 爱芯通元NPU适配Qwen2.5-VL-3B视觉多模态大模型
爱芯通元NPU适配Qwen2.5-VL-3B视觉多模态大模型

Qwen2.5-VL:the new flagship vision-language model of Qwen and also a significant leap from the previous Qwen2-VL.
爱芯通元:以算子为原子指令集的AI计算处理器。高效支持混合精度算法设计和Transformer,为大模型(DeepSeek、Qwen、MiniCPM……)在“云—边—端”的AI应用提供强力基础。
https://www.axera-tech.com/Skill/166.html
TLDR
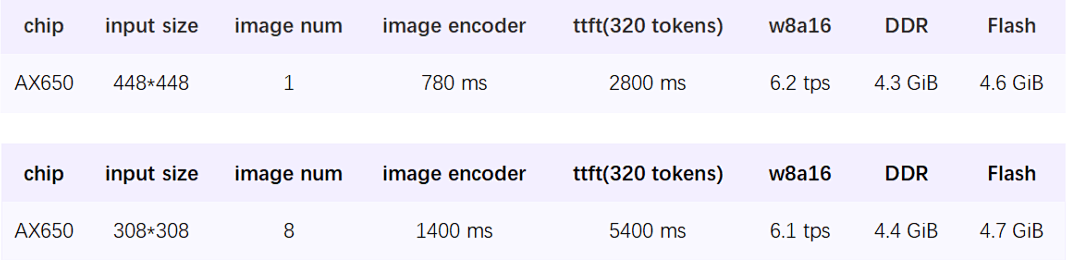
背景
熟悉爱芯通元NPU的网友很清楚,从去年开始我们在端侧多模态大模型适配上一直处于主动紧跟的节奏。先后适配了国内最早开源的多模态大模MiniCPM V 2.0,上海人工智能实验室的书生多模态大模型 InternVL2.5-1B/8B/MPO,Huggingface推出的全球最小多模态大模型SmloVLM-256M。为工业界提供了离线部署多模态大模型(VLM)实现图片本地高效率理解的可行性方案。
从本文开始,我们将逐渐探索基于VLM的视频理解方案,让端侧/边缘设备智能化升级有更大的想象空间。
本文基于Qwen2.5-VL-3B走马观花介绍VLM是如何从图片理解(Image Understand)延伸到视频理解(Video Understand),并展示基于爱芯通元NPU平台的最新适配情况,最后“脑洞”一些可能存在的产品落地场景。
Qwen2.5-VL
Qwen2.5-VL是由通义千问团队开源的视觉多模态大模型。到目前为止已经开源了3B、7B、32B、72B四种尺度,满足不同算力设备灵活部署。
官方链接:https://github.com/QwenLM/Qwen2.5-VL
Huggingface:https://huggingface.co/Qwen/Qwen2.5-VL-3B-Instruct
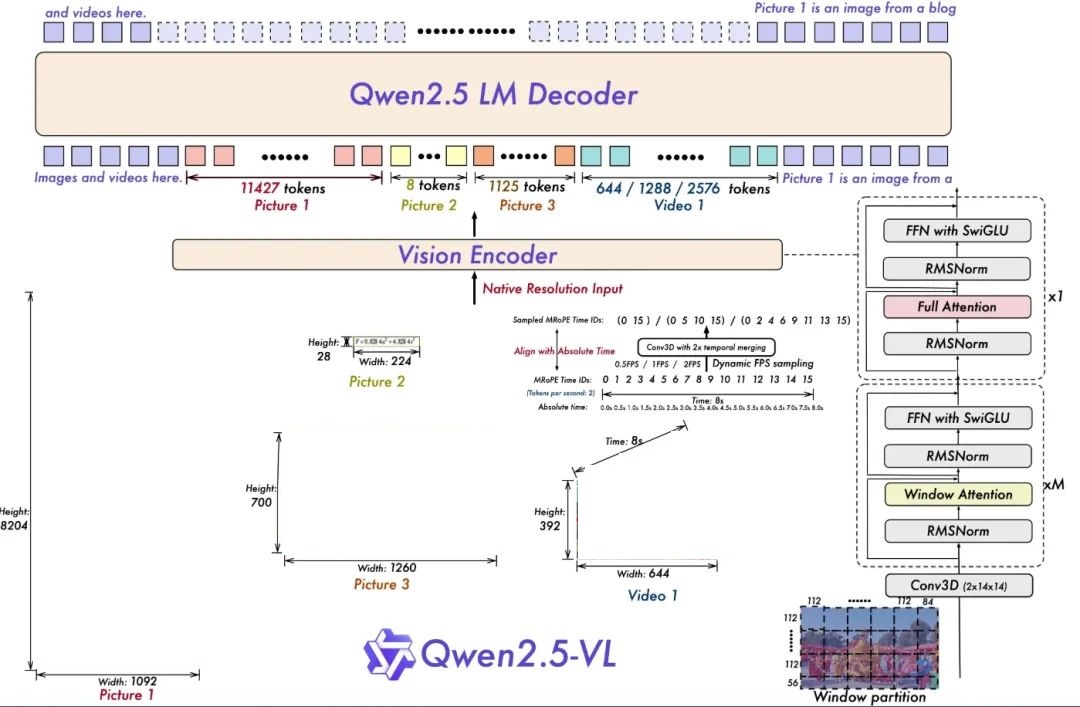
Qwen2.5-VL是Qwen2-VL的版本更新,以下功能更新展示了Qwen2.5-VL在视觉-语言处理领域的强大功能和广泛应用前景。
增强功能
视觉理解能力:Qwen2.5-VL不仅擅长识别常见的物体如花、鸟、鱼和昆虫,还能高效地分析图像中的文本、图表、图标、图形和布局;
作为视觉代理的能力:该模型能够直接充当一个视觉代理,具备推理能力和动态工具指导能力,适用于计算机和手机的使用;
长视频理解和事件捕捉:Qwen2.5-VL能够理解超过一小时的视频内容,并新增了通过精确定位相关视频段来捕捉事件的能力;
不同格式的视觉定位能力:该模型能通过生成边界框或点准确地在图像中定位对象,并提供包含坐标和属性的稳定JSON输出;
结构化输出:针对发票扫描件、表格、表单等数据,Qwen2.5-VL支持其内容的结构化输出,这在金融、商业等领域具有重要应用价值。
架构更新
为视频理解进行的动态分辨率和帧率训练:通过采用动态FPS采样将动态分辨率扩展到时间维度,使模型能够在各种采样率下理解视频。相应地,我们在时间维度上用ID和绝对时间对齐更新了mRoPE,让模型能够学习时间序列和速度,最终获得定位特定时刻的能力。
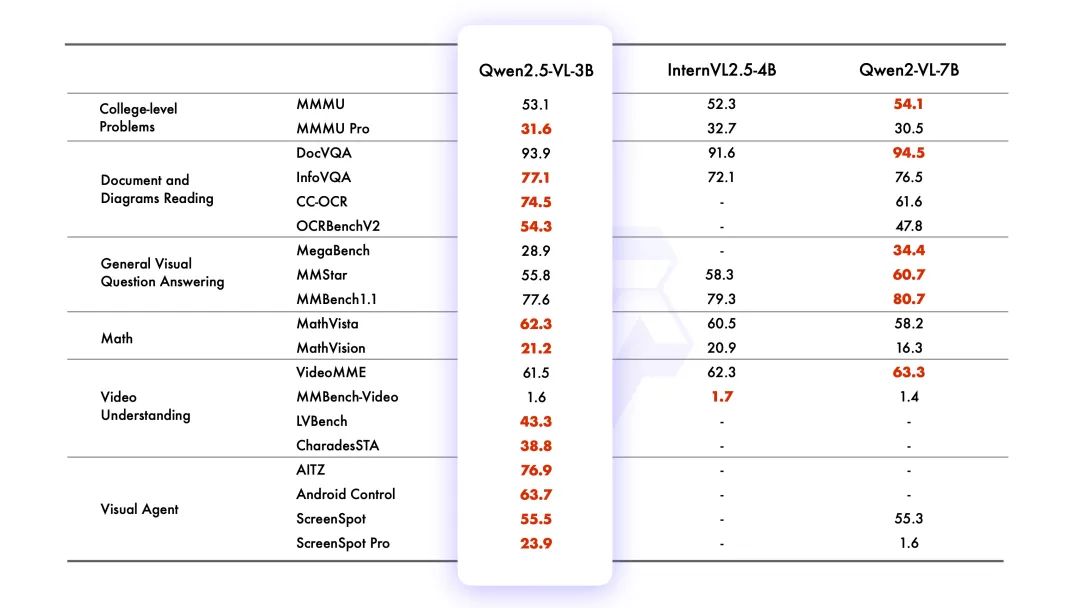
跑分情况
爱芯通元
爱芯通元是爱芯元智自研的NPU IP品牌。本文基于内置爱芯通元NPUv3架构的爱芯派Pro(AX650N)进行示例展示。
爱芯派Pro
搭载爱芯元智第三代高能效比智能视觉芯片AX650N。集成了八核Cortex-A55 CPU,18TOPs@INT8 NPU以及H.264、H.265 编解码的VPU。接口方面,AX650N支持64bit LPDDR4x,多路MIPI输入,千兆Ethernet、USB、以及HDMI 2.0b输出,并支持32路1080p@30fps解码内置高算力和超强编解码能力,满足行业对高性能边缘智能计算的需求。通过内置多种深度学习算法,实现视觉结构化、行为分析、状态检测等应用,高效率支持Transformer结构的大模型。提供丰富的开发文档,方便用户进行二次开发。

模型转换
我们在Huggingface上提供了预编译好的模型,建议直接使用。
如果有朋友想深入研究如何从Huggingface原生仓库的safetytensor模型使用Pulsar2 NPU工具链转换生成axmodel模型,请参考我们的开源项目:
https://github.com/AXERA-TECH/Qwen2.5-VL-3B-Instruct.axera
模型部署
预编译文件
从Huggingface上获取
https://huggingface.co/AXERA-TECH/Qwen2.5-VL-3B-Instruct
pipinstall -U huggingface_hub exportHF_ENDPOINT=https://hf-mirror.com huggingface-cli download --resume-download AXERA-TECH/Qwen2.5-VL-3B-Instruct --local-dir Qwen2.5-VL-3B-Instruct
文件说明
root@ax650:/mnt/qtang/llm-test/Qwen2.5-VL-3B-Instruct# tree -L 1 . |-- image |-- main |-- python |-- qwen2_5-vl-3b-image-ax650 |-- qwen2_5-vl-3b-video-ax650 |-- qwen2_5-vl-tokenizer |-- qwen2_tokenizer_image_448.py |-- qwen2_tokenizer_video_308.py |-- run_qwen2_5_vl_image.sh |-- run_qwen2_5_vl_video.sh `-- video
qwen2_5-vl-3b-image-ax650:存放图片理解的axmodel文件
qwen2_5-vl-3b-video-ax650:存放视频理解的axmodel文件
qwen2_tokenizer_image_448.py:适用于图片理解的tokenizer解析服务
run_qwen2_5_vl_image.sh:图片理解示例的执行脚本
准备环境
使用transformer库实现tokenizer解析服务。
pipinstall transformers==4.41.1
图片理解示例
先启动适用于图片理解任务的tokenizer解析服务。
python3qwen2_tokenizer_image_448.py --port12345
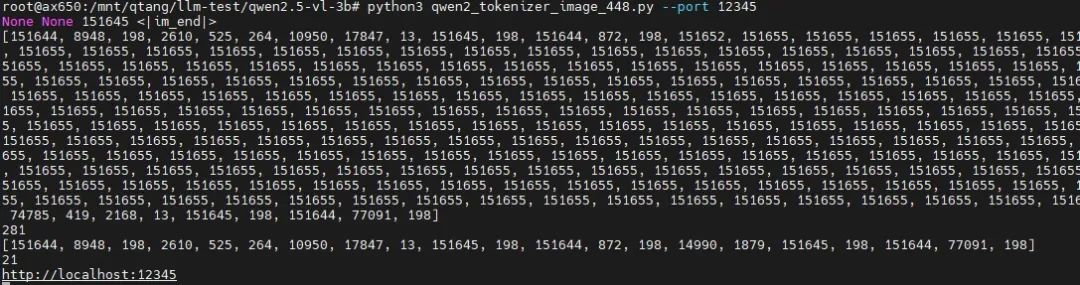
运行图片理解示例
./run_qwen2_5_vl_image.sh
输入图片
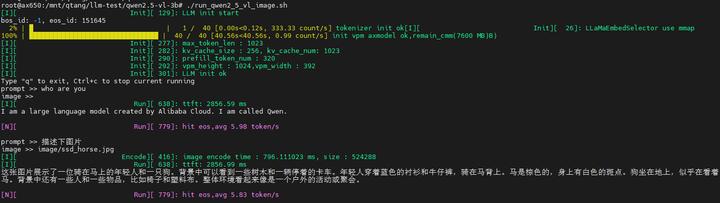
输入文本(prompt):描述下图片
输出结果
输入文本(prompt):目标检测,穿着蓝色衣服的人,输出概率最高的一个结果
输出结果

将原始图片resize到448x448分辨率后,使用返回的坐标信息[188, 18, 311, 278],手动画框结果还是挺准的。
视频理解示例
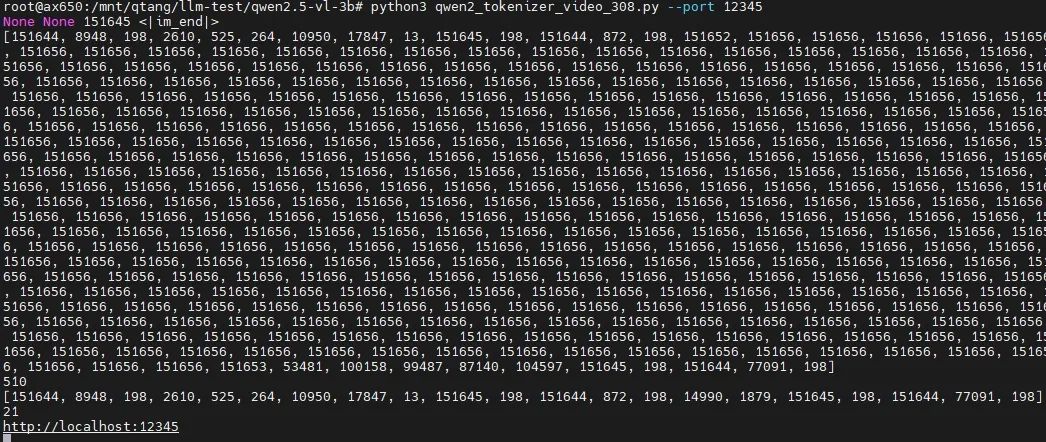
提前将从某一段视频抽取适当时间戳的8帧。先启动适用于视频理解任务的tokenizer解析服务。
pythonqwen2_tokenizer_video_308.py --port12345
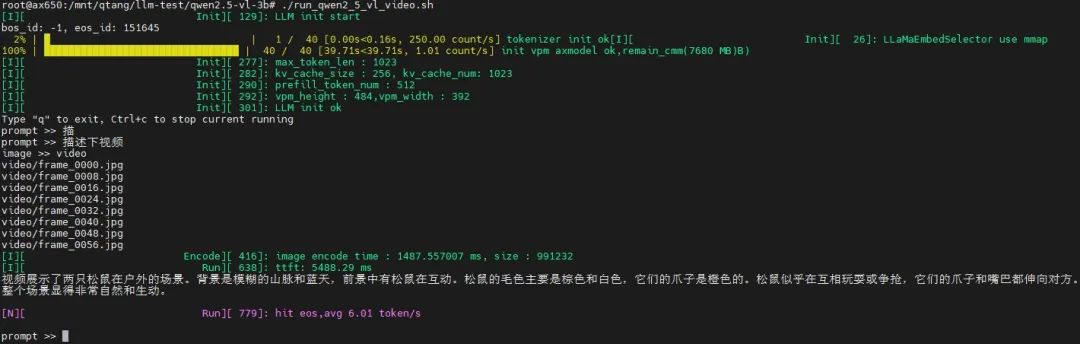
运行视频理解示例
./run_qwen2_5_vl_video.sh
输入视频
输入文本(prompt):描述下视频
输出结果
应用场景探讨
视频理解能结合视频中时间序列上的信息。能够更佳准确的理解真实世界的行为语义。
家庭场景:老人摔倒,烟火检测
工业场景:缺陷检测,危险行为检测
车载场景:驾舱内外环境感知
其他场景:穿戴式视觉辅助设备
总结
随着年初DeepSeek破圈,普通大众已经接受大模型与日常生活中的万事万物进行融合,单纯的语言类大模型已经无法满足大众的需求,多模态大模型、全模态大模型已经成为今年的主流。
爱芯通元NPU结合原生支持Transformer、高能效比、易用性等技术优势,将积极适配业界优秀的多模态大模型,提供端&边大模型高效部署的软硬件整体解决方案。推动“普惠AI造就美好生活”。
-
处理器
+关注
关注
68文章
20332浏览量
255011 -
AI
+关注
关注
91文章
41115浏览量
302607 -
开源
+关注
关注
3文章
4346浏览量
46443 -
NPU
+关注
关注
2文章
386浏览量
21346 -
大模型
+关注
关注
2文章
3771浏览量
5273
原文标题:爱芯分享 | 爱芯通元NPU适配Qwen2.5-VL-3B
文章出处:【微信号:爱芯元智AXERA,微信公众号:爱芯元智AXERA】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
爱芯元智边缘AI芯片AX8850完成Qwen3-VL多模态大模型适配

《电子发烧友电子设计周报》聚焦硬科技领域核心价值 第9期:2025.04.21--2025.04.25
基于米尔瑞芯微RK3576开发板的Qwen2-VL-3B模型NPU多模态部署评测
阿里云开源视觉语言大模型Qwen-VL ,支持图文双模态输入
通义千问发布第二代视觉语言模型Qwen2-VL
PerfXCloud重磅升级 阿里开源最强视觉语言模型Qwen2-VL-7B强势上线!
利用英特尔OpenVINO在本地运行Qwen2.5-VL系列模型
基于MindSpeed MM玩转Qwen2.5VL多模态理解模型

后摩智能NPU适配通义千问Qwen3系列模型
Qwen3-VL 4B/8B全面适配,BM1684X成边缘最佳部署平台!

天数智芯完成阿里云通义千问Qwen3.5系列多模态模型全量适配
海光DCU完成Qwen3.5多模态MoE模型全量适配
海光信息DCU平台适配阿里通义Qwen3.6-35B-A3B大模型
沐曦股份Day 0适配阿里千问Qwen3.6-35B-A3B大模型




评论