 一文理解多模态大语言模型——下
一文理解多模态大语言模型——下

作者:Sebastian Raschka 博士,
翻译:张晶,Linux Fundation APAC Open Source Evangelist
编者按:本文并不是逐字逐句翻译,而是以更有利于中文读者理解的目标,做了删减、重构和意译,并替换了多张不适合中文读者的示意图。
原文地址:https://magazine.sebastianraschka.com/p/understanding-multimodal-llms
《一文理解多模态大语言模型 - 上》介绍了什么是多模态大语言模型,以及构建多模态 LLM 有两种主要方式之一:统一嵌入解码器架构(Unified Embedding Decoder Architecture)。本文将接着介绍第二种构建多模态 LLM 的方式:跨模态注意架构(Cross-modality Attention Architecture approach)。
一,跨模态注意架构
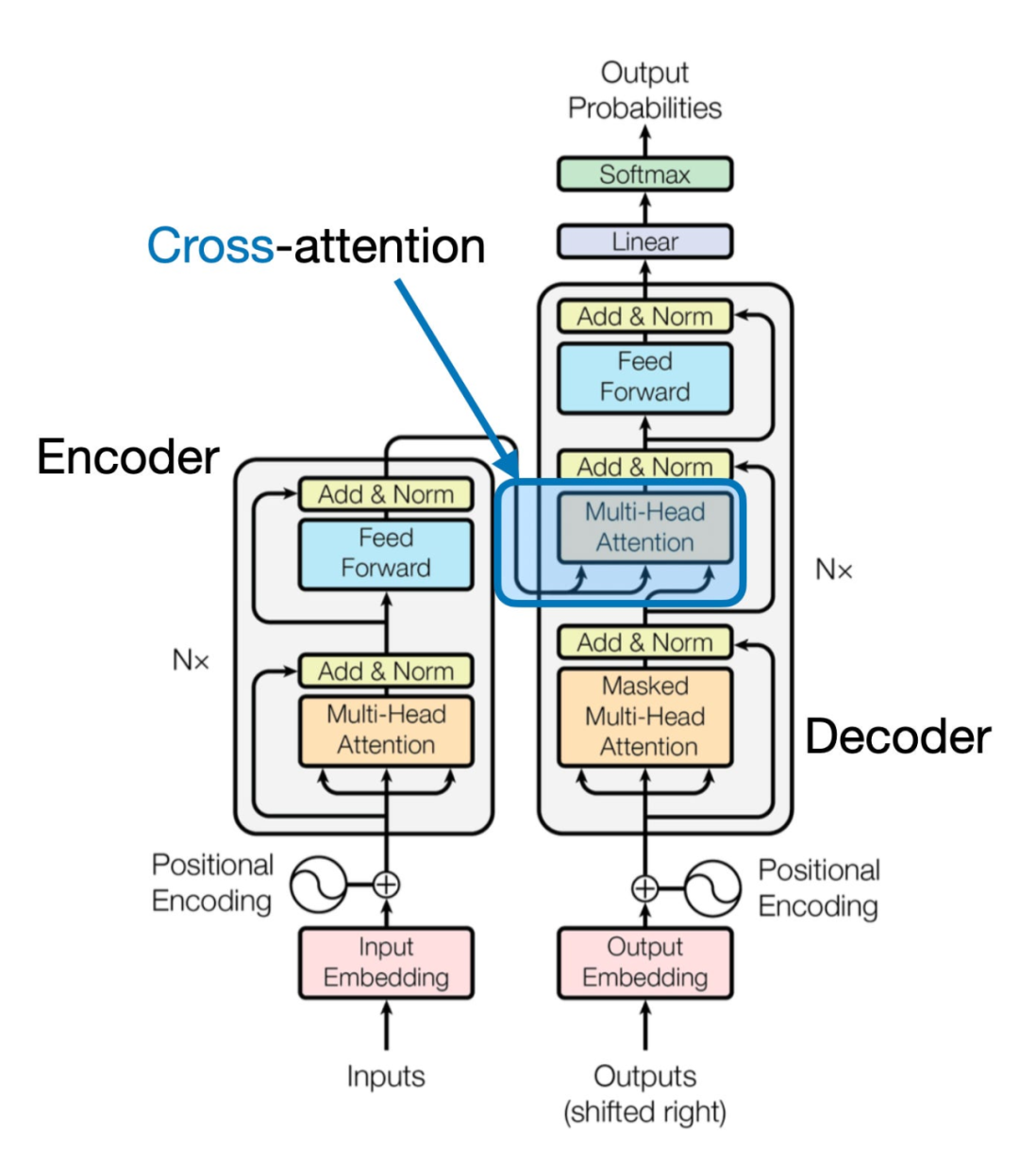
《一文理解多模态大语言模型 - 上》讨论了通过统一嵌入解码器架构来构建多模态大语言模型(LLM)的方法,并且理解了图像编码背后的基本概念,下面介绍另一种通过交叉注意力机制实现多模态LLM的方式,如下图所示:

在上图所示的跨模态注意力架构方法中,我们仍然使用之前介绍的图像向量化方式。然而,与直接将图像向量作为LLM的输入不同,我们通过交叉注意力机制在多头注意力层中连接输入的图像向量。
这个想法与2017年《Attention Is All You Need》论文中提出的原始Transformer架构相似,在原始《Attention Is All You Need》论文中的Transformer最初是为语言翻译开发的。因此,它由一个文本编码器(下图的左部分)组成,该编码器接收要翻译的句子,并通过一个文本解码器(图的右部分)生成翻译结果。在多模态大语言模型的背景下,图的右部分的编码器由之前的文本编码器,更换为图像编码器(图像编码后的向量)。
文本和图像在进入大语言模型前都编码为嵌入维度和尺寸(embedding dimensions and size)一致的向量。
“我们可以把多模态大语言模型看成“翻译”文本和图像,或文本和其它模态数据 --- 译者。”
二,统一解码器和交叉注意力模型训练
与传统仅文本的大语言模型(LLM)的开发类似,多模态大语言模型的训练也包含两个阶段:预训练和指令微调。然而,与从零开始不同,多模态大语言模型的训练通常以一个预训练过且已经过指令微调的大语言模型作为基础模型。
对于图像编码器,通常使用CLIP,并且在整个训练过程中往往保持不变,尽管也存在例外,我们稍后会探讨这一点。在预训练阶段,保持大语言模型部分冻结也是常见的做法,只专注于训练投影器(Projector)——一个线性层或小型多层感知器。鉴于投影器的学习能力有限,通常只包含一两层,因此在多模态指令微调(第二阶段)期间,大语言模型通常会被解冻,以允许进行更全面的更新。然而,需要注意的是,在基于交叉注意力机制的模型(方法B)中,交叉注意力层在整个训练过程中都是解冻的。
在介绍了两种主要方法(方法A:统一嵌入解码器架构和方法B:跨模态注意力架构)之后,你可能会好奇哪种方法更有效。答案取决于具体的权衡:
统一嵌入解码器架构(方法A)通常更容易实现,因为它不需要对LLM架构本身进行任何修改。
跨模态注意力架构(方法B)通常被认为在计算上更高效,因为它不会通过额外的图像分词(Token)来过载输入上下文,而是在后续的交叉注意力层中引入这些标记。此外,如果在训练过程中保持大语言模型参数冻结,这种方法还能保持原始大语言模型的仅文本性能。
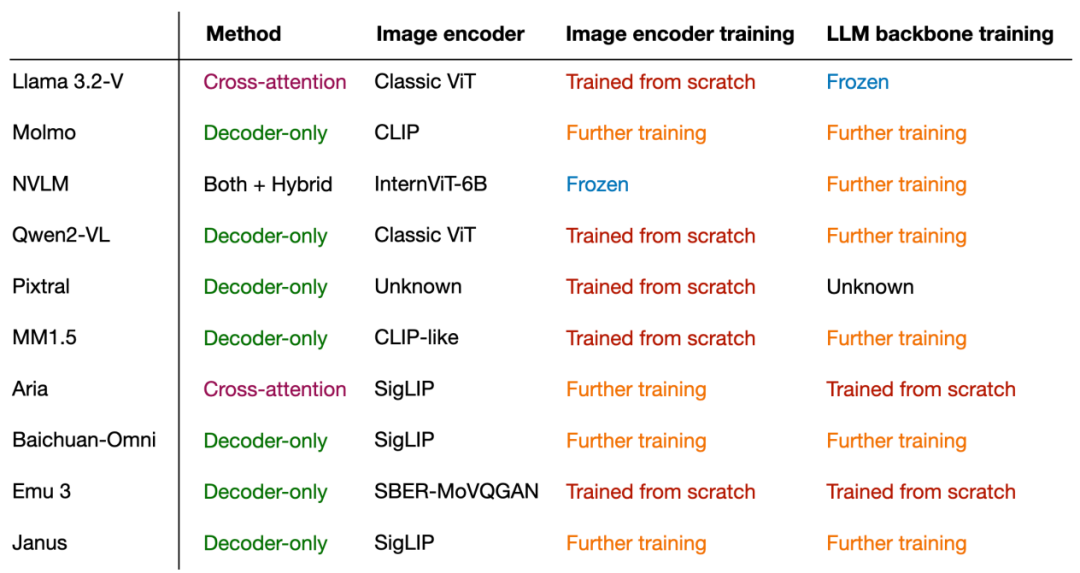
下图总结了常见多模态大语言模型使用的组件和技术:
三,总结
“多模态LLM可以通过多种不同的方式成功构建,核心思路在于把多模态数据编码为嵌入维度和尺寸一致的向量,使得原始大语言模型可以对多模态数据“理解并翻译”。--- 译者”。
如果你有更好的文章,欢迎投稿!
稿件接收邮箱:nami.liu@pasuntech.com
更多精彩内容请关注“算力魔方®”!
审核编辑 黄宇
-
语言模型
+关注
关注
0文章
575浏览量
11385 -
LLM
+关注
关注
1文章
352浏览量
1432
发布评论请先 登录
一文理解多模态大语言模型——上

《多模态大模型 前沿算法与实战应用 第一季》精品课程简介

更强更通用:智源「悟道3.0」Emu多模态大模型开源,在多模态序列中「补全一切」

中科大&字节提出UniDoc:统一的面向文字场景的多模态大模型
DreamLLM:多功能多模态大型语言模型,你的DreamLLM~

机器人基于开源的多模态语言视觉大模型

韩国Kakao宣布开发多模态大语言模型“蜜蜂”

商汤“日日新”融合大模型登顶大语言与多模态双榜单

格灵深瞳多模态大模型Glint-ME让图文互搜更精准




评论