 边缘计算+无点表=?深控技术工业数采网关的本地化数据处理逻辑
边缘计算+无点表=?深控技术工业数采网关的本地化数据处理逻辑

在工业现场,数据洪流正以指数级增长——某风电场的单台机组每秒产生20,000+数据点,若将所有原始数据上传云端,每月将产生47TB的流量成本。深控技术工业数据采集网关通过边缘计算引擎与无点表技术的深度融合,实现了"采集即处理"的革命性突破,让数据在源头完成价值提纯。
一、传统云端处理模式的三大死穴
通过某汽车厂的真实故障分析,暴露传统架构的致命缺陷:
| 痛点维度 | 云端处理模式 | 引发的生产事故案例 |
|---|---|---|
| 传输延迟 | 平均往返延迟≥200ms | 某冲压机异常检测滞后导致模具损坏(损失¥380万) |
| 带宽成本 | 4G网络流量成本¥0.3/MB | 某矿场月均流量费超¥12万 |
| 数据冗余 | 有效数据占比≤15% | 某注塑机72%的稳态数据消耗存储资源 |
核心结论:工业现场70%的数据决策需在50ms内完成,这是传统架构无法跨越的鸿沟。
二、深控技术不需要点表的工业数采网关的边缘计算技术栈
1. 三层数据处理架构
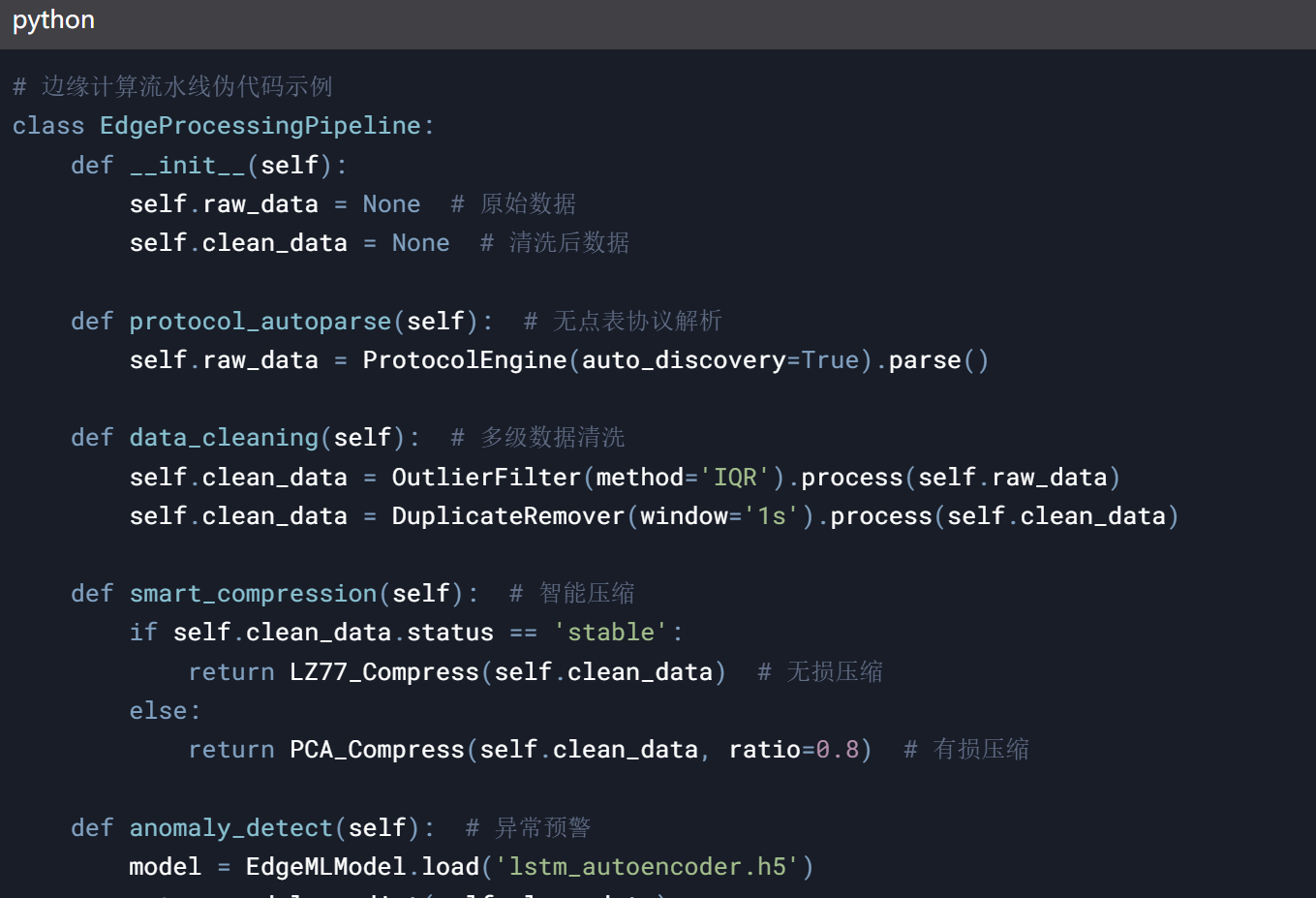
2. 关键技术突破点
(1)自适应数据清洗引擎
多级过滤机制:
(2)智能数据压缩算法
| 数据类型 | 压缩策略 | 压缩率 | 精度损失 |
|---|---|---|---|
| 时序传感数据 | 改进型旋转门算法 | 85% | ≤0.1% |
| 设备日志 | LZMA流式压缩 | 92% | 0 |
| 视频流 | 关键帧抽取+H.265编码 | 79% | 视觉无损 |
(3)边缘侧异常预警模型
轻量化AI推理框架:
模型大小:≤8MB(适配ARM Cortex-A53处理器)
推理速度:≤15ms(LSTM-Autoencoder异常检测模型)
自学习机制:

其中α=0.7为遗忘因子,μ/σ为滑动窗口统计量
三、钢铁行业实战:从数据洪流到价值密度
场景:高炉铁水温度监测优化
传统方案痛点:
每秒采集2000个温度点,日数据量172亿条
云端处理导致控制指令延迟高达300ms
深控技术网关方案:
1、边缘预处理:
数据清洗:剔除传感器失效导致的-9999异常值
特征提取:计算温度梯度ΔT/Δt、区域方差σ²
数据压缩:保留关键特征,体积缩减89%
2、本地决策:
实时预警:当ΔT>15℃/s时触发喷淋降温
动态采样:异常期间采样率从1Hz提升至100Hz
3、成果对比:
| 指标 | 原方案 | 深控方案 | 提升幅度 |
|---|---|---|---|
| 数据传输量 | 2.4TB/天 | 260GB/天 | -89% |
| 异常响应速度 | 320ms | 18ms | +94% |
| 焦炭消耗 | 42kg/吨铁 | 38kg/吨铁 | 年省¥860万 |
四、军工级可靠性设计
边缘计算容错机制
1、双核异构架构:
实时核:Cortex-R5处理控制指令(ASIL-D级)
计算核:Cortex-A72运行AI模型
2、断电保护实测:

3、数据完整性:100%(对比传统方案78%)
深控技术工程师建议:当您的业务符合以下特征时,边缘计算价值将倍增: ✅ 延迟敏感型控制 ✅ 高密度数据场景 ✅ 网络条件不稳定
审核编辑 黄宇
-
智能网关
+关注
关注
6文章
958浏览量
51975 -
边缘计算
+关注
关注
22文章
3580浏览量
53804
发布评论请先 登录
欧姆龙FINS TCP点表监听-SK-PLC 工业边缘数采网关


打造本地化智能的“最强大脑”, 米尔RK3576 AI边缘计算盒

数据采集网关的边缘计算功能体现在哪方面
工业系统为什么需要边缘计算网关
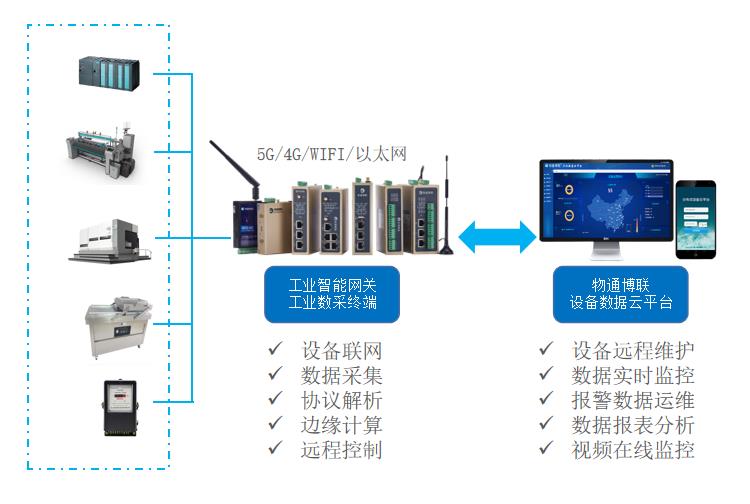
边缘计算网关+工业互联网平台有什么应用
边缘计算 + 工控一体机:如何实现工业数据实时处理与本地化决策?
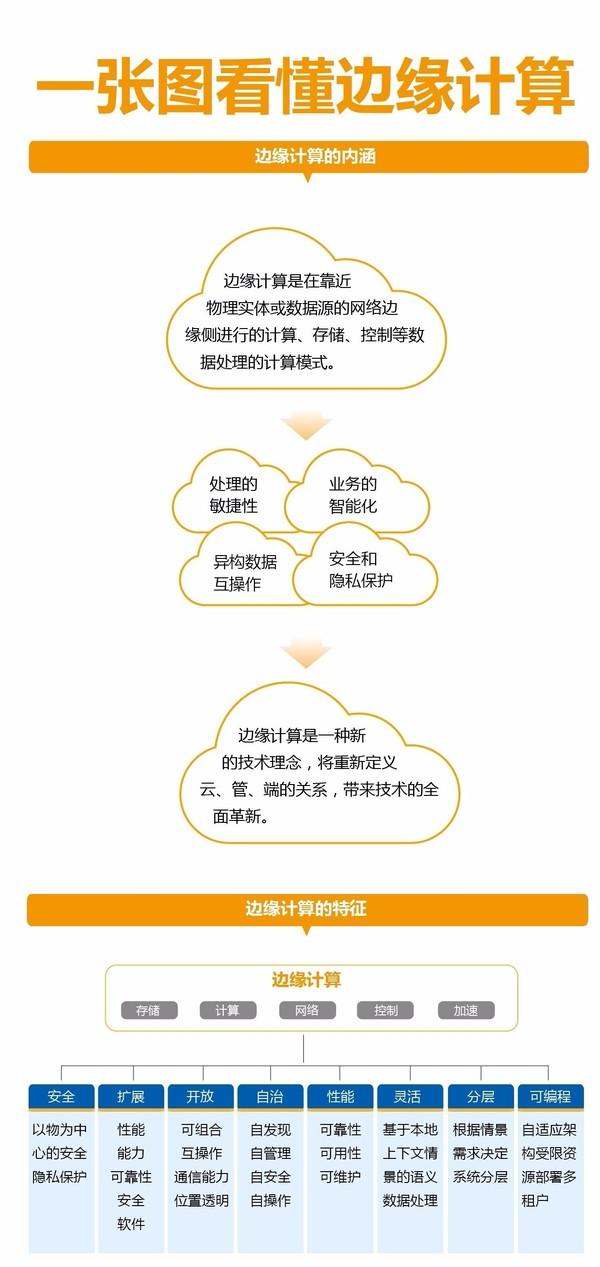



评论