 Kafka的概念及Kafka的宕机
Kafka的概念及Kafka的宕机

问题要从一次Kafka的宕机开始说起。
笔者所在的是一家金融科技公司,但公司内部并没有采用在金融支付领域更为流行的 RabbitMQ ,而是采用了设计之初就为日志处理而生的 Kafka ,所以我一直很好奇Kafka的高可用实现和保障。从 Kafka 部署后,系统内部使用的 Kafka 一直运行稳定,没有出现不可用的情况。
但最近系统测试人员常反馈偶有Kafka消费者收不到消息的情况,登陆管理界面发现三个节点中有一个节点宕机挂掉了。但是按照高可用的理念,三个节点还有两个节点可用怎么就引起了整个集群的消费者都接收不到消息呢?
要解决这个问题,就要从 Kafka 的高可用实现开始讲起。
Kafka 的多副本冗余设计
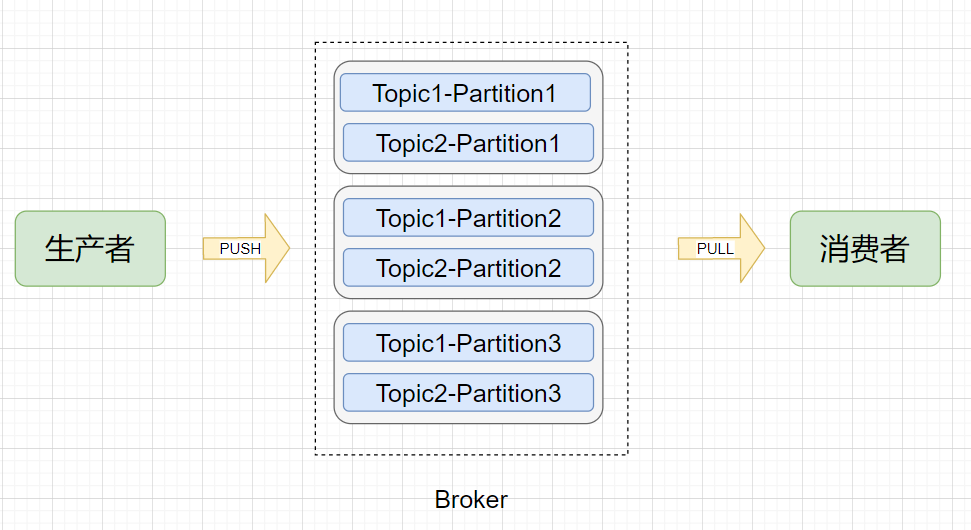
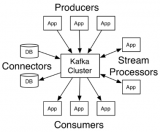
不管是传统的基于关系型数据库设计的系统,还是分布式的如 zookeeper 、 redis 、 Kafka 、 HDFS 等等,实现高可用的办法通常是采用冗余设计,通过冗余来解决节点宕机不可用问题。首先简单了解 Kafka 的几个概念:
逻辑模型
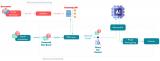
Broker (节点):Kafka 服务节点,简单来说一个 Broker 就是一台 Kafka 服务器,一个物理节点。
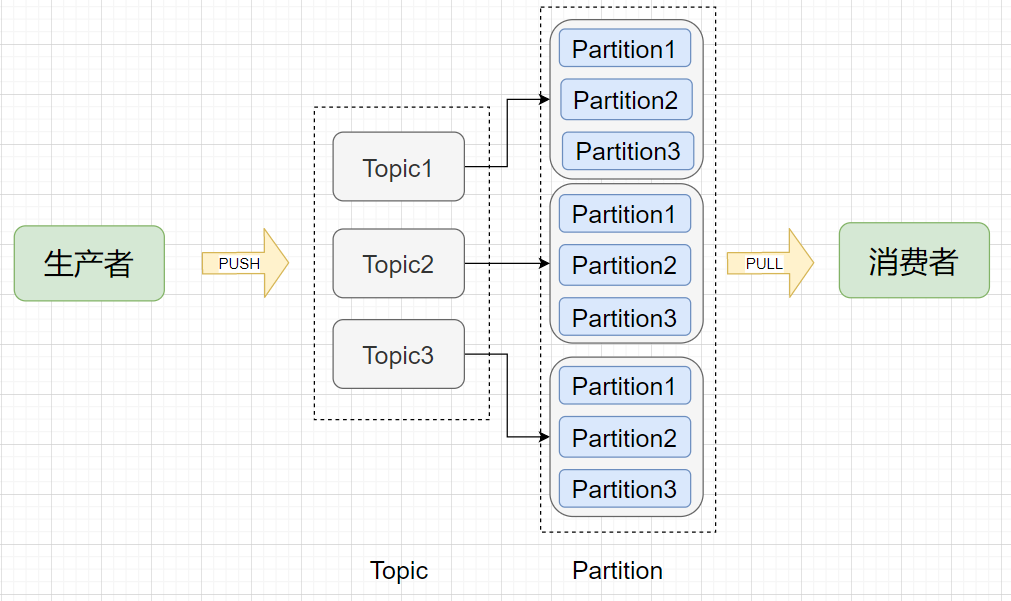
Topic (主题):在 Kafka 中消息以主题为单位进行归类,每个主题都有一个 Topic Name ,生产者根据 Topic Name 将消息发送到特定的 Topic,消费者则同样根据 Topic Name 从对应的 Topic 进行消费。
Partition (分区):Topic (主题)是消息归类的一个单位,但每一个主题还能再细分为一个或多个 Partition (分区),一个分区只能属于一个主题。主题和分区都是逻辑上的概念,举个例子,消息1和消息2都发送到主题1,它们可能进入同一个分区也可能进入不同的分区(所以同一个主题下的不同分区包含的消息是不同的),之后便会发送到分区对应的Broker节点上。
Offset (偏移量):分区可以看作是一个只进不出的队列(Kafka只保证一个分区内的消息是有序的),消息会往这个队列的尾部追加,每个消息进入分区后都会有一个偏移量,标识该消息在该分区中的位置,消费者要消费该消息就是通过偏移量来识别。
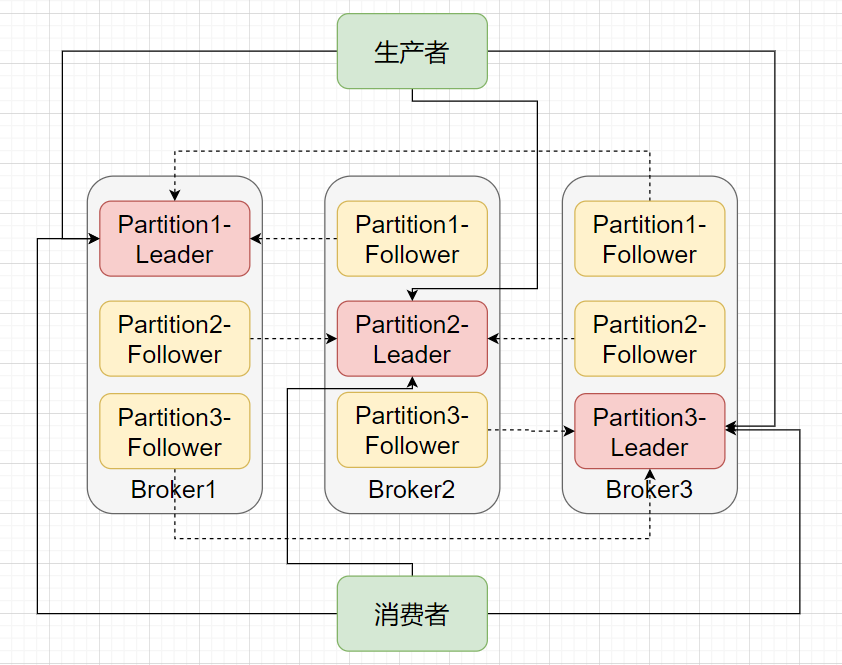
就这么简单?是的,基于上面这张多副本架构图就实现了 Kafka 的高可用。当某个 Broker 挂掉了,甭担心,这个 Broker 上的 Partition 在其他 Broker 节点上还有副本。你说如果挂掉的是 Leader 怎么办?那就在 Follower中在选举出一个 Leader 即可,生产者和消费者又可以和新的 Leader 愉快地玩耍了,这就是高可用。
你可能还有疑问,那要多少个副本才算够用?Follower 和 Leader 之间没有完全同步怎么办?一个节点宕机后 Leader 的选举规则是什么?
直接抛结论:
多少个副本才算够用?
副本肯定越多越能保证 Kafka 的高可用,但越多的副本意味着网络、磁盘资源的消耗更多,性能会有所下降,通常来说副本数为3即可保证高可用,极端情况下将 replication-factor 参数调大即可。
Follower 和 Lead 之间没有完全同步怎么办?
Follower 和 Leader 之间并不是完全同步,但也不是完全异步,而是采用一种 ISR机制( In-Sync Replica)。每个Leader会动态维护一个ISR列表,该列表里存储的是和Leader基本同步的Follower。如果有 Follower 由于网络、GC 等原因而没有向 Leader 发起拉取数据请求,此时 Follower 相对于 Leader 是不同步的,则会被踢出 ISR 列表。所以说,ISR 列表中的 Follower 都是跟得上 Leader 的副本。
一个节点宕机后 Leader 的选举规则是什么?
分布式相关的选举规则有很多,像 Zookeeper的 Zab 、 Raft、 Viewstamped Replication、微软的 PacificA 等。而 Kafka 的 Leader 选举思路很简单,基于我们上述提到的 ISR 列表,当宕机后会从所有副本中顺序查找,如果查找到的副本在ISR列表中,则当选为Leader。另外还要保证前任Leader已经是退位状态了,否则会出现脑裂情况(有两个Leader)。怎么保证?Kafka 通过设置了一个 controller 来保证只有一个 Leader。
Ack 参数决定了可靠程度
另外,这里补充一个面试考Kafka高可用必备知识点:request.required.asks 参数。
Asks 这个参数是生产者客户端的重要配置,发送消息的时候就可设置这个参数。该参数有三个值可配置:0、1、All 。
第一种是设为0,意思是生产者把消息发送出去之后,之后这消息是死是活咱就不管了,有那么点发后即忘的意思,说出去的话就不负责了。不负责自然这消息就有可能丢失,那就把可用性也丢失了。
第二种是设为1,意思是生产者把消息发送出去之后,这消息只要顺利传达给了Leader,其他Follower有没有同步就无所谓了。存在一种情况,Leader刚收到了消息,Follower还没来得及同步Broker就宕机了,但生产者已经认为消息发送成功了,那么此时消息就丢失了。
设为1是Kafka的默认配置,可见Kafka的默认配置也不是那么高可用,而是对高可用和高吞吐量做了权衡折中。
第三种是设为All(或者-1)
意思是生产者把消息发送出去之后,不仅Leader要接收到,ISR列表中的Follower也要同步到,生产者才会任务消息发送成功。
进一步思考, Asks=All 就不会出现丢失消息的情况吗?答案是否。当ISR列表只剩Leader的情况下, Asks=All 相当于 Asks=1 ,这种情况下如果节点宕机了,还能保证数据不丢失吗?因此只有在 Asks=All 并且有ISR中有两个副本的情况下才能保证数据不丢失。
解决问题
绕了一大圈,了解了Kafka的高可用机制,终于回到我们一开始的问题本身, Kafka 的一个节点宕机后为什么不可用?
我在开发测试环境配置的 Broker 节点数是3, Topic 是副本数为3, Partition 数为6, Asks 参数为1。
当三个节点中某个节点宕机后,集群首先会怎么做?没错,正如我们上面所说的,集群发现有Partition的Leader失效了,这个时候就要从ISR列表中重新选举Leader。如果ISR列表为空是不是就不可用了?并不会,而是从Partition存活的副本中选择一个作为Leader,不过这就有潜在的数据丢失的隐患了。
所以,只要将Topic副本个数设置为和Broker个数一样,Kafka的多副本冗余设计是可以保证高可用的,不会出现一宕机就不可用的情况(不过需要注意的是Kafka有一个保护策略,当一半以上的节点不可用时Kafka就会停止)。那仔细一想,Kafka上是不是有副本个数为1的Topic?
问题出在了 __consumer_offset 上, __consumer_offset 是一个 Kafka 自动创建的 Topic,用来存储消费者消费的 offset (偏移量)信息,默认 Partition 数为50。而就是这个Topic,它的默认副本数为1。如果所有的 Partition 都存在于同一台机器上,那就是很明显的单点故障了!当将存储 __consumer_offset 的 Partition 的 Broker 给 Kill 后,会发现所有的消费者都停止消费了。这个问题怎么解决?
第一点 ,需要将 __consumer_offset 删除,注意这个Topic时Kafka内置的Topic,无法用命令删除,我是通过将 logs 删了来实现删除。
第二点 ,需要通过设置 offsets.topic.replication.factor 为3来将 __consumer_offset 的副本数改为3。通过将 __consumer_offset 也做副本冗余后来解决某个节点宕机后消费者的消费问题。
最后,关于为什么 __consumer_offset 的 Partition 会出现只存储在一个 Broker 上而不是分布在各个 Broker 上感到困惑。
作者:JanusWoo
来源:https://juejin.im/post/6874957625998606344
编辑:jq
-
ISR
+关注
关注
0文章
38浏览量
15115 -
HDFS
+关注
关注
1文章
32浏览量
10067 -
kafka
+关注
关注
0文章
54浏览量
5535 -
zookeeper
+关注
关注
0文章
34浏览量
4074
原文标题:探究Kafka高可用实现
文章出处:【微信号:aming_linux,微信公众号:阿铭linux】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
Cloudflare宕机!全球网络崩了
Kafka生产环境应用方案
MCU+CPLD 联合编程(概念及流程)
工业物联网平台是什么(概念及功能)
电机概念及分类介绍(可下载)
工业物联网平台的概念及功能解析
探索未来算力新纪元——带你体验 Kafka、Zookeeper 集群安装
华为云 FlexusX 实例下的 Kafka 集群部署实践与性能优化
docker 部署 kafka 及 ui 搭建
宝藏级微服务架构工具合集
超详细“零”基础kafka入门篇
RAG的概念及工作原理





 工商网监
工商网监
评论