运维实战
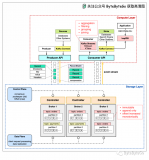
架构图
┌─────────────────────────────────────────────────────────────────────────────────┐ │ Kafka生产环境架构 │ ├─────────────────────────────────────────────────────────────────────────────────┤ │ │ │ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ │ │ │ Producer1 │ │ Producer2 │ │ Producer3 │ │ │ └─────────────┘ └─────────────┘ └─────────────┘ │ │ │ │ │ │ │ └─────────────────┼─────────────────┘ │ │ │ │ │ ┌─────────────────────────────────────────────────────────────────────────┐ │ │ │ Kafka Cluster │ │ │ │ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ │ │ │ │ │ Broker1 │ │ Broker2 │ │ Broker3 │ │ Broker4 │ │ │ │ │ │192.168.1.11 │ │192.168.1.12 │ │192.168.1.13 │ │192.168.1.14 │ │ │ │ │ │ Port:9092 │ │ Port:9092 │ │ Port:9092 │ │ Port:9092 │ │ │ │ │ └─────────────┘ └─────────────┘ └─────────────┘ └─────────────┘ │ │ │ └─────────────────────────────────────────────────────────────────────────┐ │ │ │ │ │ │ ┌─────────────────────────────────────────────────────────────────────────┐ │ │ │ ZooKeeper Cluster │ │ │ │ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ │ │ │ │ │ ZK1 │ │ ZK2 │ │ ZK3 │ │ │ │ │ │192.168.1.21 │ │192.168.1.22 │ │192.168.1.23 │ │ │ │ │ │ Port:2181 │ │ Port:2181 │ │ Port:2181 │ │ │ │ │ └─────────────┘ └─────────────┘ └─────────────┘ │ │ │ └─────────────────────────────────────────────────────────────────────────┘ │ │ │ │ │ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ │ │ │ Consumer1 │ │ Consumer2 │ │ Consumer3 │ │ │ │ (Group A) │ │ (Group B) │ │ (Group C) │ │ │ └─────────────┘ └─────────────┘ └─────────────┘ │ │ │ │ ┌─────────────────────────────────────────────────────────────────────────┐ │ │ │ 监控系统 │ │ │ │ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ │ │ │ │ │ Prometheus │ │ Grafana │ │ Kafka │ │ │ │ │ │ Metrics │ │ Dashboard │ │ Manager │ │ │ │ │ └─────────────┘ └─────────────┘ └─────────────┘ │ │ │ └─────────────────────────────────────────────────────────────────────────┘ │ └─────────────────────────────────────────────────────────────────────────────────┘
引言
Apache Kafka作为分布式流处理平台,在现代大数据架构中扮演着消息中间件的核心角色。本文将从运维工程师的角度,详细介绍Kafka在生产环境中的部署方案、配置优化、监控运维等关键技术。通过实战案例和代码示例,帮助运维团队构建稳定、高效的Kafka集群。
1. Kafka集群自动化部署
1.1 ZooKeeper集群部署脚本
#!/bin/bash
# ZooKeeper集群自动化部署脚本
set-e
ZK_VERSION="3.8.1"
ZK_NODES=("192.168.1.21""192.168.1.22""192.168.1.23")
ZK_DATA_DIR="/data/zookeeper"
ZK_LOG_DIR="/logs/zookeeper"
# 创建ZooKeeper用户
useradd -r -s /bin/false zookeeper
# 下载安装ZooKeeper
install_zookeeper() {
cd/tmp
wget https://archive.apache.org/dist/zookeeper/zookeeper-${ZK_VERSION}/apache-zookeeper-${ZK_VERSION}-bin.tar.gz
tar -xzf apache-zookeeper-${ZK_VERSION}-bin.tar.gz
mvapache-zookeeper-${ZK_VERSION}-bin /opt/zookeeper
chown-R zookeeper:zookeeper /opt/zookeeper
}
# 配置ZooKeeper
configure_zookeeper() {
localnode_id=$1
localnode_ip=$2
# 创建数据目录
mkdir-p${ZK_DATA_DIR}${ZK_LOG_DIR}
chown-R zookeeper:zookeeper${ZK_DATA_DIR}${ZK_LOG_DIR}
# 设置节点ID
echo${node_id}>${ZK_DATA_DIR}/myid
# 生成配置文件
cat> /opt/zookeeper/conf/zoo.cfg << EOF
tickTime=2000
initLimit=10
syncLimit=5
dataDir=${ZK_DATA_DIR}
dataLogDir=${ZK_LOG_DIR}
clientPort=2181
maxClientCnxns=60
# 集群配置
server.1=192.168.1.213888
server.2=192.168.1.223888
server.3=192.168.1.233888
# 性能优化
autopurge.snapRetainCount=10
autopurge.purgeInterval=1
EOF
}
# 启动ZooKeeper服务
start_zookeeper() {
# 创建systemd服务文件
cat > /etc/systemd/system/zookeeper.service << EOF
[Unit]
Description=Apache ZooKeeper server
Documentation=http://zookeeper.apache.org
Requires=network.target remote-fs.target
After=network.target remote-fs.target
[Service]
Type=forking
User=zookeeper
Group=zookeeper
Environment=JAVA_HOME=/usr/lib/jvm/java-11-openjdk
ExecStart=/opt/zookeeper/bin/zkServer.sh start
ExecStop=/opt/zookeeper/bin/zkServer.sh stop
ExecReload=/opt/zookeeper/bin/zkServer.sh restart
TimeoutSec=30
Restart=on-failure
[Install]
WantedBy=multi-user.target
EOF
systemctl daemon-reload
systemctl enable zookeeper
systemctl start zookeeper
}
# 执行部署
install_zookeeper
configure_zookeeper $1$2
start_zookeeper
ZooKeeper作为Kafka的协调服务,需要奇数个节点组成集群以保证高可用性。通过自动化脚本可以快速部署标准化的ZooKeeper环境。
1.2 Kafka集群部署配置
#!/bin/bash
# Kafka集群部署脚本
KAFKA_VERSION="2.8.2"
KAFKA_NODES=("192.168.1.11""192.168.1.12""192.168.1.13""192.168.1.14")
KAFKA_DATA_DIR="/data/kafka"
KAFKA_LOG_DIR="/logs/kafka"
# 安装Kafka
install_kafka() {
cd/tmp
wget https://archive.apache.org/dist/kafka/2.8.2/kafka_2.13-${KAFKA_VERSION}.tgz
tar -xzf kafka_2.13-${KAFKA_VERSION}.tgz
mvkafka_2.13-${KAFKA_VERSION}/opt/kafka
# 创建kafka用户
useradd -r -s /bin/false kafka
chown-R kafka:kafka /opt/kafka
# 创建数据目录
mkdir-p${KAFKA_DATA_DIR}${KAFKA_LOG_DIR}
chown-R kafka:kafka${KAFKA_DATA_DIR}${KAFKA_LOG_DIR}
}
# 生成Kafka服务器配置
generate_kafka_config() {
localbroker_id=$1
localnode_ip=$2
cat> /opt/kafka/config/server.properties << EOF
# 服务器基础配置
broker.id=${broker_id}
listeners=PLAINTEXT://${node_ip}:9092
advertised.listeners=PLAINTEXT://${node_ip}:9092
num.network.threads=8
num.io.threads=16
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
# 日志配置
log.dirs=${KAFKA_DATA_DIR}
num.partitions=3
num.recovery.threads.per.data.dir=2
offsets.topic.replication.factor=3
transaction.state.log.replication.factor=3
transaction.state.log.min.isr=2
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
# ZooKeeper配置
zookeeper.connect=192.168.1.21:2181,192.168.1.22:2181,192.168.1.23:2181/kafka
zookeeper.connection.timeout.ms=18000
# 性能优化配置
replica.fetch.max.bytes=1048576
message.max.bytes=1000000
replica.socket.timeout.ms=30000
replica.socket.receive.buffer.bytes=65536
replica.fetch.wait.max.ms=500
replica.high.watermark.checkpoint.interval.ms=5000
fetch.purgatory.purge.interval.requests=1000
producer.purgatory.purge.interval.requests=1000
delete.topic.enable=true
# JVM配置
export KAFKA_HEAP_OPTS="-Xmx6G -Xms6G"
export KAFKA_JVM_PERFORMANCE_OPTS="-server -XX:+UseG1GC -XX:MaxGCPauseMillis=20 -XX:InitiatingHeapOccupancyPercent=35 -XX:+ExplicitGCInvokesConcurrent -Djava.awt.headless=true"
EOF
}
# 创建Kafka系统服务
create_kafka_service() {
cat > /etc/systemd/system/kafka.service << EOF
[Unit]
Description=Apache Kafka server (broker)
Documentation=http://kafka.apache.org/documentation.html
Requires=network.target remote-fs.target
After=network.target remote-fs.target zookeeper.service
[Service]
Type=simple
User=kafka
Group=kafka
Environment=JAVA_HOME=/usr/lib/jvm/java-11-openjdk
ExecStart=/opt/kafka/bin/kafka-server-start.sh /opt/kafka/config/server.properties
ExecStop=/opt/kafka/bin/kafka-server-stop.sh
TimeoutSec=30
Restart=on-failure
[Install]
WantedBy=multi-user.target
EOF
systemctl daemon-reload
systemctl enable kafka
systemctl start kafka
}
# 执行部署
install_kafka
generate_kafka_config $1$2
create_kafka_service
2. 生产环境性能优化
2.1 生产者性能调优
#!/usr/bin/env python3 # Kafka生产者性能优化配置 fromkafkaimportKafkaProducer importjson importtime importthreading fromconcurrent.futuresimportThreadPoolExecutor classOptimizedKafkaProducer: def__init__(self, bootstrap_servers, topic): self.topic = topic self.producer = KafkaProducer( bootstrap_servers=bootstrap_servers, # 性能优化配置 batch_size=16384, # 批处理大小 linger_ms=10, # 延迟发送时间 buffer_memory=33554432, # 缓冲区大小32MB compression_type='snappy', # 压缩算法 max_in_flight_requests_per_connection=5, retries=3, # 重试次数 retry_backoff_ms=100, request_timeout_ms=30000, # 序列化配置 value_serializer=lambdav: json.dumps(v).encode('utf-8'), key_serializer=lambdak:str(k).encode('utf-8') ) defsend_message_sync(self, key, value): """同步发送消息""" try: future =self.producer.send(self.topic, key=key, value=value) record_metadata = future.get(timeout=10) return{ 'topic': record_metadata.topic, 'partition': record_metadata.partition, 'offset': record_metadata.offset } exceptExceptionase: print(f"发送消息失败:{e}") returnNone defsend_message_async(self, key, value, callback=None): """异步发送消息""" try: future =self.producer.send(self.topic, key=key, value=value) ifcallback: future.add_callback(callback) returnfuture exceptExceptionase: print(f"发送消息失败:{e}") returnNone defbatch_send_performance_test(self, message_count=100000): """批量发送性能测试""" start_time = time.time() # 使用线程池并发发送 withThreadPoolExecutor(max_workers=10)asexecutor: futures = [] foriinrange(message_count): message = { 'id': i, 'timestamp': time.time(), 'data':f'test_message_{i}', 'source':'performance_test' } future = executor.submit(self.send_message_async,str(i), message) futures.append(future) # 等待所有消息发送完成 forfutureinfutures: try: future.result(timeout=30) exceptExceptionase: print(f"消息发送异常:{e}") # 确保所有消息都发送出去 self.producer.flush() end_time = time.time() duration = end_time - start_time throughput = message_count / duration print(f"发送{message_count}条消息") print(f"总耗时:{duration:.2f}秒") print(f"吞吐量:{throughput:.2f}消息/秒") defclose(self): self.producer.close() # 使用示例 if__name__ =="__main__": producer = OptimizedKafkaProducer( bootstrap_servers=['192.168.1.11:9092','192.168.1.12:9092'], topic='performance_test' ) # 执行性能测试 producer.batch_send_performance_test(50000) producer.close()
2.2 消费者性能优化
#!/usr/bin/env python3 # Kafka消费者性能优化配置 fromkafkaimportKafkaConsumer importjson importtime importthreading fromconcurrent.futuresimportThreadPoolExecutor classOptimizedKafkaConsumer: def__init__(self, topics, group_id, bootstrap_servers): self.topics = topics self.group_id = group_id self.consumer = KafkaConsumer( *topics, bootstrap_servers=bootstrap_servers, group_id=group_id, # 性能优化配置 fetch_min_bytes=1024, # 最小拉取字节数 fetch_max_wait_ms=500, # 最大等待时间 max_poll_records=500, # 单次拉取最大记录数 max_poll_interval_ms=300000, # 最大轮询间隔 session_timeout_ms=30000, # 会话超时时间 heartbeat_interval_ms=10000, # 心跳间隔 # 消费策略 auto_offset_reset='earliest', enable_auto_commit=False, # 手动提交偏移量 # 反序列化配置 value_deserializer=lambdam: json.loads(m.decode('utf-8')), key_deserializer=lambdam: m.decode('utf-8')ifmelseNone ) defconsume_messages_batch(self, batch_size=100, timeout=5000): """批量消费消息""" message_batch = [] try: # 批量拉取消息 message_pack =self.consumer.poll(timeout_ms=timeout) fortopic_partition, messagesinmessage_pack.items(): formessageinmessages: message_batch.append({ 'topic': message.topic, 'partition': message.partition, 'offset': message.offset, 'key': message.key, 'value': message.value, 'timestamp': message.timestamp }) iflen(message_batch) >= batch_size: # 处理批量消息 self.process_message_batch(message_batch) message_batch = [] # 处理剩余消息 ifmessage_batch: self.process_message_batch(message_batch) # 手动提交偏移量 self.consumer.commit() exceptExceptionase: print(f"消费消息异常:{e}") defprocess_message_batch(self, messages): """批量处理消息""" withThreadPoolExecutor(max_workers=5)asexecutor: futures = [] formessageinmessages: future = executor.submit(self.process_single_message, message) futures.append(future) # 等待所有消息处理完成 forfutureinfutures: try: future.result(timeout=30) exceptExceptionase: print(f"处理消息异常:{e}") defprocess_single_message(self, message): """处理单条消息""" try: # 模拟业务处理 time.sleep(0.001) # 记录处理日志 print(f"处理消息: Topic={message['topic']}, " f"Partition={message['partition']}, " f"Offset={message['offset']}") exceptExceptionase: print(f"处理单条消息异常:{e}") defstart_consuming(self): """开始消费消息""" print(f"开始消费主题:{self.topics}") try: whileTrue: self.consume_messages_batch() exceptKeyboardInterrupt: print("停止消费") finally: self.consumer.close() # 使用示例 if__name__ =="__main__": consumer = OptimizedKafkaConsumer( topics=['performance_test'], group_id='performance_consumer_group', bootstrap_servers=['192.168.1.11:9092','192.168.1.12:9092'] ) consumer.start_consuming()
3. 监控与运维自动化
3.1 Kafka集群监控脚本
#!/bin/bash
# Kafka集群监控脚本
KAFKA_HOME="/opt/kafka"
KAFKA_BROKERS="192.168.1.11:9092,192.168.1.12:9092,192.168.1.13:9092"
ALERT_EMAIL="admin@company.com"
LOG_FILE="/var/log/kafka_monitor.log"
# 检查Kafka集群状态
check_kafka_cluster() {
echo"$(date): 检查Kafka集群状态">>$LOG_FILE
# 检查broker列表
broker_list=$(${KAFKA_HOME}/bin/kafka-broker-api-versions.sh --bootstrap-server${KAFKA_BROKERS}2>/dev/null | grep -c"id:")
if["$broker_list"-lt 3 ];then
echo"ALERT: Kafka集群可用broker不足:$broker_list"| mail -s"Kafka Cluster Alert"$ALERT_EMAIL
echo"$(date): ALERT - 可用broker不足:$broker_list">>$LOG_FILE
fi
}
# 检查主题状态
check_topic_health() {
echo"$(date): 检查主题健康状态">>$LOG_FILE
# 获取主题列表
topics=$(${KAFKA_HOME}/bin/kafka-topics.sh --bootstrap-server${KAFKA_BROKERS}--list)
fortopicin$topics;do
# 检查主题描述
topic_desc=$(${KAFKA_HOME}/bin/kafka-topics.sh --bootstrap-server${KAFKA_BROKERS}--describe --topic$topic)
# 检查是否有离线分区
offline_partitions=$(echo"$topic_desc"| grep -c"Leader: -1")
if["$offline_partitions"-gt 0 ];then
echo"ALERT: 主题$topic有$offline_partitions个离线分区"| mail -s"Kafka Topic Alert"$ALERT_EMAIL
echo"$(date): ALERT - 主题$topic离线分区:$offline_partitions">>$LOG_FILE
fi
done
}
# 检查消费者组延迟
check_consumer_lag() {
echo"$(date): 检查消费者组延迟">>$LOG_FILE
# 获取消费者组列表
consumer_groups=$(${KAFKA_HOME}/bin/kafka-consumer-groups.sh --bootstrap-server${KAFKA_BROKERS}--list)
forgroupin$consumer_groups;do
# 获取消费者组详情
group_desc=$(${KAFKA_HOME}/bin/kafka-consumer-groups.sh --bootstrap-server${KAFKA_BROKERS}--describe --group$group)
# 检查延迟
max_lag=$(echo"$group_desc"| awk'NR>1 {print $5}'| grep -v"-"|sort-n |tail-1)
if[ -n"$max_lag"] && ["$max_lag"-gt 10000 ];then
echo"ALERT: 消费者组$group最大延迟:$max_lag"| mail -s"Kafka Consumer Lag Alert"$ALERT_EMAIL
echo"$(date): ALERT - 消费者组$group延迟过高:$max_lag">>$LOG_FILE
fi
done
}
# 收集性能指标
collect_metrics() {
echo"$(date): 收集Kafka性能指标">>$LOG_FILE
# 收集JVM指标
forbrokerin192.168.1.11 192.168.1.12 192.168.1.13;do
kafka_pid=$(ssh$broker"pgrep -f kafka")
if[ -n"$kafka_pid"];then
# 内存使用率
memory_usage=$(ssh$broker"ps -p$kafka_pid-o %mem --no-headers")
echo"$(date): Broker$broker内存使用率:$memory_usage%">>$LOG_FILE
# CPU使用率
cpu_usage=$(ssh$broker"ps -p$kafka_pid-o %cpu --no-headers")
echo"$(date): Broker$brokerCPU使用率:$cpu_usage%">>$LOG_FILE
fi
done
}
# 主监控循环
whiletrue;do
check_kafka_cluster
check_topic_health
check_consumer_lag
collect_metrics
sleep300 # 5分钟检查一次
done
3.2 自动化运维脚本
#!/usr/bin/env python3
# Kafka自动化运维脚本
importsubprocess
importjson
importsmtplib
fromemail.mime.textimportMIMEText
fromdatetimeimportdatetime
importlogging
classKafkaOperations:
def__init__(self, kafka_home, brokers):
self.kafka_home = kafka_home
self.brokers = brokers
self.logger =self.setup_logger()
defsetup_logger(self):
"""设置日志记录"""
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s',
handlers=[
logging.FileHandler('/var/log/kafka_operations.log'),
logging.StreamHandler()
]
)
returnlogging.getLogger(__name__)
defcreate_topic(self, topic_name, partitions=3, replication_factor=2):
"""创建主题"""
try:
cmd = [
f"{self.kafka_home}/bin/kafka-topics.sh",
"--bootstrap-server",self.brokers,
"--create",
"--topic", topic_name,
"--partitions",str(partitions),
"--replication-factor",str(replication_factor)
]
result = subprocess.run(cmd, capture_output=True, text=True)
ifresult.returncode ==0:
self.logger.info(f"成功创建主题:{topic_name}")
returnTrue
else:
self.logger.error(f"创建主题失败:{result.stderr}")
returnFalse
exceptExceptionase:
self.logger.error(f"创建主题异常:{e}")
returnFalse
defdelete_topic(self, topic_name):
"""删除主题"""
try:
cmd = [
f"{self.kafka_home}/bin/kafka-topics.sh",
"--bootstrap-server",self.brokers,
"--delete",
"--topic", topic_name
]
result = subprocess.run(cmd, capture_output=True, text=True)
ifresult.returncode ==0:
self.logger.info(f"成功删除主题:{topic_name}")
returnTrue
else:
self.logger.error(f"删除主题失败:{result.stderr}")
returnFalse
exceptExceptionase:
self.logger.error(f"删除主题异常:{e}")
returnFalse
defincrease_partitions(self, topic_name, new_partition_count):
"""增加分区数"""
try:
cmd = [
f"{self.kafka_home}/bin/kafka-topics.sh",
"--bootstrap-server",self.brokers,
"--alter",
"--topic", topic_name,
"--partitions",str(new_partition_count)
]
result = subprocess.run(cmd, capture_output=True, text=True)
ifresult.returncode ==0:
self.logger.info(f"成功增加主题{topic_name}分区数到{new_partition_count}")
returnTrue
else:
self.logger.error(f"增加分区失败:{result.stderr}")
returnFalse
exceptExceptionase:
self.logger.error(f"增加分区异常:{e}")
returnFalse
defrebalance_partitions(self, topic_name):
"""重新平衡分区"""
try:
# 生成重平衡计划
reassignment_file =f"/tmp/reassignment-{topic_name}.json"
# 获取当前分区分配
cmd_current = [
f"{self.kafka_home}/bin/kafka-topics.sh",
"--bootstrap-server",self.brokers,
"--describe",
"--topic", topic_name
]
current_result = subprocess.run(cmd_current, capture_output=True, text=True)
ifcurrent_result.returncode ==0:
# 生成重平衡计划
cmd_generate = [
f"{self.kafka_home}/bin/kafka-reassign-partitions.sh",
"--bootstrap-server",self.brokers,
"--topics-to-move-json-file","/tmp/topics.json",
"--broker-list","0,1,2,3",
"--generate"
]
# 执行重平衡
cmd_execute = [
f"{self.kafka_home}/bin/kafka-reassign-partitions.sh",
"--bootstrap-server",self.brokers,
"--reassignment-json-file", reassignment_file,
"--execute"
]
self.logger.info(f"开始重平衡主题:{topic_name}")
returnTrue
else:
self.logger.error(f"获取主题信息失败:{current_result.stderr}")
returnFalse
exceptExceptionase:
self.logger.error(f"重平衡异常:{e}")
returnFalse
defbackup_consumer_offsets(self, group_id):
"""备份消费者偏移量"""
try:
cmd = [
f"{self.kafka_home}/bin/kafka-consumer-groups.sh",
"--bootstrap-server",self.brokers,
"--describe",
"--group", group_id
]
result = subprocess.run(cmd, capture_output=True, text=True)
ifresult.returncode ==0:
backup_file =f"/backup/consumer_offsets_{group_id}_{datetime.now().strftime('%Y%m%d_%H%M%S')}.txt"
withopen(backup_file,'w')asf:
f.write(result.stdout)
self.logger.info(f"成功备份消费者组{group_id}偏移量到{backup_file}")
returnTrue
else:
self.logger.error(f"备份偏移量失败:{result.stderr}")
returnFalse
exceptExceptionase:
self.logger.error(f"备份偏移量异常:{e}")
returnFalse
# 使用示例
if__name__ =="__main__":
kafka_ops = KafkaOperations(
kafka_home="/opt/kafka",
brokers="192.168.1.11:9092,192.168.1.12:9092,192.168.1.13:9092"
)
# 创建主题
kafka_ops.create_topic("test_topic", partitions=6, replication_factor=3)
# 增加分区
kafka_ops.increase_partitions("test_topic",12)
# 备份消费者偏移量
kafka_ops.backup_consumer_offsets("test_consumer_group")
4. 高可用与故障恢复
4.1 集群健康检查
#!/bin/bash
# Kafka集群健康检查与自动恢复
KAFKA_HOME="/opt/kafka"
KAFKA_BROKERS="192.168.1.11:9092,192.168.1.12:9092,192.168.1.13:9092"
# 检查并修复不同步副本
check_and_fix_isr() {
echo"检查不同步副本..."
# 获取所有主题
topics=$(${KAFKA_HOME}/bin/kafka-topics.sh --bootstrap-server${KAFKA_BROKERS}--list)
fortopicin$topics;do
# 检查主题详情
topic_desc=$(${KAFKA_HOME}/bin/kafka-topics.sh --bootstrap-server${KAFKA_BROKERS}--describe --topic$topic)
# 检查ISR不足的分区
isr_issues=$(echo"$topic_desc"| grep -E"Isr:|Replicas:"| awk'{
if ($1 == "Replicas:") replicas = NF-1;
if ($1 == "Isr:") isr = NF-1;
if (isr < replicas) print "ISR不足"
}')
if [ -n "$isr_issues" ]; then
echo"主题 $topic 存在ISR不足问题,尝试修复..."
# 触发首选副本选举
${KAFKA_HOME}/bin/kafka-leader-election.sh --bootstrap-server ${KAFKA_BROKERS} --election-type preferred --topic $topic
fi
done
}
# 自动故障恢复
auto_recovery() {
echo"执行自动故障恢复..."
# 重启失败的broker
for broker in 192.168.1.11 192.168.1.12 192.168.1.13; do
if ! ssh $broker"systemctl is-active kafka" > /dev/null 2>&1;then
echo"重启broker:$broker"
ssh$broker"systemctl restart kafka"
sleep30
fi
done
# 检查并修复ISR
check_and_fix_isr
# 验证集群状态
validate_cluster_state
}
validate_cluster_state() {
echo"验证集群状态..."
# 检查所有broker是否在线
online_brokers=$(${KAFKA_HOME}/bin/kafka-broker-api-versions.sh --bootstrap-server${KAFKA_BROKERS}2>/dev/null | grep -c"id:")
if["$online_brokers"-eq 3 ];then
echo"集群恢复正常,所有broker在线"
else
echo"集群恢复失败,在线broker数量:$online_brokers"
return1
fi
}
# 执行健康检查和恢复
auto_recovery
总结
Kafka生产环境部署涉及多个关键环节:集群架构设计、性能参数调优、监控体系建设、自动化运维等。通过本文介绍的方案,运维工程师可以构建稳定、高效的Kafka集群。关键要点包括:合理的集群规模规划、科学的配置参数调优、完善的监控告警机制、可靠的故障恢复策略。在实际生产环境中,还需要根据具体业务场景进行针对性优化,持续监控和改进系统性能,确保消息队列服务的稳定性和可靠性。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
集群
+关注
关注
0文章
159浏览量
17710 -
脚本
+关注
关注
1文章
415浏览量
29339 -
kafka
+关注
关注
0文章
55浏览量
5610
原文标题:Kafka生产环境应用方案:高可用集群部署与运维实战
文章出处:【微信号:magedu-Linux,微信公众号:马哥Linux运维】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
热点推荐
基于闪存存储的Apache Kafka性能提升方法
作者:Dennis Lattka我是美光科技的首席存储解决方案工程师Dennis Lattka。这个头衔的真正含义是,我要致力于确定如何利用闪存存储改善工作负载应用的性能和结果。为此,我决定对大数
发表于 07-24 06:58
Kafka几个比较重要的配置参数
Kafka在弹性、容错性以及高吞吐量方面有着很大的优势。想要达到生产环境最优,发挥这些特性,需要我们进行一系列的配置。Kafka提供了非常多的配置属性,对于初学者而言,很容易陷入困惑。
发表于 11-04 08:10
Kafka集群环境的搭建
1、环境版本版本:kafka2.11,zookeeper3.4注意:这里zookeeper3.4也是基于集群模式部署。2、解压重命名tar -zxvf
发表于 01-05 17:55
基于臭氧的Kafka自适应调优方法ENLHS
Kafka应用在生产环境中时,除机器的硬件环境和系统平台影响其性能外,Kaka自身的配置项决定着其能否在硬件资源有限的情况下达到理想的性能,但人为修改和调优配置项的效率极差。海量数据发
发表于 05-13 11:39
•8次下载
Kafka的概念及Kafka的宕机
问题要从一次Kafka的宕机开始说起。 笔者所在的是一家金融科技公司,但公司内部并没有采用在金融支付领域更为流行的 RabbitMQ ,而是采用了设计之初就为日志处理而生的 Kafka ,所以我一直
Kafka 的简介
1 kafka简介 2 为什么要用消息系统 3 kafka基础知识 4 kafka集群架构 5 总结 1 kafka简介 其主要设计目标如下: 以时间复杂度为O(1)的方式提供
物通博联5G-kafka工业网关实现kafka协议对接到云平台
Kafka协议是一种基于TCP层的网络协议,用于在分布式消息传递系统Apache Kafka中发送和接收消息。Kafka协议定义了客户端和服务器之间的通信方式和数据格式,允许客户端发送消息到K
Spring Kafka的各种用法
最近业务上用到了Spring Kafka,所以系统性的探索了下Spring Kafka的各种用法,发现了很多实用的特性,下面介绍下Spring Kafka的消息重试机制。 0. 前言 原生
Kafka架构技术:Kafka的架构和客户端API设计
Kafka 给自己的定位是事件流平台(event stream platform)。因此在消息队列中经常使用的 "消息"一词,在 Kafka 中被称为 "事件"。



评论