 华为、理想、特斯拉、商汤的世界模型是做什么用的
华为、理想、特斯拉、商汤的世界模型是做什么用的

最近世界模型(World Model)很火,甚至有人说世界模型是终极自动驾驶解决方案,实际上它只是端到端大模型的一种,和VLM没有本质区别。目前的研究基本都集中在用世界模型生成视频或其他连续时间序列上的可视化数据,再用这些视频训练传统或端到端的自动驾驶模型,几乎没有人研究直接用世界模型做自动驾驶的。即便是视频生成,也还是处于实验室的学术研究阶段。
图片来源:网络
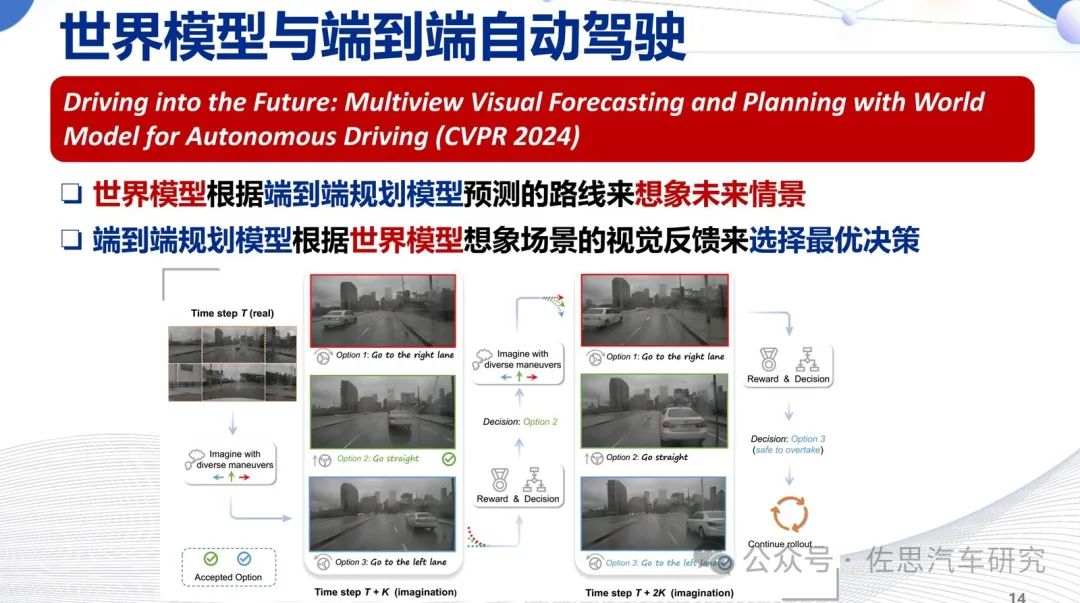
为什么要做世界模型,它实际上是端到端自动驾驶的闭环仿真,世界模型可以看做VLM的逆向工程,用prompt这些文字提示输出视频。世界模型和端到端模型是一个互相帮助的过程,世界模型生成的视频交给车端大模型,车端大模型通过它的规划执行接下来的动作,接下来的动作产生新的场景、新的视角,再通过世界模型继续生成新的数据,进行闭环仿真的测试。
图片来源:网络
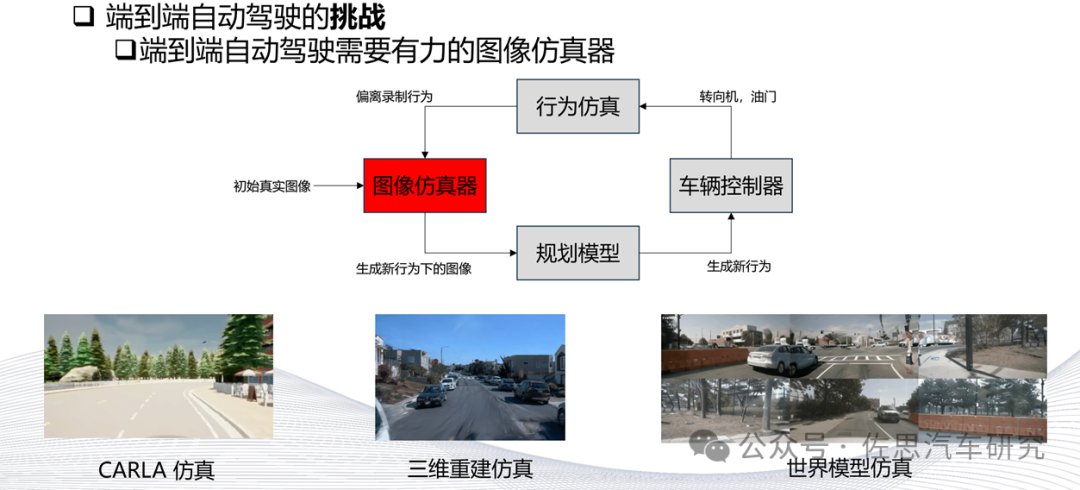
不同于CARLA这些测试型仿真,世界模型是训练型仿真,它要达到海量规模才有价值。
图片来源:网络
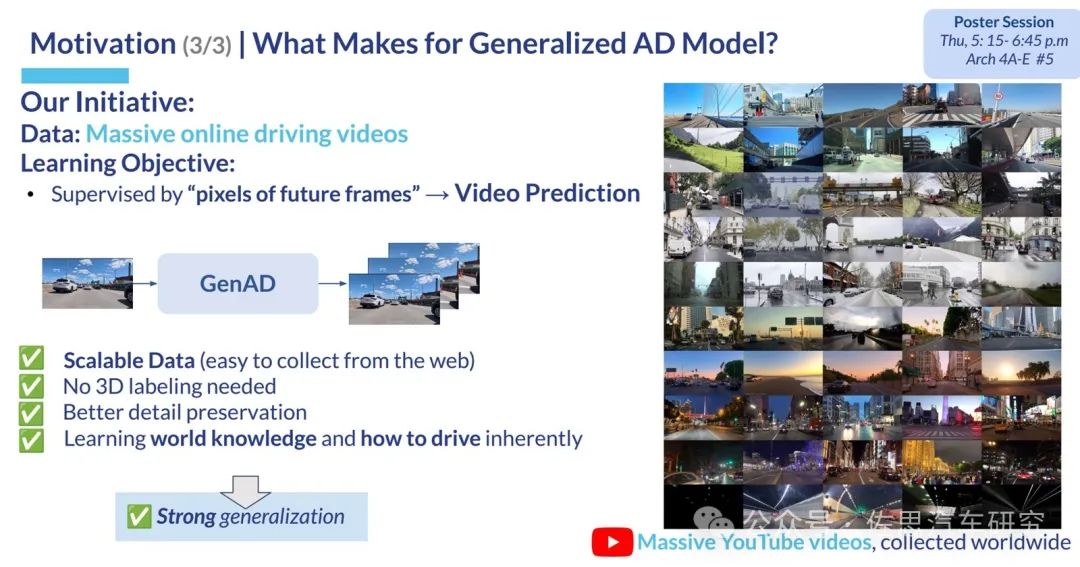
世界模型生成视频可以是自监督的,无需3D标签,可以使用海量网络汽车驾驶视频。最重要的是它可以生成现实世界中极难采集到的长尾视频,这是其核心价值。换句话说它生成的视频价值是现实世界采集到的视频数据的价值百倍以上,但成本是其1%不到。

图片来源:网络
所谓世界模型就是视频生成加prompt控制。视频生成有四大类型,包括基于对抗网络GAN的,基于扩散模型的,基于自回归模型(基本上就是transformer)和基于掩码的。其中,扩散模型再分为Stable Video Diffusion (SVD)和Stable Diffusion (SD)两种,它们还有一种共同的称呼即隐扩散模型(Latent Diffusion Model, LDM)。目前也有结合diffusion和transformer的模型即DiT,但它本质上还是扩散模型,只不过用transformer替换了扩散模型中的Unet。大名鼎鼎的SORA则是复合型,Sora模型的核心组成包括Diffusion Transformer(DiT)、Variational Autoencoder(VAE)和Vision Transformer(ViT)。DiT负责从噪声数据中恢复出原始的视频数据,VAE用于将视频数据压缩为潜在表示,而ViT则用于将视频帧转换为特征向量以供DiT处理。据说特斯拉就是用的SVD。
基于世界模型的端到端训练

图片来源:网络
生成视频的质量分为两部分,一是视频本身的准确度,主要指标有三个,一个是FID/FVD,另一个是CLIP得分。FID(Fréchet Inception Distance)是一种用于评估生成模型,尤其是在图像生成任务中,生成图像的质量和多样性的指标。它通过比较生成图像与真实图像在特定空间内的分布来工作。这个特定的空间通常是通过预训练的Inception网络的某一层来定义的。对于生成图像集和真实图像集,分别通过Inception网络(通常是Inception V3模型)计算它们的特征表示。这一步骤会得到每个图像集的特征向量,计算每个集合的特征向量的均值和协方差矩阵,并做对比,都是高等数学的课程,这里就不展开说了。FVD和FID接近,相当于把FID的图像特征提取网络换成视频特征提取网络,其他都差不多。最后一个是北大提出来的,就是Trajectory Agent IoU (NTA-IoU),与设定轨迹的交并比,Novel Trajectory Lane IoU (NTL-IoU),与设定车道的交并比。
二是视频本身的长度、帧率和分辨率,要尽可能与传统自动驾驶训练视频达到一致的帧率和分辨率。
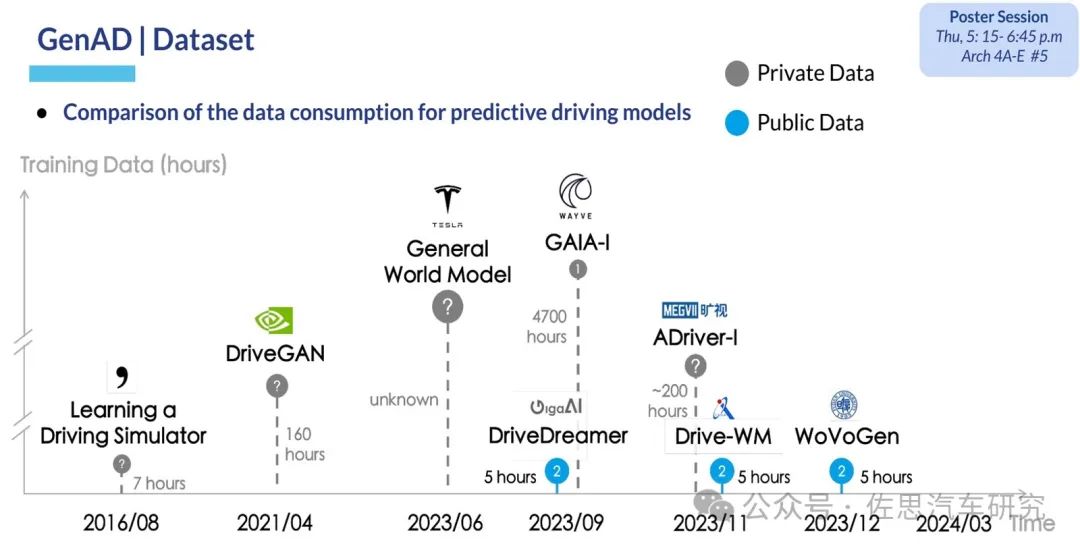
目前世界模型生成视频的方向有两个,一个是追求更长、更多视角、更高分辨率,代表作有商汤的《InfinityDrive: Breaking Time Limits in Driving World Models》,华为的《MagicDriveDiT: High-Resolution Long Video Generation》,Wayve的GAIA-1,地平线的DrivingWorld。另一个是追求近乎真实的3D场景渲染,理想在这方面情有独钟,理想的Street Gaussians、ReconDreamer、DriveDreamer4D都是这个方向,也是这个领域的主要代表作。
图片来源:网络
特斯拉用的什么世界模型,自然是未知,也许它根本就没用世界模型。
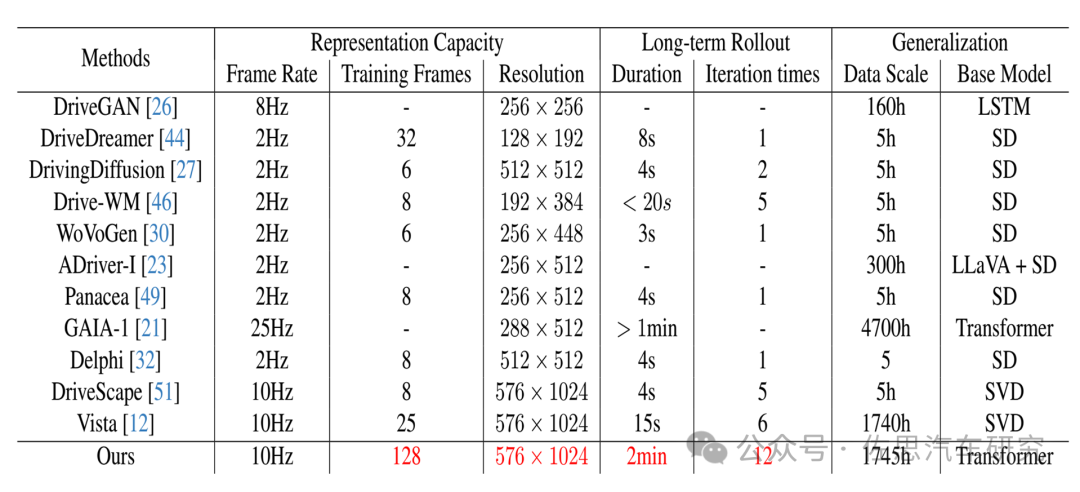
注:“Ours”指的就是InfinityDrive
图片来源:商汤论文《InfinityDrive: Breaking Time Limits in Driving World Models》

图片来源:华为的MagicDriveDiT
华为不仅能生成超高分辨率,还能生成多个角度的视频。
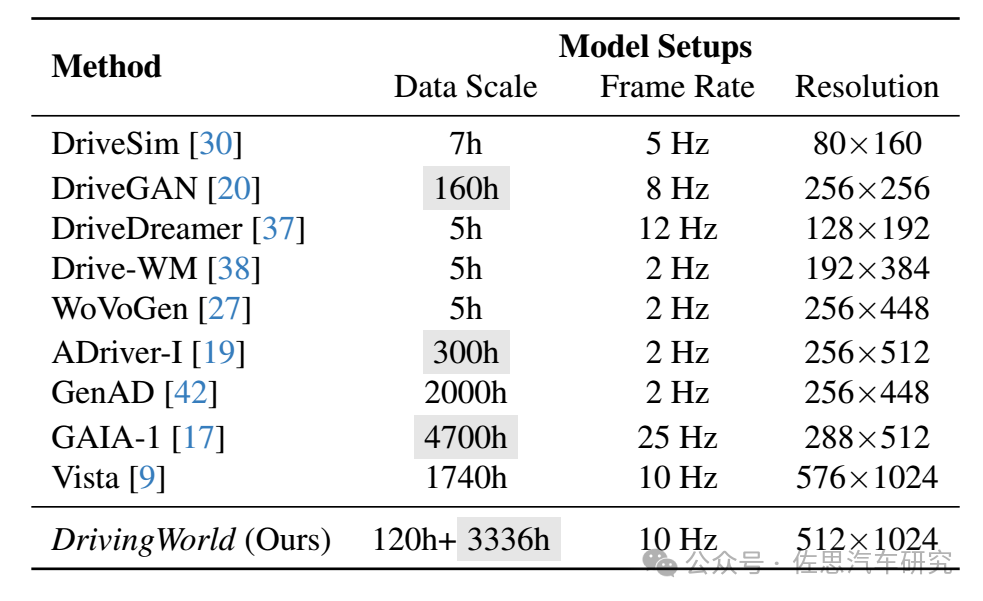
数据来源:地平线的DrivingWorld,数据尺度比较大,分辨率也很高
我们再来看另一条3D渲染线,它的核心应该说有点偏离世界模型的本来意义了,它是追求接近真实的3D渲染,基本上是理想汽车的独角戏。三个比较有价值的模型基本都有理想汽车的身影,第一个是Street Gaussians: Modeling Dynamic Urban Scenes with Gaussian Splatting,浙江大学和理想汽车合作,九位作者,其中来自理想汽车的作者占四位。第二个是DriveDreamer4D: World Models Are Effective Data Machines for 4D Driving Scene Representation,由极佳科技联合中国科学院自动化研究所、理想汽车、北京大学、慕尼黑工业大学等单位提出,十二位作者两位来自理想汽车。第三个是ReconDreamer: Crafting World Models for Driving Scene Reconstruction via Online Restoration,总共十六位作者,其中来自理想汽车的多达八位,来自极佳科技的有六位。
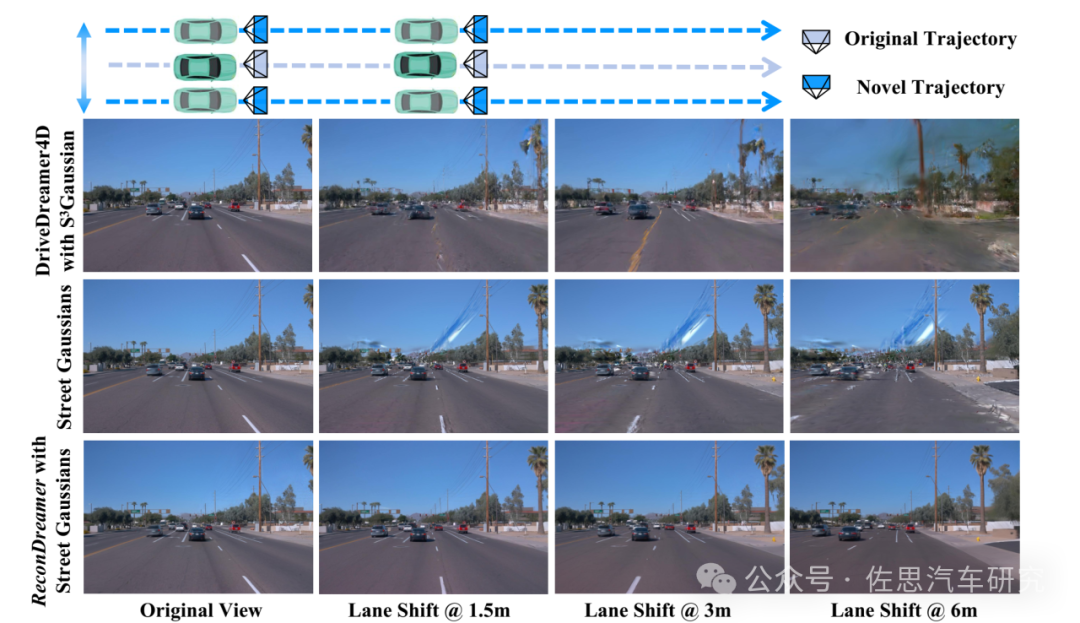
图片来源:论文《ReconDreamer: Crafting World Models for Driving Scene Reconstruction via Online Restoration》
上图可以看到,理想汽车与极佳科技合作的最新成果就是ReconDremaer,纯粹StreetGaussians的话,一旦偏离中心视角,容易出现空洞或鬼影,车道线也出现扭曲。
ReconDreamer整体框架

图片来源:论文《ReconDreamer: Crafting World Models for Driving Scene Reconstruction via Online Restoration》
除了生成视频,还有生成激光雷达点云视频,如理想与澳门大学合作的《OLiDM: Object-aware LiDAR Diffusion Models for Autonomous Driving》,还有生成语义分割图的《SynDiff-AD: Improving Semantic Segmentation and End-to-End Autonomous Driving with Synthetic Data from Latent Diffusion Models》。
OLiDM的整体框架
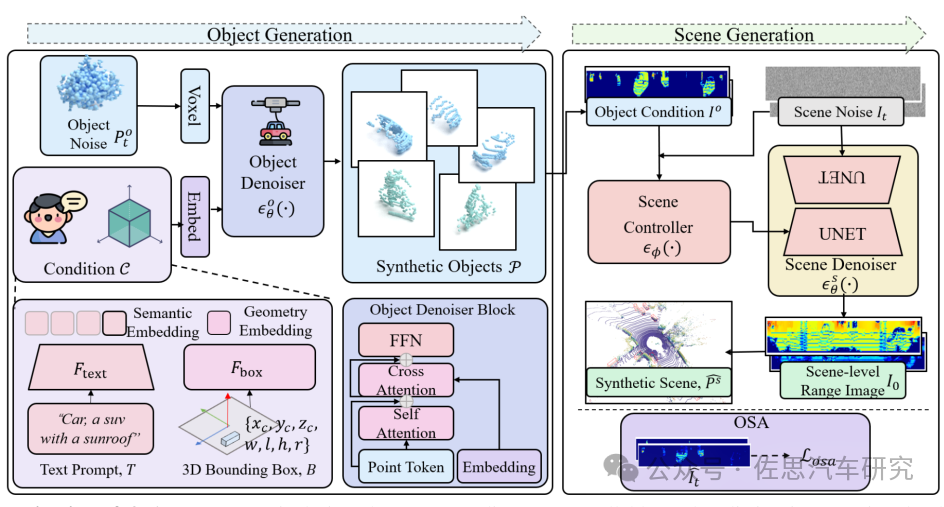
图片来源:论文《OLiDM: Object-aware LiDAR Diffusion Models for Autonomous Driving》
上图中,世界模型生成激光雷达点云视频,再拿这个去训练激光雷达的识别能力。
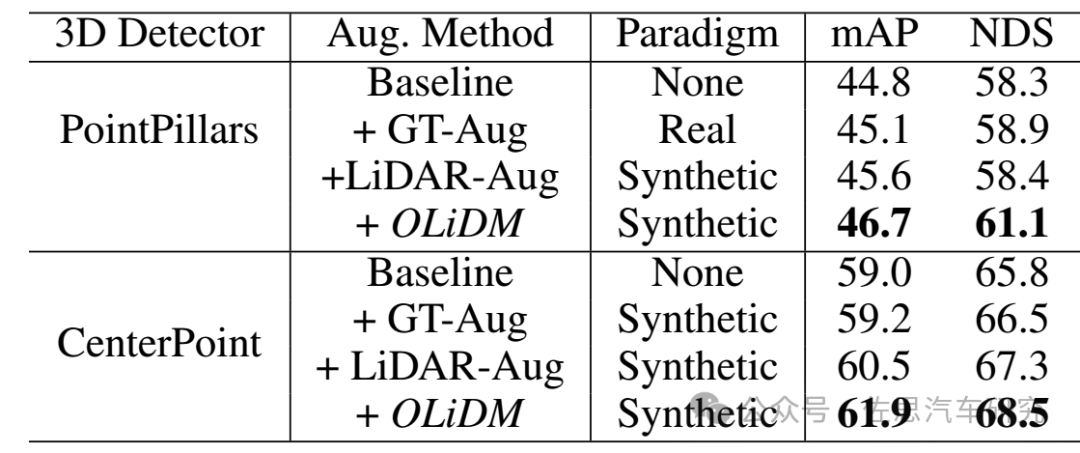
数据来源:论文《OLiDM: Object-aware LiDAR Diffusion Models for Autonomous Driving》。
OLiDM的效果,能有两三个点的提升,已经是非常难得了,现在在nuScenes上0.001的提升都需要一年半以上的时间。
世界模型一点也不神秘,不仅是端到端自动驾驶,它对传统自动驾驶也有明显的提升,自动驾驶的数据成本也大幅度下降至少95%以上,那些所谓影子模式变得毫无价值,实际上没有世界模型生成视频,影子模式本身也毫无价值,这也是马斯克说他用扩散模式生成视频的原因,如果影子模式真有价值,何必多此一举?
-
华为
+关注
关注
218文章
36284浏览量
262993 -
特斯拉
+关注
关注
66文章
6428浏览量
131567 -
商汤
+关注
关注
0文章
97浏览量
4439
原文标题:华为、理想、特斯拉、商汤的世界模型是做什么用的?
文章出处:【微信号:zuosiqiche,微信公众号:佐思汽车研究】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
商汤科技发布日日新SenseNova 6.7 Flash-Lite模型

昆仑芯科技完成商汤日日新SenseNova U1系列大模型极速适配
避繁就简!商汤日日新大模型灵性巧解数学难题,获赞“机器的审美”

商汤科技日日新Seko系列模型与寒武纪成功适配
商汤医疗以世界模型重塑智慧医疗未来图景
商汤科技正式发布并开源全新多模态模型架构NEO





评论