 NVMe高速传输却不用XDMA设计之1
NVMe高速传输却不用XDMA设计之1

NVMe IP放弃XDMA原因
选用XDMA做NVMe IP的关键传输模块,可以加速IP的设计,但是XDMA对于开发者来说,还是不方便,原因是它就象一个黑匣子,调试也非一番周折,尤其是后面PCIe4.0升级。因此决定直接采用PCIe设计,虽然要费一番周折,但是目前看,还是值得的,uvm验证也更清晰。
PCIe 加速模块设计
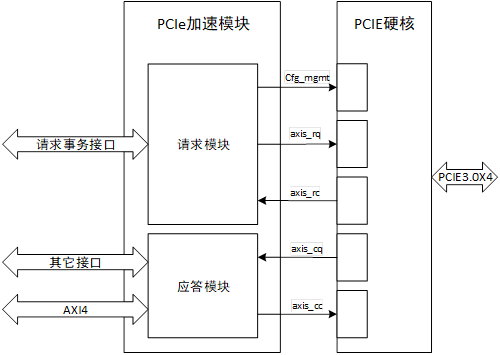
PCIe 加速模块负责处理PCIe事务层,并将其与NVMe功能和AXI接口直接绑定。如图1所示,PCIe加速模块按照请求发起方分为请求模块和应答模块。请求模块负责将内部请求事务转换为配置管理接口信号或axis请求方请求接口信号(axis_rq),以及解析 axis 请求方完成接口信号(axis_rc);应答模块负责接收axis完成方请求接口信号(axis_cq),将请求内容转换为AXI4接口信号或其它内部信号做进一步处理,同时将应答事务通过axis完成方完成接口axis_cc)发送给PCIE集成块.
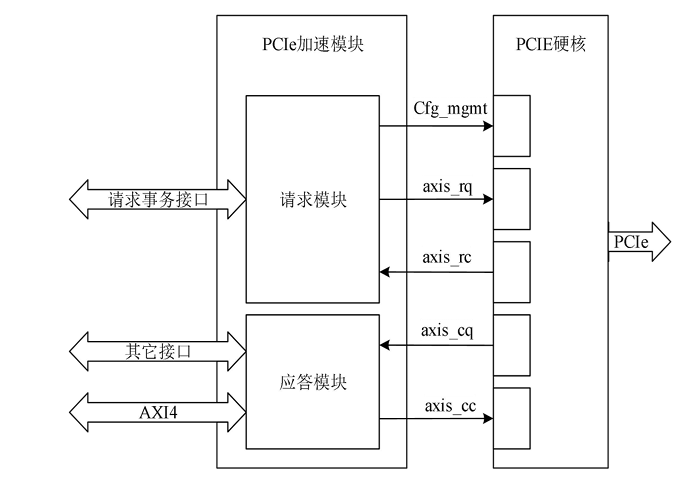
图1 PCIe加速模块结构和连接关系图
PCIe 加速模块不仅承担了TLP与其它接口信号的转换功能,也是降低传输延迟增加吞吐量的核心部件。接下来分别对请求模块和应答模块的结构设计进行具体分析。
PCIe 请求模块设计
请求模块的具体任务是将系统的请求转换成为axis接口形式的TLP或配置管理接口信号。这些请求主要包含初始化配置请求和门铃写请求。初始化配置请求由初始化模块发起,当配置请求的总线号为0时,请求通过Cfg_mgmt接口发送给PCIE集成块;当配置请求的总线号不为0时,请求以PCIe配置请求TLP的格式从axis_rq接口发送到PCIE集成块,然后由硬核驱动数据链路层和物理层通过PCIe接口发送给下游设备,下游设备的反馈通过axis_rc接口以Cpl或CplD的形式传回。门铃写请求由NVMe控制模块发起,请求以PCIe存储器写请求TLP的格式从axis_rq接口交由PCIE集成块发送。
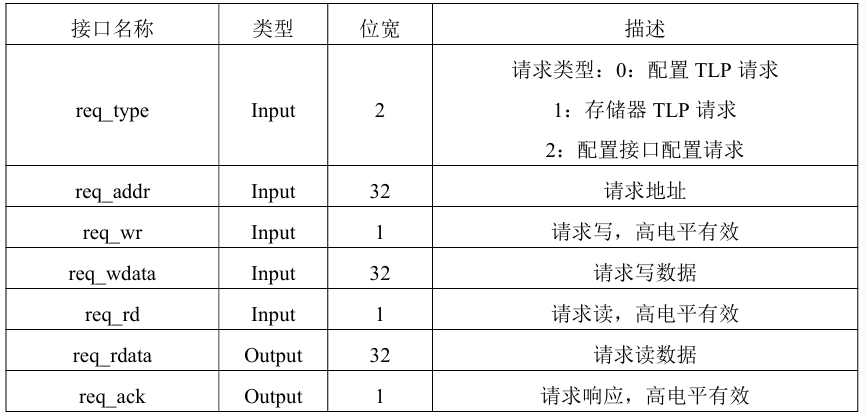
由于发起请求的模块存在多个,并且在时间顺序上初始化模块先占用请求,NVMe控制模块后占用请求,不会出现请求的竞争,因此设置一条内部请求总线用于发起请求和接收响应,该请求总线也作为请求模块的上游接口。请求模块的请求总线接口说明如表1所示。无论是配置请求还是门铃写请求,请求的数据长度都只有一个双字,因此设置读写数据位宽均为32比特。
表1 请求总线接口
在接收到请求总线接口的请求事务后,当请求类型的值为0时,表示通过PCIE集成块的配置管理接口发送请求,由于请求接口的接口和时序与配置管理接口基本一致,因此此时直接将请求接口信号驱动到配置管理接口完成请求的发送,请求读数据和响应也通过选通器连接到配置管理接口。当请求类型值不为0时,则需要将请求转换为TLP以axis接口形式发送,这一过程通过请求状态机实现,请求状态机的状态转移图如图2所示。
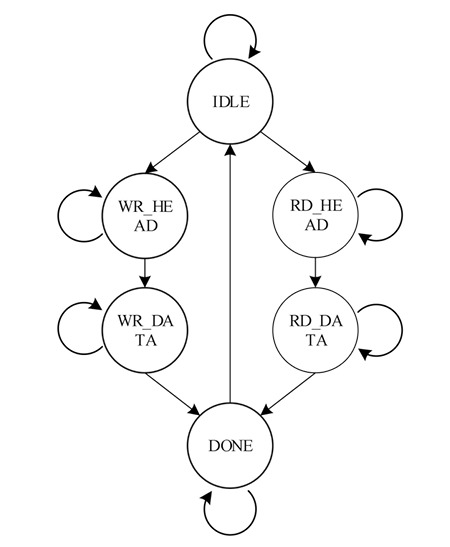
图2 PCIe请求状态转移图
各状态说明如下:
IDLE:空闲状态,复位后的初始状态。当请求写有效或请求读有效,且请求类型值不为0时,如果请求写有效跳转到WR_HEAD状态,如果请求读有效或读写同时有效跳转到RD_HEAD状态,否则保持IDLE状态。实际的上层设计中读写请求不会同时发生,这里的状态跳转条件增加了读优先设计,从而避免异常情况的出现。
WR_HEAD:请求写TLP头发送状态。该状态下根据请求类型、请求地址组装写请求的TLP报文头部,并将报文头部通过axis_rq接口发送。当axis_rq接口握手时跳转到WR_DATA状态。
WR_DATA:请求写TLP数据发送状态。该状态下将请求写的数据通过axis_rq接口发送,当axis_rq接口握手时跳转到DONE状态。
RD_HEAD:请求读TLP头发送状态。该状态下组装读请求TLP报头通过axis_rq接口发送,当接口握手时跳转到RD_DATA状态。
RD_DATA:请求读CplD接收状态。该状态下监测axis_rc接口信号,当出现数据传输有效时,启动握手并接受数据,然后跳转到DONE状态。
DONE:请求完成状态。该状态下使能req_ack请求响应信号,如果是读请求同时将RD_DATA状态下接收的数据发送到req_rdata请求读数据接口。一个时钟周期后回到IDLE状态。
-
接口
+关注
关注
33文章
9602浏览量
157632 -
高速传输
+关注
关注
0文章
46浏览量
9321 -
nvme
+关注
关注
0文章
300浏览量
23915
发布评论请先 登录
NVMe IP高速传输却不依赖便利的XDMA设计之三:系统架构
NVMe IP高速传输却不依赖XDMA设计之五:DMA 控制单元设计
NVMe高速传输之摆脱XDMA设计之十:NVMe初始化状态机设计
NVMe高速传输之摆脱XDMA设计18:UVM验证平台
NVMe高速传输之摆脱XDMA设计14: PCIe应答模块设计
NVMe高速传输之摆脱XDMA设计17:PCIe加速模块设计
NVMe高速传输之摆脱XDMA设计20: PCIe应答模块设计
NVMe高速传输之摆脱XDMA设计30: NVMe 设备模型设计
NVMe IP over PCIe 4.0:摆脱XDMA,实现超高速!
NVMe IP高速传输却不依赖XDMA设计之五:DMA 控制单元设计
NVMe IP高速传输却不依赖XDMA设计之八:系统初始化
NVMe IP高速传输却不依赖XDMA设计之九:队列管理模块(上)
NVMe高速传输之摆脱XDMA设计17:PCIe加速模块设计



评论