 亚马逊云科技AI Networking解决方案回顾
亚马逊云科技AI Networking解决方案回顾

前一段时间的2024 re:Invent 大会中,亚马逊云科技可谓是重磅连连,发布了全套最新AI networking基础设施方案。亚马逊云科技公用计算高级副总裁 Peter DeSantis 首先引用了一篇 2020 年的论文:“AI 场景中巨量的计算负载,并不能完全通过 Scale Out AI 集群来解决,同样也需要 Scale Up单台 AI 服务器的能力。” 基于这样的设计思想,Peter 推出了 Trainium2 Server 和 Trainium2 UltraServer。同时单个芯片性能对于集群的总效率也起到了重要的基础算力作用,本文主要回顾亚马逊最新的AI Networking片内/片间/网间综合解决方案。
Trainium2 服务器
Trainium2 和 Trainium2-Ultra 服务器的构建块就是我们所说的 Trainium2“物理服务器”。每个 Trainium2 物理服务器都有一个独特的架构,占用 18 个机架单元 (RU),由一个 2 机架单元 (2U) CPU 机头托盘组成,该托盘连接到八个 2U 计算托盘。在服务器的背面,所有计算托盘都使用类似于 GB200 NVL36 的无源铜背板连接在一起形成一个 4×4 2D 环面,不同之处在于,对于 GB200 NVL36,背板将每个 GPU 连接到多个 NVSwitches,而在 Trainium2 上,没有使用交换机,所有连接都只是两个加速器之间的点对点连接。
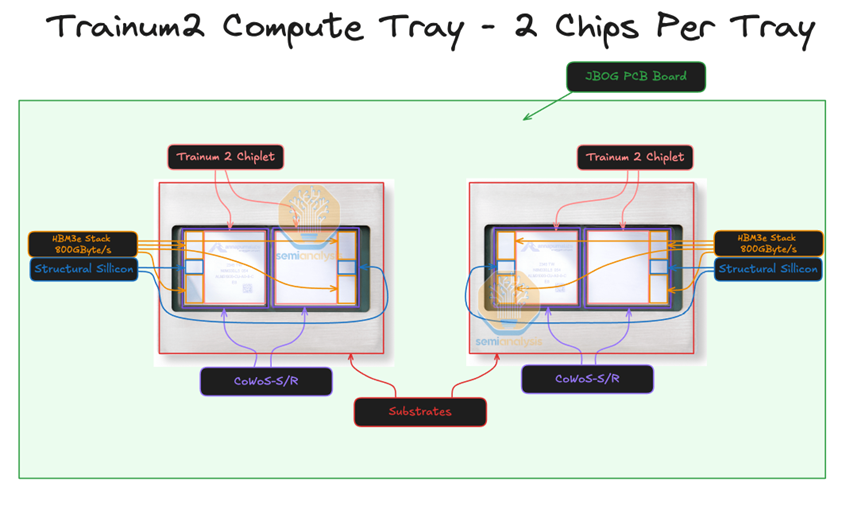
每个 2U 计算托盘有两个 Trainium 芯片,没有 CPU。这与 GB200 NVL72 架构不同,在 GB200 NVL72 架构中,每个计算托盘在同一个托盘中同时具有 CPU 和 GPU。每个 Trainium2 计算托盘通常也被称为 JBOG,即“只是一堆 GPU”,因为每个计算托盘没有任何 CPU,不能独立运行。
(来源:Semianalysis)
Scale Inside 单个芯片片内互联
Trainium2芯片
于 2023 年发布, Trainium2 采用了Multi-Die Chiplet架构,并使用CoWoS-S/R先进封装技术,将计算芯粒和(HBM)模块集成在一个紧凑的封装(Package)内。具体而言,每个 Trainium2 单卡内封装了 2 个 Trainium2 计算Die,而每个Die旁边都配备了 2 块 96GB HBM3 内存模块,提供高达 46TB/s 的带宽。目前没有提及Multi-die间的互联协议,暂且理解为私有协议。 这种先进的封装设计克服了芯片尺寸的工程极限,最大限度地缩小了计算和内存之间的距离,使用大量高带宽、低延迟的互联将它们连接在一起。这不仅降低了延迟,还能使用更高效的协议交换数据,提高了性能。
在计算核心方面,Trainium2 由少量大型 NeuronCore 组成,每个 NeuronCore 内部集成了张量引擎、矢量引擎、标量引擎和 GPSIMD 引擎,各司其职协同工作。这种设计思路与传统 GPGPU 使用大量较小张量核心形成鲜明对比,大型核心在处理 Gen AI 工作负载时能够有效减少控制开销。目前大模型参数量级常常到达数千亿甚至数万亿,Trainium2 是面向 AI 大模型的高性能训练芯片,与第一代 Trainium 芯片相比,Trainium2 训练速度提升至 4 倍,能够部署在多达 10 万个芯片的计算集群中,大幅降低了模型训练时间,同时能效提升多达 2 倍。
Scale Up超节点间互联
在竞争愈发激烈的 AI 大模型领域中,如何能够更高效的、更低成本的、更快速扩容满足算力需求的能力,就成为了赢得市场的关键之一。正如亚马逊云科技公用计算高级副总裁 Peter 所言:“在推动前沿模型的发展的进程中,对于极为苛刻的人工智能工作负载来说,再强大的计算能力也永远不够。”Scale Up 所带来的好处就是为大模型训练提供了更大的训练成功率、更高效的梯度数据汇聚与同步、更低的能源损耗。基于 Trainium2 UltraServer 支撑的 Amazon EC2 Trn2 UltraServer 可以提供高达 83.2 FP8 PetaFLOPS 的性能以及 6TB 的 HBM3 内存,峰值带宽达到 185 TB/s,并借助 12.8 Tb/s EFA(Elastic Fabric Adapter)网络进行互连。让 AI 工程师能够考虑在单台 64 卡一体机内以更短的时间训练出更加复杂、更加精准的 AI 模型。
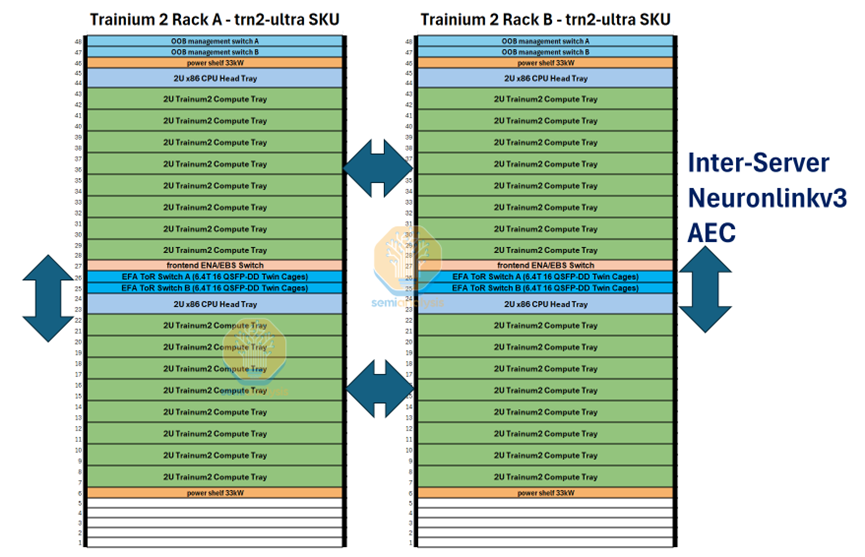
AWS Scale Up也是一个超节点的HBD域, 其机架互联结构和NVL36类似,由2个机架紧密耦合组成。一个机架32个GPU计算卡,超节点HBD域共64个GPU计算卡互联。Scale Up超节点是业界目前正在积极探索的领域,尽管生态存在技术路径的差异,但基于开放协议的技术路径将是未来GPU互联的关键,也是国内未来构建更大规模、更高效率集群的必经之路。
(来源:Semianalysis)
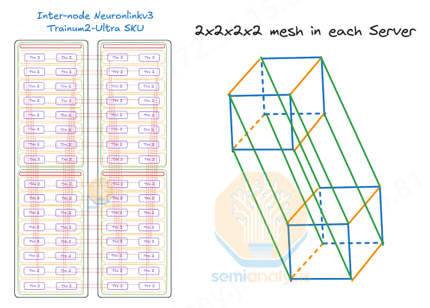
Trn2-Ultra SKU 由每个纵向扩展域的 4 个 16 芯片物理服务器组成,因此每个纵向扩展域由 64 个芯片组成,由两个机架组成,其配置类似于 GB200 NVL36x2。为了沿 z 轴形成圆环,每个物理服务器都使用一组有源铜缆连接到其他两个物理服务器。
NeuronLink 私有协议构成TB级互联
Trainium2 UltraServer 一定要提及的就是 NeuronLink,它是一种亚马逊云科技专有的网络互联技术,可使多台 Trainium2 Server 连接起来,成为一台逻辑上的服务器。我们可以理解Neuronlink和NVlink类似是一种基于私有的GPU/xPU片间通信协议。
NeuronLink 技术可以让 Trainium2 Server 之间直接访问彼此的内存,并提供每秒 2 TB 的带宽(高于目前的NVlink),延迟仅为 1 微秒。NeuronLink 技术使得多台 Trainium2 Server 就像是一台超级计算机一样工作,故称之为 “UltraServer”。“这正是训练万亿级参数的大型人工智能模型所需要的超级计算平台,非常强大!” Peter 介绍道。
(来源:Semianalysis)
Scale Out 十万卡集群网间互联
在 Scale Out 层面,亚马逊云科技正在与 Anthropic 合作部署 Rainier 项目,Anthropic 联合创始人兼首席计算官 Tom Brown 宣布下一代 Claude 模型将在 Project Rainier 上训练。Rainier 项目是一个庞大的 AI 超级计算集群,包含数十万个 Trainium2 芯片,预计可提供约 130 FP8 ExaFLOPS 的超强性能,运算能力是以往集群的 5 倍多,将为 Anthropic 的下一代 Claude AI 模型提供支持。Rainier 项目将会帮助 Anthropic 的客户可以用更低价格、更快速度使用到更高智能的 Claude AI 大模型服务。
(来源:Semianalysis)
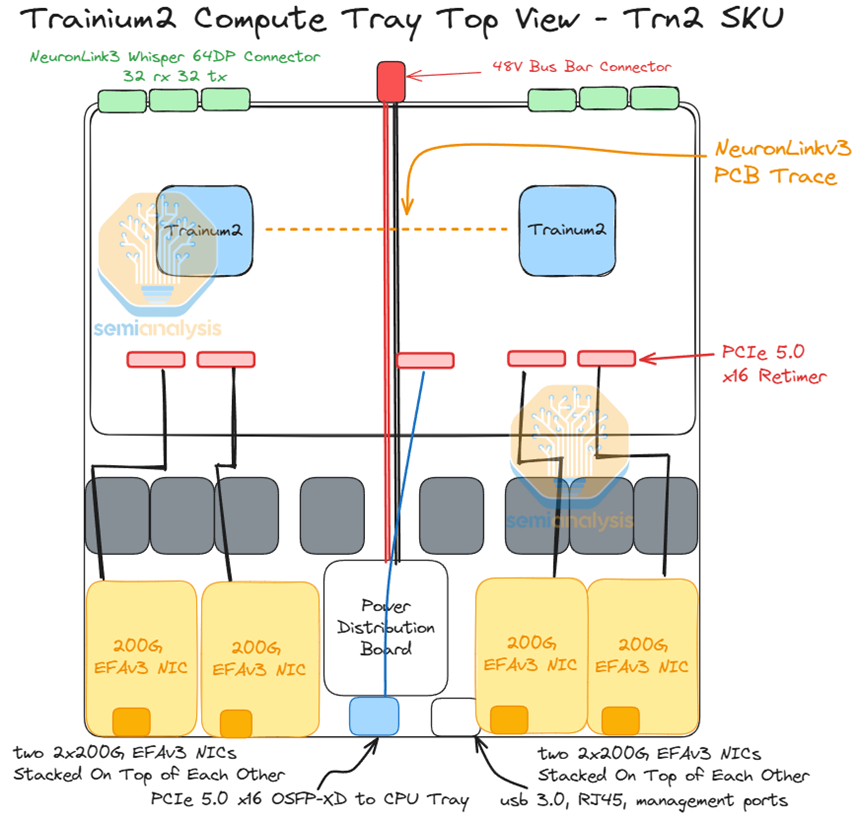
对于 Trn2,每个计算托盘最多有 8 个 200G EFAv3 NIC网卡,每个横向扩展以太网芯片可提供高达 800Gbit/s 的速度。从计算托盘连接到 CPU 托盘的笼子也需要一个重定时器。计算托盘左侧的 Trainium2 芯片将使用与 CPU 托盘连接的前 8 个通道,而右侧的 Trainium2 芯片将使用连接到 CPU 托盘的最后 8 个通道。
对于 Leaf 和 Spine 交换机,AWS 将使用基于 Broadcom Tomahawk4的 1U 25.6T 白盒交换机。AWS 不使用多个交换机来组成基于机箱的模块化交换机,因为这种设置的爆炸半径很大。如果机箱发生故障,则机箱连接的所有线卡和链路都会发生故障。这可能涉及数百个 Trainium2 芯片。
Front End 前端网络
我们提及一下连接传统以太网的前端网络,亚马逊使用的Nitro 芯片作为世界上最早发布的 DPU 之一,其旨在实现 Network、Storage、Hypervisor、Security 等虚拟化技术方面的 Workload offloading,消除了传统虚拟化技术对 CPU 资源的性能开销。同时还集成了多种功能,包括 Security Root 信任根、内存保护、安全监控等,以此来加强 Amazon EC2 实例的高性能和高安全性。安全性以及加密功能对于云计算中心的多租户网络安全至关重要。我们在之前的一期Kiwi Talks有讲述智能网卡与DPU在应用上的主要区别,亚马逊的前端网络案例可以让我们更清楚的了解两者在应用上的不同
用于AI网络Scale Out的智能网卡作为更轻量级的硬件多用于网络加速,与交换机等组件共同完成拥塞控制、自适应理由、选择性重传等系列AI网络传输问题。SmartNIC和DPU的技术路径存在显著不同。
在 2024 re:Invent 中,我们看到亚马逊云将 Nitro DPU 与 Graviton CPU 之间的 PCIe 链路都进行了加密,创建了一个相互锁定的信任网络,使 CPU 到 CPU、CPU 到 DPU 的所有连接都由硬件提供安全保护。
写在最后,全球主流超大规模云厂商已经成功搭建万卡集群并朝着十万卡集群目标迈进。但碍于生态壁垒,部分厂商还基于私有协议在构建自有网络体系。与此同时,国内的万卡集群在异构芯片调度、软硬件打通、超节点HBD域构建等方面仍然面临挑战,未来人工智能网络还有很长一段路要走,还有待行业积极拥抱开源开放的协议与物理接口,以实现更紧密的协同发展。
关于我们AI网络全栈式互联架构产品及解决方案提供商
奇异摩尔,成立于2021年初,是一家行业领先的AI网络全栈式互联产品及解决方案提供商。公司依托于先进的高性能RDMA 和Chiplet技术,创新性地构建了统一互联架构——Kiwi Fabric,专为超大规模AI计算平台量身打造,以满足其对高性能互联的严苛需求。我们的产品线丰富而全面,涵盖了面向不同层次互联需求的关键产品,如面向北向Scale out网络的AI原生智能网卡、面向南向Scale up网络的GPU片间互联芯粒、以及面向芯片内算力扩展的2.5D/3D IO Die和UCIe Die2Die IP等。这些产品共同构成了全链路互联解决方案,为AI计算提供了坚实的支撑。
奇异摩尔的核心团队汇聚了来自全球半导体行业巨头如NXP、Intel、Broadcom等公司的精英,他们凭借丰富的AI互联产品研发和管理经验,致力于推动技术创新和业务发展。团队拥有超过50个高性能网络及Chiplet量产项目的经验,为公司的产品和服务提供了强有力的技术保障。我们的使命是支持一个更具创造力的芯世界,愿景是让计算变得简单。奇异摩尔以创新为驱动力,技术探索新场景,生态构建新的半导体格局,为高性能AI计算奠定稳固的基石。
-
gpu
+关注
关注
28文章
5352浏览量
136366 -
服务器
+关注
关注
14文章
10487浏览量
91961 -
AI
+关注
关注
91文章
42612浏览量
303530 -
亚马逊
+关注
关注
8文章
2748浏览量
85978
原文标题:十万卡集群的必经之路:亚马逊云科技AI Networking片内/片间/网间互联解决方案回顾
文章出处:【微信号:奇异摩尔,微信公众号:奇异摩尔】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
云边云科技受邀出席 2026 亚马逊云科技中国合作伙伴峰会

亚马逊云科技发布桌面AI助手Amazon Quick,打通应用与数据壁垒
亚马逊云科技×OpenAI深化合作:以“三重有限预览”重构企业级AI开发新范式
中科创达与Alexa及亚马逊云科技深化全球合作
亚马逊云科技、阿里云、火山引擎等全球AI伙伴齐聚,涂鸦智能开发者大会共话AI应用生态!

易点天下选择亚马逊云科技 以Agentic AI驱动营销智能化升级
中科创达携手亚马逊云科技推出端云一体化边缘AI解决方案
Proteintech选择亚马逊云科技为首选云服务商,构建行业首个AI抗体助手加速科研创新
亚马逊云科技推出全新的Amazon AI Factories 将客户现有基础设施转化为高性能AI环境
奇异摩尔Networking for AI生态沙龙成功举办
亚马逊云科技AI联赛:在全新终极AI对决中学习、创新和竞争
亚马逊云科技在2025纽约峰会发布多项AI agent创新

软通动力携手华为云推出AI知识引擎与数据工程融合创新解决方案
Agentic AI再竖里程碑,这次引爆革命的还是亚马逊云科技




评论