 Rail-Only拓扑与PCI Switch:GPU集群间高效通信的核心逻辑
Rail-Only拓扑与PCI Switch:GPU集群间高效通信的核心逻辑

当前AI推理面临两大核心矛盾
算力需求激增:大模型应用爆发(如实时交互、多模态生成),企业亟需更低延迟、更高吞吐的推理能力;
资源浪费严重:传统架构下,GPU算力闲置率超30%,长文本处理场景首Token延迟飙升至秒级,用户体验流失率增加40%。
DeepSeek-V3/R1的给我们的启示:混合专家模型(MoE)虽需320卡起步,却为超大规模云计算厂商提供了差异化竞争力——吞吐效率提升50%,单用户推理成本降低20%。而对中小客户,“高性价比”仍是刚需,Dense模型凭借灵活部署稳占80%市场份额。
组网架构的“黄金分割”
行业需求驱动架构革新
分离架构:适合头部云厂商(如AWS、阿里云),通过独立优化Prefill(算力密集型)和Decode(带宽密集型)集群,实现超大规模并发下的极致性能,客户可溢价30%提供“高端推理服务”。
统一架构:中小厂商的“降本利器”——单网络支持智能流量调度,硬件投资减少25%,运维成本降低40%,兼容80%现有基础设施,快速抢占中端市场。
采用星融元CX-N系列交换机+RoCEv2技术,单设备支持400G/800G带宽,满足“既要大吞吐又要低延迟”的矛盾需求。
从实验室到生产线:组网设计的成本与效益平衡
Rail-Only拓扑:4 GPU/组共享PCIe链路,服务器内直连减少跳数,适合百卡以下集群,硬件成本降低30%。
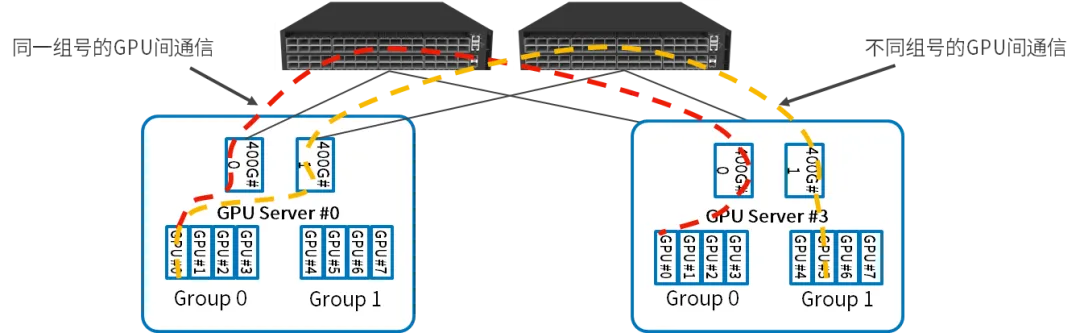
GPU服务器内部:每四个GPU作为一组,共享一个并行推理网卡,连接到同一个PCI Switch,两组GPU之间的通信通过两个PCI Switch之间的直连通道完成;
GPU服务器之间:同一组号的GPU之间的通信通过交换机直接完成;不同组号的GPU之间的通信,先通过PCI Swtitch将流量路由到另一组的网卡,然后通过交换机完成;
小规模场景:低成本敏捷部署
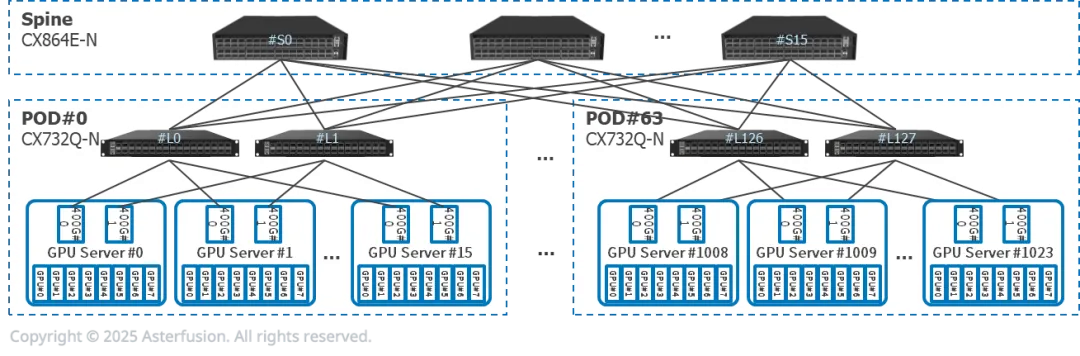
每台推理服务器有8张GPU,2张400G网卡,双归连接到两台CX732Q-N
16个推理服务器(128张GPU)和2个CX732Q-N组成一个PoD。Prefill和Decode服务器可能属于不同PoD
可横向扩展至64个PoD
中大规模场景:性能与扩展性优先
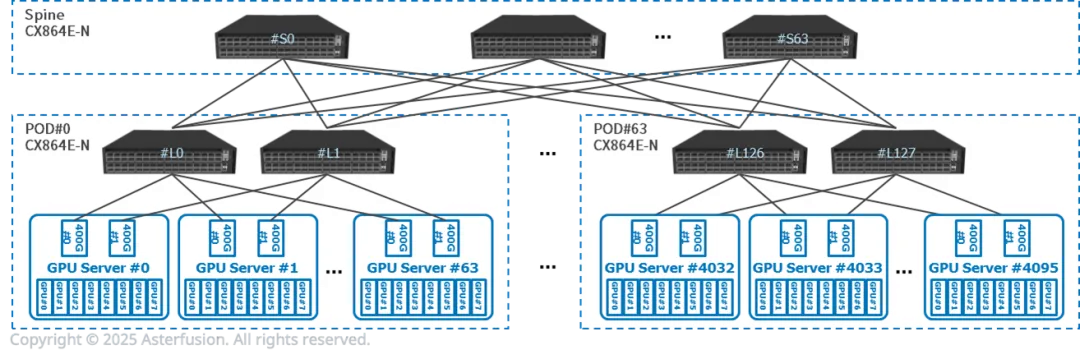
模块化PoD设计:以512 GPU为单元构建独立集群,Prefill与Decode服务器同PoD内一跳互联,时延控制在10μs以内。
横向扩展能力:可横向扩展至64个PoD,支持万卡级集群无缝扩容,满足云计算平台弹性需求。
未来展望:开放生态与硬件迭代的双重助力
尽管DeepSeek尚未开源,但其PD分离架构为行业提供了关键思路。未来趋势将围绕两大方向:
软硬件协同优化:如DPU卸载KV缓存传输任务,进一步释放GPU算力;
边缘AI轻量化:通过模型剪枝与专用推理芯片,在10卡以下环境中实现MoE模型部署。
【参考文献】
https://asterfusion.com/a20250306-scale-out/
审核编辑 黄宇
-
gpu
+关注
关注
28文章
5351浏览量
136348 -
PCI
+关注
关注
5文章
690浏览量
134726 -
AI
+关注
关注
91文章
42579浏览量
303494 -
组网
+关注
关注
1文章
465浏览量
23452
发布评论请先 登录
高性能串口通信卡:PCI - 1620与PCI - 1622
工业串口通信利器:研华PCI系列通信卡深度剖析
Java并发编程的“基石”——多线程概念初识
面向高密度算力需求的AI渲染服务器集群功率MOSFET选型策略与器件适配手册

深入剖析PI7C9X2G304EL:PCI Express Gen 2 Packet Switch的卓越之选
PI7C9X130:PCI Express与PCI - X的高效桥梁
KubePi:开源Kubernetes可视化管理面板,让集群管理如此简单
读懂高效通信的星型组网
全球迈入 IPv6-Only 关键窗口期

PPEC Workbench 平台拓扑全覆盖,满足各类电源开发需求

怎样确定分布式光伏集群通信网络的负载均衡策略?

睿海光电以高效交付与广泛兼容助力AI数据中心800G光模块升级
摩尔线程吴庆详解 MUSA 软件栈:以技术创新释放 KUAE 集群潜能,引领 GPU 计算新高度




评论