 NVIDIA大语言模型在推荐系统中的应用实践
NVIDIA大语言模型在推荐系统中的应用实践

生成式推荐系统优势
推荐系统的主要任务在于根据用户的过往行为预测其潜在兴趣点,并据此推荐相应的商品。在传统的推荐系统中,当处理用户请求时,会触发多个召回模块,例如热门商品召回、个性化召回以及深度召回等,从而召回大量候选商品。之后,系统会借助相对简单的粗排模型对这些候选集进行初步筛选,以缩小候选范围,最后通过精排和重排模型,确定最终返回给用户的推荐结果。
随着大语言模型 (LLM) 在推荐系统中的广泛应用,生成式推荐系统相较于传统推荐系统可展现出以下显著优势:
推荐流程的简化:生成式推荐系统从多级过滤的判别式 (discriminative-based) 架构转变成单级过滤的生成式 (generative-based) 架构。通过直接生成推荐结果,大幅简化了推荐流程,显著降低了系统复杂性。
知识融合:LLM 具备更强的泛化能力和稳定性。借助其丰富的世界知识和推理能力,生成式推荐系统可以突破传统电商平台在商品和用户建模时面临的数据局限。在新用户、新商品的冷启动以及新领域的推荐场景中,生成式推荐系统可以提供更优质的推荐效果和更出色的迁移性能。
规模定律(Scaling Law):传统的点击率 (CTR) 稀疏模型在模型规模扩大时,往往会面临边际收益递减的问题。而 LLM 所表现出的规模定律属性,为模型的有效扩展提供了一种新路径,即模型性能随着规模的增加而持续提升。这意味着通过扩大模型规模,可以获得更优的推荐效果,从而突破传统模型的性能瓶颈。
以下是基于京东广告场景落地的生成式召回应用,介绍大语言模型在推荐系统中的实践。
生成式召回方案介绍
1. 生成式召回算法与实现步骤
生成式推荐包含两个接地 (grounding) 过程:一是将商品与自然语言连接起来。二是将用户行为与目标商品连接起来。具体实现步骤如下:
商品表示:直接生成文档或商品描述在实际中几乎是不可行的。因此采用短文本序列(即语义 ID)来表征商品。选取高点击商品的标题、类目等语义信息,经由编码器模型获得向量表示,再利用 RQ-VAE 对向量进行残差量化,最终得到商品的语义 ID。例如,商品:“XXX 品牌 14+ 2024 14.5 英寸轻薄本 AI 全能本高性能独显商务办公笔记本电脑”可表示为:
用户画像与行为建模:通过构建提示词来定义任务,并将用户画像、用户历史行为数据等用户相关信息转化为文本序列。例如:“用户按时间顺序点击过这些商品:
模型训练:确定生成模型的输入(用户表示)和输出(商品物料标识符)后,即可基于生成式 Next Token Prediction 任务进行模型训练。
模型推理:经过训练后,生成模型能够接收用户信息并预测相应的商品语义 ID,这些语义标识可以对应数据集中的实际商品 ID。
2. LLM 模型部署的工程适配
传统基于深度学习的召回模型,参数量通常在几十万到几千万之间,且模型结构以 Embedding 层为主。而基于 LLM 实现的生成式召回模型,参数规模大幅提升至 0.5B 至 7B 之间,模型结构主要由 Dense 网络构成。由于参数量显著增加,LLM 在推理过程中所需的计算资源相比于传统模型大幅提升,通常高出几十倍甚至上百倍。因此,LLM 在处理复杂任务时具备更强的表现力,但同时也对计算能力有着更高的要求。
为了将如此庞大的算力模型部署至线上环境,并确保其满足毫秒级实时响应的需求,同时在严格控制资源成本的前提下实现工业化应用,我们必须对在线推理架构进行极致的性能优化。
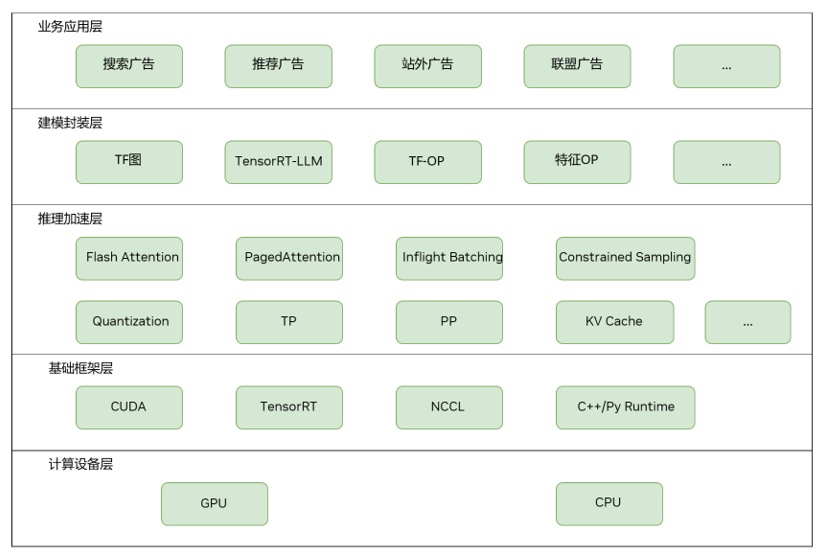
图 1: 在线推理架构
该图片来源于京东,若您有任何疑问或需要使用该图片,请联系京东
3. 基于 TensorRT-LLM 的 LLM构建优化及系统部署
在建模封装层,通过TensorRT-LLM实现 LLM 模型的构建与优化,并将其无缝整合到现有生态系统中,利用 Python 与 TensorFlow API 构建端到端推理图。基于 TensorFlow 原生算子及现有业务的自定义 TensorFlow 算子库(例如用户行为特征处理算子),实现算法的灵活建模。
在推理优化层,通过应用 Inflight Batching、Constrained Sampling、Flash Attention 及 Paged Attention 等加速方案,最大化提升单卡吞吐量并降低推理延迟。
在系统部署方面,为了最大程度利用时间资源,生成式召回一期的部署采用了与传统多分支召回模块并行的方式。由于简化了推理流程,相较于传统召回方式,生成式召回的资源消耗更少,运行时间更短,并且召回效果更优。
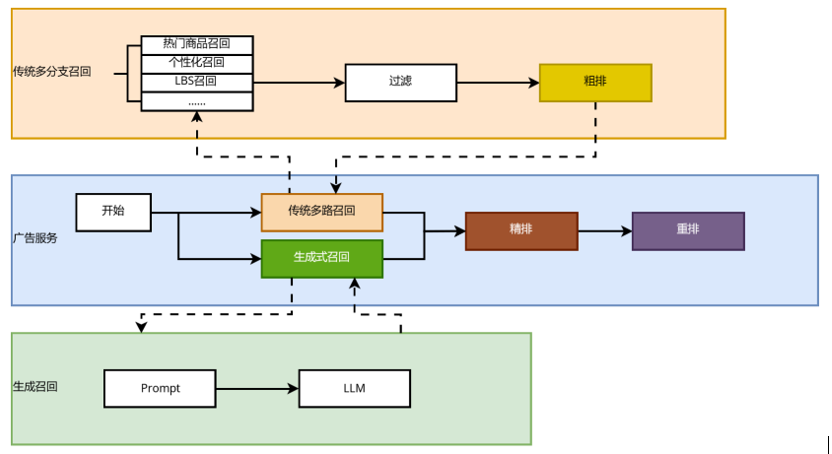
图 2:生成式召回与传统多路召回并行
该图片来源于京东,若您有任何疑问或需要使用该图片,请联系京东
4. 生成式召回一期
在推荐广告及搜索广告的成功应用
目前,生成式召回一期已在京东推荐广告及搜索广告等主要业务线成功实施。在推荐广告方面,基于生成式模型的参数规模及语义理解优势,AB 实验结果显示商品点击率与消费得到了显著提升。在搜索广告方面,LLM 所具备的语义理解能力显著提升了对查询与商品的认知能力,尤其是在处理搜索中的长尾查询时,填充率有明显提升,AB 实验也取得了点击率与消费几个百分点的收益增长。
通过 TensorRT-LLM 进行推理优化加速:
降低延迟并提升吞吐
在原先的模型推理方案中,线上业务的低延迟要求往往较难达成。然而,在切换到 TensorRT-LLM 之后,借助其丰富的优化特性,不仅模型推理延迟达到线上业务要求,同时吞吐也有了显著提升。
在 NVIDIA GPU 上进行的测试显示,与基线对比,在限制 100 毫秒推理耗时的广告场景下,采用 TensorRT-LLM 进行推理的吞吐量提升了五倍以上。这相当于将部署成本降至原来的五分之一。
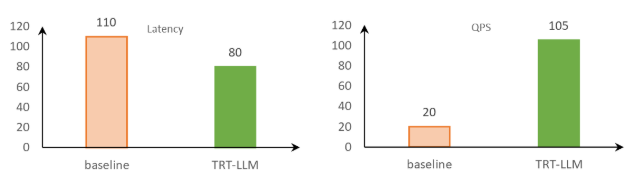
图 3:TensorRT-LLM 和基线的对比 (Qwen2-1.5B | beam 5 | vocab size 15W | input 150 | output 4) ,数据来自京东广告团队测试结果
该图片来源于京东,若您有任何疑问或需要使用该图片,请联系京东
针对这个特定的应用场景,合理配置 beam width 对检索结果有着重要影响。一般来说,较高的 beam width 能够增加候选商品的数量,从而提高检索的准确性。例如,在需要返回 300 个商品时,若 beam width 设置较低,每个 code 就需要对应更多的商品 id,这无疑会导致检索的精度降低。
为了解决这个问题,NVIDIA DevTech 技术团队进行了有针对性的二次开发和优化工作,从而让 TensorRT-LLM 支持更大范围的 beam width,及时满足了线上的业务需求。
持续优化技术以实现模型效率效果提升
未来,我们将持续在生成式推荐领域深入探索,重点聚焦以下几个方向:
提升模型规模以满足实时推理需求
目前,由于算力、时间消耗和成本等客观条件的限制,生成式推荐系统在实时推理中的可部署模型规模相对较小(约 0.5B 至 6B 参数之间)。然而,离线实验的数据表明,扩大模型规模可以显著提升线上推荐效果。这意味着对在线性能优化提出了更高要求。为了支持更大规模的模型在线部署,同时不显著增加成本,我们需要进一步优化模型结构和推理效率。例如,采用模型剪枝、量化等模型压缩技术,优化采样检索算法效率,以及高效的分布式推理架构。
扩展用户行为输入以提升模型效果
实验表明,输入更长的用户历史行为序列能够显著提高模型的推荐效果,但同时也会增加计算资源消耗和推理时间。因此,我们需要在效果提升和性能开销之间找到平衡。优化方案包括:
a. Token 序列压缩:对输入序列进行压缩(例如去除冗余信息、合并相似行为等),减少序列长度,同时保留关键信息。
b. 用户行为 KV 缓存复用:在推理过程中,针对用户行为特征有序递增的特点,对长期行为进行离线计算并进行缓存,在线部分负责计算实时行为,从而避免重复计算,最大化利用算力,提高推理效率。
融合稀疏与稠密模型以实现联合推理
随着模型参数量的增加,我们可以将稀疏的传统 CTR 模型与稠密的 LLM 模型进行联合推理。稀疏模型擅长处理高维度的稀疏特征,计算效率高;而稠密模型可以捕获复杂的非线性特征和深层次的语义信息。通过对两者的优势进行融合,构建一个既高效又精确的推荐系统。
针对于稀疏训练场景, NVIDIA 可以提供DynamicEmb方案。DynamicEmb 是一个 Python 包,专门针对推荐系统提供稀疏训练方案,包括模型并行的 dynamic embedding 表和 embedding lookup 功能。
DynamicEmb 利用 HierarchicalKV 哈希表后端,将键值(特征-嵌入)对存储在 GPU 的高带宽内存 (HBM) 以及主机内存中,而 embedding lookup 部分则主要利用了 EMBark 论文中的部分算法。
-
NVIDIA
+关注
关注
14文章
5696浏览量
110120 -
模型
+关注
关注
1文章
3824浏览量
52276 -
推荐系统
+关注
关注
1文章
44浏览量
10473 -
LLM
+关注
关注
1文章
350浏览量
1394
原文标题:NVIDIA TensorRT-LLM 在推荐广告及搜索广告的生成式召回的加速实践
文章出处:【微信号:NVIDIA-Enterprise,微信公众号:NVIDIA英伟达企业解决方案】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
名单公布!【书籍评测活动NO.31】大语言模型:原理与工程实践
【大语言模型:原理与工程实践】探索《大语言模型原理与工程实践》
【大语言模型:原理与工程实践】大语言模型的基础技术
【大语言模型:原理与工程实践】大语言模型的预训练
【大语言模型:原理与工程实践】大语言模型的评测
【大语言模型:原理与工程实践】大语言模型的应用
大语言模型:原理与工程实践+初识2
在Ubuntu上使用Nvidia GPU训练模型
NVIDIA SWI UNETR模型在医疗中的应用

NVIDIA NeMo最新语言模型服务帮助开发者定制大规模语言模型
KT利用NVIDIA AI平台训练大型语言模型
现已公开发布!欢迎使用 NVIDIA TensorRT-LLM 优化大语言模型推理




评论