 关于深度学习中的卷积神经网络系统的设计及硬件实现
关于深度学习中的卷积神经网络系统的设计及硬件实现

0 引言
随着深度学习的广泛应用与发展[1-2],卷积神经网络(Convolutional Neural Network,CNN)被使用的场景越来越多,特别是在图像识别场景中获得了突破性的发展。CNN拥有多层的神经网络结构,其自身拥有较强的容错、学习和并行处理能力[3],是一种拥有多层感知器,局部连接和权值共享的网络结构[4],从而降低了网络模型的复杂性和网络连接权值的个数,因此近几年来CNN在视频分析[5-6]、人脸识别[7-8]等领域得到了广泛的应用。
虽然CNN的应用广泛,但其模型参数的训练往往需要大量的用时,特别是当数据量很大的时候。在现阶段实现深度卷积神经网络主要是使用消费级的通用处理器CPU来实现的[9],但是在CNN的模型结构中,其每一层内的卷积运算都只与当前层的特征运算核相关,与其他层是独立且不相关的,所以CNN是一种典型的并行运算结构。而现场可编程门阵列(Field-Programmable Gate Array,FPGA)作为一种高度密集型计算加速器件,可通过硬件描述语言完成算法实现,从而利用FPGA的硬件结构特性实现并行运算的加速。
本文首先对深度学习中的CNN进行了介绍,然后设计一种基于FPGA的CNN系统,通过流水线和并行处理减少了训练参数所需用时,提升了系统的计算性能。为了验证设计的功能性,最后采用MINST数据集作为系统验证。
1 CNN
1.1 CNN模型
CNN是基于神经认知机模型(Neocognitron Model)的一种深度神经网络结构,是当前应用最为广泛的模型结构。CNN在确定模型参数时首先利用前向传播来获取和输出目标的误差,然后再通过高效的反向传播训练算法来实现参数的确定。一般经典的CNN模型是由输入层、卷积层、池化层、全连接层和分类层组合而构成的,在CNN中卷积层和不同的卷积核进行局部连接,从而产生输入数据的多个特征输出,将输出经过池化层降维后通过全连接层和分类层获取与输出目标的误差,再利用反向传播算法反复地更新CNN中相邻层神经元之间的连接权值,缩小与输出目标的误差,最终完成整个模型参数的训练。图1是一种典型的CNN网络结构,数据使用不同权重的卷积核Kernel经过卷积运算,将运算的结果经过激活函数ReLU后加上偏置Bias得到多个特征输出,然后经过池化进行层降维处理后再与全连接层进行全连接,最后经过分类器Softmax函数进行输出分类。
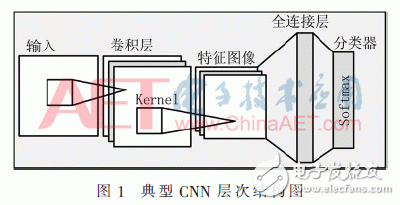
得到分类结果后,经过与输出目标进行比较得出误差,最后使用反向传播算法得出每一层的残差,利用残差计算出新的权值并更新原有的权值。以上整个过程可由式(1)和式(2)表示:

1.2 本文CNN模型
本文所设计的CNN网络模型结构如图2所示,该结构有1个输入层、4个卷积层、2个池化层、1个全连接层、1个采用Softmax函数的分类层和1个输出层,共8层。
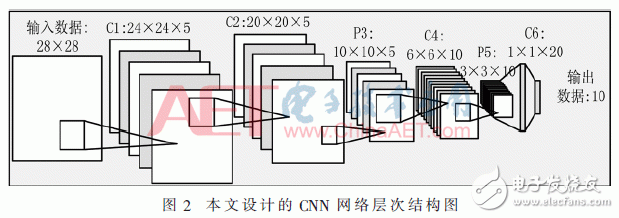
第1层和第8层为输入层和输出层。输入层完成测试图像数据的输入获取,因为采用MNIST数据集,所以输入数据为784个。输出层与前一层连接的权重个数为20×10=200,输出结果为10种。
第2、3、5、7层均为为卷积层。输出特征图的个数分别为5、5、10、20,每层卷积核大小分别为5×5,5×5,5×5,3×3,卷积核移动步长均为1,系统设计采用ReLU作为激活函数,每一层的参数为:
第2层:权重为5×5×5=125个,偏置为5个;
第3层:权重为5×5×5×5=625个,偏置为5个;
第5层:权重为5×5×5×10=1 250个,偏置为10个;
第7层:权重为3×3×10×20=1 800个,偏置为20个;因此整个卷积层总共有3 840个参数。
第4、6层为池化层。在池化层也采用卷积运算,卷积核大小为2×2,使用平均池化方法。
2 CNN系统硬件设计
整个系统硬件根据CNN网络结构进行设计,利用FPGA硬件电路并行特性将每一层设计为单独的一个模块,最后的分类层利用本文所设计的Softmax分类器来完成输入数据的分类结果,再经过反向传播算法计算出所需要更新的权值。整体系统设计结构如图3所示。
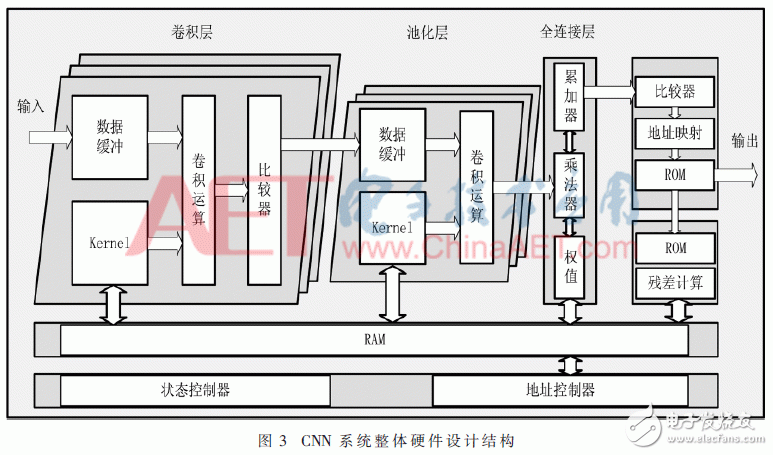
系统首先由控制器初始化每一层卷积核Kernel的权重数值索引地址,根据索引地址从RAM模块当中加载权重数值和偏置值。在前向传播时将输入数据通过输入信号进入数据缓冲区,然后根据每层的输出特征图的个数与卷积核完成卷积运算,将运算的结果经过激活函数ReLU和偏置完成当前层的最终输出特征图并输入下一层当中。当经过池化层时进行下采样运算,从而降低特征图的维数。最后Softmax分类器根据输入的数据通过查找ROM中与之对应的数值在经过概率转换后完成最终的输出结果。在反向传播时,根据ROM当中的标签与输出结果进行比较得出每一层的残差保存至RAM当中,计算完成后根据所设定的学习率来完成所有卷积层中卷积核的权值和偏置值的更新,并将更新后的权值由控制器保存到相应的存储位置,直至所有训练数据输入完成。
2.1 卷积层硬件设计
在图3的卷积层中,首先将输入数据进行缓存处理。因为要进行卷积运算,所以必须将输入的数据根据每个卷积层的卷积核Kernel的大小来进行与之相对应的大小调整。在系统设计中通过使用移位寄存器(Shift Register)来实现对数据的处理,移位寄存器能够将数据在进行缓存的同时进行移位处理,该器件能够根据所设定的深度来对数据进行转换处理,当需要数据进行输出的时候只需增加抽头输出信号即可将数据进行输出,利用移位寄存器就能够在1个时钟周期完成1次卷积运算。在计算出当前输入数据的特征输出图后还需经过激活函数,系统设计使用硬件容易实现的ReLU函数作为激活函数,该函数在输入值大于0时输出原输入值,小于零时输出0,因此使用比较器即可实现。其卷积运算具体实现过程如图4所示。
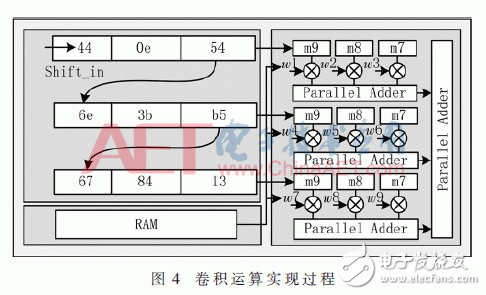
图4是卷积核大小为3×3时的运算过程,Shift_in是数据输入,wi为该卷积核权重值,mi为输出数据缓存寄存器。
2.2 卷积层计算硬件优化
由于FPGA硬件电路的并行特性,其当中每个模块的计算是相互独立互不相关的,并且CNN网络结构中每层的计算也是相互独立的,充分体现了整个结构的并行性,特别是卷积运算。因此系统设计中采用了并行设计的方法,设计根据卷积层上一层的输出特征图的个数和当前卷积层需要输出特征图的个数分别为每个特征图设计了相应的卷积核组,利用流水线技术和并行运算同时对每个卷积核组完成与之对应的特征抽取,因为系统设计中对池化层的下采样也采用了卷积运算来完成,所以对于本系统则能够在1个时钟周期内完成295次卷积运算,相较于通用CPU运算,本系统设计运算效率得到了显著提升。系统卷积运算优化设计具体结构如图5所示。
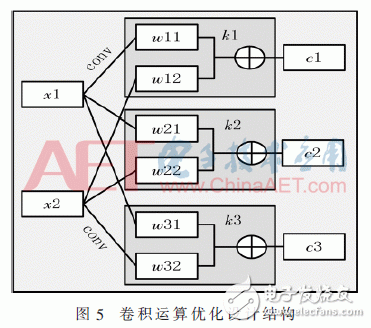
图5中xi为特征图输入,wij分别是每个卷积核组内不同卷积核的权值,ki为不同的卷积核组,ci为计算结果输出。
2.3 Softmax分类器
在经过多层的卷积层和池化层的运算后最终得到当前输入数据的特征值,将特征值与最后的输出层进行全连接得出最终的分类结果。系统设计中的分类器使用Softmax函数来完成最后结果的输出,但Softmax函数是将所有输入数据通过e指数运算进而得出输出概率分布,且概率分布的数值范围是0~1之间的浮点数,而FPGA并不适合进行浮点数运算,并且完成e指数运算所消耗时间较长。因此系统设计中采用查表法来完成e指数运算,通过事先将计算后的指数运算结果存储至ROM当中,然后根据输入的特征值作为地址来查找所对应的指数结果。经过软件平台测试,特征值经过放大后的取值范围是-70~80,范围较大,为了减少ROM的存储消耗,系统设计中将处理后的特征值计算的数值结果缩小至-30~40之间并进行取整处理,虽然该做法在一定程度上增强或减弱了对应特征值的比重,但降低了查表所需存储数值ROM的存储空间,减少了资源的消耗。Softmax分类器的设计电路结构图如图6所示。
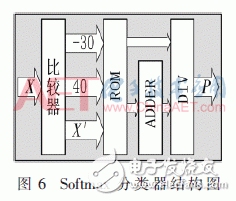
设计中首先将特征值输入经过查表得出对应指数运算的结果,同时将结果进行累加运算,最后相除从而计算出分类的结果。
3 系统仿真与分析
系统设计中的硬件使用Altera公司的Cyclone IV EP4CE115芯片作为试验平台,该芯片内部拥有114 480个逻辑单元,6.3 MB的嵌入式存储器,266个嵌入式18×18乘法器,片内资源丰富,能够满足CNN系统硬件设计中所需要的资源,CPU测试平台使用Core i7四核处理器,主频为3.4 GHz。
仿真过程中,整个CNN的学习率设置为0.04,每次输入批次为30张,迭代次数为2 000次,实验样本训练数据为MNIST数据集28×28像素的灰度图片60 000张,图像数值范围为0~255,测试数据为10 000张,使用均方误差函数作为损失函数来评价CNN整体系统的性能,最终实验运行结果如图7所示。
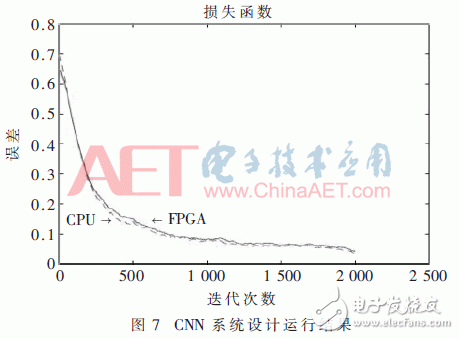
可以看出在硬件平台运行和软件平台运行均能够实现对结果的正确分类,在训练的最开始由于权重值是随机初始化的,因此误差较大,随着不断地迭代更新权值,误差逐渐降低,最后其对图像识别准确率分别为92.42%和96.21%,识别的准确率基本一致。硬件平台的准确度不如软件平台高,是由于在分类器中对Softmax函数的输入取值做了一定的限定,并在整个训练过程中进行了数据的放大处理和取整,损失了一定的精度。硬件平台的训练时间和软件平台训练所需的时间消耗如表1所示。

硬件平台整个训练所用时间相较于软件平台运算的时间提升了8.7倍,系统设计主要的硬件资源消耗如表2所示。

系统设计因为中使用了大量的移位寄存器和缓存寄存器来存储特征值的输入值,使得寄存器的使用较多,但可以看出实验所用使用的FPGA能够满足本文所设计的CNN网络结构。
4 结论
本文设计了一种深度学习中的CNN硬件系统,通过FPGA实现了整个CNN网络结构,充分利用了FPGA的硬件电路并行特性和流水线技术,对整个卷积层进行了并行运算优化,使得整个系统能够在1个时钟周期内同时处理所有卷积层中295次卷积运算,从而使得整个网络训练用时相较于通用CPU平台提升了8.7倍,减少了网络训练的所需用时,并且设计了一种通过查表法实现的Softmax分类器来完成对输出结果的分类。实验结果表明,该系统设计能够对MNIST测试数据集完成识别分类且识别准确率经过2 000次迭代后为92.42%,结果基本与相同训练次数下的CPU平台一致。
-
FPGA
+关注
关注
1664文章
22516浏览量
639693 -
神经网络
+关注
关注
42文章
4844浏览量
108218 -
cnn
+关注
关注
3文章
356浏览量
23563
发布评论请先 登录
详解深度学习、神经网络与卷积神经网络的应用




评论